淘宝Tprofiler工具实现分析
http://blog.csdn.net/y461517142/article/details/26269529
工具介绍
TProfiler是一个可以在生产环境长期使用的性能分析工具.它同时支持剖析和采样两种方式,记录方法执行的时间和次数,生成方法热点 对象创建热点 线程状态分析等数据,为查找系统性能瓶颈提供数据支持.TProfiler在JVM启动时把时间采集程序注入到字节码中,整个过程无需修改应用源码.运行时会把数据写到日志文件,一般情况下每小时输出的日志小于50M.
业界同类开源产品都不是针对大型Web应用设计的,对性能消耗较大不能长期使用,TProfiler解决了这个问题.目前TProfiler已应用于淘宝的核心Java前端系统.
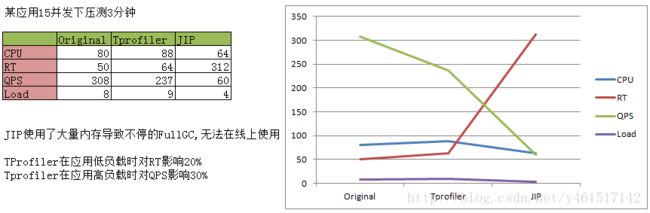
部署后低峰期对应用响应时间影响20% 高峰期对吞吐量大约有30%的降低(高峰期可以远程关闭此工具)
同类对比
| 与同类开源工具jip对比 | ||
|---|---|---|
| 项目 | TProfiler | JIP |
| 交互控制 |
支持远程开关和状态查看 |
支持远程开关等多种操作 |
| 过滤包和类名 |
支持包和类的过滤 |
支持包和类的过滤 |
| 低消耗 |
响应时间延长20% QPS降低30%(详细对比看上图) |
同等条件下资源消耗较多,使JVM不断的FullGC;Profile时会阻塞其他线程 |
| 无本地代码 |
未使用JVMTI,纯Java开发 |
未使用JVMTI,纯Java开发 |
| 易用性 |
只有一个jar包,使用简单 |
模块多,配置使用相对复杂 |
| 日志文件 |
对日志进行优化,每小时一般小于50M |
同等条件下日志大约是TProfiler的8倍,不能自动dump需要客户端触发 |
| 日志分析 |
目前只提供文本展示 |
可以利用客户端分析展示日志 |
| 使用场景 |
大型应用/小型应用 长期使用 |
小型应用 短期使用 |
TProfiler实现原理
字节码修改

运行实现原理
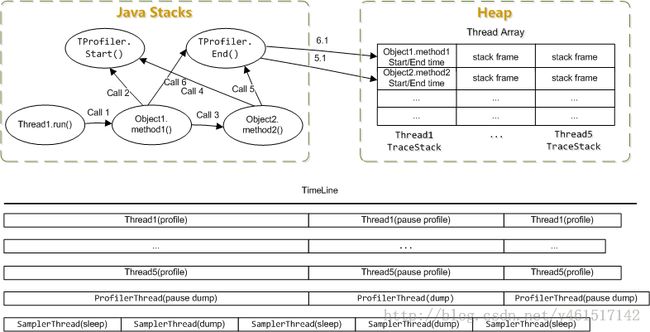
从图中可以看出,该工具使用了java6的Instrumention特性以及asm字节码修改
在 Java SE 6 里面,instrumentation 包被赋予了更强大的功能:启动后的 instrument、本地代码(native code)instrument,以及动态改变 classpath 等等。这些改变,意味着 Java 具有了更强的动态控制、解释能力,它使得 Java 语言变得更加灵活多变。
Instrumentation 的基本功能和用法
“java.lang.instrument”包的具体实现,依赖于 JVMTI。JVMTI(Java Virtual Machine Tool Interface)是一套由 Java 虚拟机提供的,为 JVM 相关的工具提供的本地编程接口集合。JVMTI 是从 Java SE 5 开始引入,整合和取代了以前使用的 Java Virtual Machine Profiler Interface (JVMPI) 和 the Java Virtual Machine Debug Interface (JVMDI),而在 Java SE 6 中,JVMPI 和 JVMDI 已经消失了。JVMTI 提供了一套”代理”程序机制,可以支持第三方工具程序以代理的方式连接和访问 JVM,并利用 JVMTI 提供的丰富的编程接口,完成很多跟 JVM 相关的功能。事实上,java.lang.instrument 包的实现,也就是基于这种机制的:在 Instrumentation 的实现当中,存在一个 JVMTI 的代理程序,通过调用 JVMTI 当中 Java 类相关的函数来完成 Java 类的动态操作。除开 Instrumentation 功能外,JVMTI 还在虚拟机内存管理,线程控制,方法和变量操作等等方面提供了大量有价值的函数。关于 JVMTI 的详细信息,请参考 Java SE 6 文档(请参见 参考资源)当中的介绍。
Instrumentation 的最大作用,就是类定义动态改变和操作。在 Java SE 5 及其后续版本当中,开发者可以在一个普通 Java 程序(带有 main 函数的 Java 类)运行时,通过 – javaagent参数指定一个特定的 jar 文件(包含 Instrumentation 代理)来启动 Instrumentation 的代理程序。
在 Java SE 5 当中,开发者可以让 Instrumentation 代理在 main 函数运行前执行。简要说来就是如下几个步骤:
1:编写 premain 函数
Instrumentation 简介
利用 Java 代码,即 java.lang.instrument 做动态 Instrumentation 是 Java SE 5 的新特性,它把 Java 的 instrument 功能从本地代码中解放出来,使之可以用 Java 代码的方式解决问题。使用 Instrumentation,开发者可以构建一个独立于应用程序的代理程序(Agent),用来监测和协助运行在 JVM 上的程序,甚至能够替换和修改某些类的定义。有了这样的功能,开发者就可以实现更为灵活的运行时虚拟机监控和 Java 类操作了,这样的特性实际上提供了一种虚拟机级别支持的 AOP 实现方式,使得开发者无需对 JDK 做任何升级和改动,就可以实现某些 AOP 的功能了。在 Java SE 6 里面,instrumentation 包被赋予了更强大的功能:启动后的 instrument、本地代码(native code)instrument,以及动态改变 classpath 等等。这些改变,意味着 Java 具有了更强的动态控制、解释能力,它使得 Java 语言变得更加灵活多变。
Instrumentation 的基本功能和用法
“java.lang.instrument”包的具体实现,依赖于 JVMTI。JVMTI(Java Virtual Machine Tool Interface)是一套由 Java 虚拟机提供的,为 JVM 相关的工具提供的本地编程接口集合。JVMTI 是从 Java SE 5 开始引入,整合和取代了以前使用的 Java Virtual Machine Profiler Interface (JVMPI) 和 the Java Virtual Machine Debug Interface (JVMDI),而在 Java SE 6 中,JVMPI 和 JVMDI 已经消失了。JVMTI 提供了一套”代理”程序机制,可以支持第三方工具程序以代理的方式连接和访问 JVM,并利用 JVMTI 提供的丰富的编程接口,完成很多跟 JVM 相关的功能。事实上,java.lang.instrument 包的实现,也就是基于这种机制的:在 Instrumentation 的实现当中,存在一个 JVMTI 的代理程序,通过调用 JVMTI 当中 Java 类相关的函数来完成 Java 类的动态操作。除开 Instrumentation 功能外,JVMTI 还在虚拟机内存管理,线程控制,方法和变量操作等等方面提供了大量有价值的函数。关于 JVMTI 的详细信息,请参考 Java SE 6 文档(请参见 参考资源)当中的介绍。
Instrumentation 的最大作用,就是类定义动态改变和操作。在 Java SE 5 及其后续版本当中,开发者可以在一个普通 Java 程序(带有 main 函数的 Java 类)运行时,通过 – javaagent参数指定一个特定的 jar 文件(包含 Instrumentation 代理)来启动 Instrumentation 的代理程序。
在 Java SE 5 当中,开发者可以让 Instrumentation 代理在 main 函数运行前执行。简要说来就是如下几个步骤:
1:编写 premain 函数
- public static void premain(String agentArgs, Instrumentation inst); [1]
- public static void premain(String agentArgs); [2]
在这个 premain 函数中,开发者可以进行对类的各种操作。
agentArgs 是 premain 函数得到的程序参数,随同 “– javaagent”一起传入。与 main 函数不同的是,这个参数是一个字符串而不是一个字符串数组,如果程序参数有多个,程序将自行解析这个字符串。
Inst 是一个 java.lang.instrument.Instrumentation 的实例,由 JVM 自动传入。java.lang.instrument.Instrumentation 是 instrument 包中定义的一个接口,也是这个包的核心部分,集中了其中几乎所有的功能方法,例如类定义的转换和操作等等。
jar 文件打包
2:将这个 Java 类打包成一个 jar 文件,并在其中的 manifest 属性当中加入” Premain-Class”来指定步骤 1 当中编写的那个带有 premain 的 Java 类。(可能还需要指定其他属性以开启更多功能)
2:将这个 Java 类打包成一个 jar 文件,并在其中的 manifest 属性当中加入” Premain-Class”来指定步骤 1 当中编写的那个带有 premain 的 Java 类。(可能还需要指定其他属性以开启更多功能)
3:运行
用如下方式运行带有 Instrumentation 的 Java 程序:
用如下方式运行带有 Instrumentation 的 Java 程序:
- <span style="font-family:SimSun;font-size:14px;">java -javaagent:jar 文件的位置 [= 传入 premain 的参数 ]</span>
Tprofiler就是通过这种方式来对字节码进行修改的。
首先假设我们有一个类HelloWorld, 可以通过一个方法打印字符串。
- public HelloWorld{
- public void sayHello(){
- System.out.println("hello world!");
- }
- }
我们需要记录方法执行的时间和次数需要如何实现?
ProfTransformer是Tprofiler自定义的ClassFileTransformer,用于转换类字节码
- public class ProfTransformer implements ClassFileTransformer {
- public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined,
- ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {
- if (loader != null && ProfFilter.isNotNeedInjectClassLoader(loader.getClass().getName())) {
- return classfileBuffer;
- }
- if (!ProfFilter.isNeedInject(className)) {
- return classfileBuffer;
- }
- if (ProfFilter.isNotNeedInject(className)) {
- return classfileBuffer;
- }
- if (Manager.instance().isDebugMode()) {
- System.out.println(" ---- TProfiler Debug: ClassLoader:" + loader + " ---- class: " + className);
- }
- // 记录注入类数
- Profiler.instrumentClassCount.getAndIncrement();
- try {
- ClassReader reader = new ClassReader(classfileBuffer);
- ClassWriter writer = new ClassWriter(ClassWriter.COMPUTE_MAXS);
- ClassAdapter adapter = new ProfClassAdapter(writer, className);
- reader.accept(adapter, 0);
- // 生成新类字节码
- return writer.toByteArray();
- } catch (Exception e) {
- e.printStackTrace();
- // 返回旧类字节码
- return classfileBuffer;
- }
- }
- }
在代码中我们可以看到两个类ClassReader和ClassWriter这两个ASM的字节码操作API,通过他们我们可以对原来的class进行增加行为。
(ASM是一个操作字节码(bytecode)的框架,非常的小巧和快速,这个asm-3.3.1.jar,只有43k的大小。asm提供了字节码的读写的功能。而asm的核心,采用的是visitor的模式,提供了ClassReader和ClassWriter这两个非常重要的类以及ClassVisitor这个核心的接口。)
ASM框架中的核心类有以下几个:
ClassReader:该类用来解析编译过的class字节码文件。ClassWriter:该类用来重新构建编译后的类,比如说修改类名、属性以及方法,甚至可以生成新的类的字节码文件。
ClassAdapter:该类也实现了ClassVisitor接口,它将对它的方法调用委托给另一个ClassVisitor对象。
ClassReader的职责是读取字节码。可以用InputStream、byte数组、类名(需要ClassLoader.getSystemResourceAsStream能够加载到的class文件)作为构造函数的参数构造ClassReader对象,来读取字节码。而ClassReader的工作,就是根据字节码的规范,从输入中读取bytecode。而通过ClassReader对象,获取bytecode信息有两种方式,一种就是采用visitor的模式,传入一个ClassVisitor对象给ClassReader的accept方法。另外一种,是使用Low Level的方式,使用ClassReader提供了readXXX以及getXXX的方法来获取信息。对于一般使用,用ClassReader的accept方法,使用visitor模式就可以了。其中ProfClassAdapter继承了org.objectweb.asm.ClassAdapter。在asm中,ClassAdapter这个类,用asm的javadoc上的话说,就是一个代理到其他ClassVisitor的一个空的ClassVisitor(An empty ClassVisitor that delegates to another ClassVisitor.)。具体来说,构造ClassAdapter对象的时候,需要传递一个ClassVisitor的对象给ClassAdapter的构造函数,而ClassAdapter对ClassVisitor的实现,就是直接调用这个传给ClassAdapter的ClassVisitor对象的对应visit方法。ClassVisitor,在 ASM3.0 中是一个接口,到了 ASM4.0 与 ClassAdapter 抽象类合并。主要负责 “拜访” 类成员信息。其中包括(标记在类上的注解,类的构造方法,类的字段,类的方法,静态代码块)
这里主要介绍其中几个关键方法:
visit(int , int , String , String , String , String[])
该方法是当扫描类时第一个拜访的方法,主要用于类声明使用。下面是对方法中各个参数的示意:visit( 类版本 , 修饰符 , 类名 , 泛型信息 , 继承的父类 , 实现的接口)。
visitAnnotation(String , boolean)
该方法是当扫描器扫描到类注解声明时进行调用。下面是对方法中各个参数的示意:visitAnnotation(注解类型 , 注解是否可以在 JVM 中可见)。
visitField(int , String , String , String , Object)
该方法是当扫描器扫描到类中字段时进行调用。下面是对方法中各个参数的示意:visitField(修饰符 , 字段名 , 字段类型 , 泛型描述 , 默认值)。
visitMethod(int , String , String , String , String[])
该方法是当扫描器扫描到类的方法时进行调用。下面是对方法中各个参数的示意:visitMethod(修饰符 , 方法名 , 方法签名 , 泛型信息 , 抛出的异常)。
visitEnd()
该方法是当扫描器完成类扫描时才会调用,如果想在类中追加某些方法。可以在该方法中实现。在后续文章中我们会用到这个方法。
接下来我们看在ProfClassAdapter中做了些什么:
- public class ProfClassAdapter extends ClassAdapter {
- /**
- * 类名
- */
- private String mClassName;
- /**
- * 文件名
- */
- private String mFileName = null;
- /**
- * 字段对应方法列表
- */
- private List<String> fieldNameList = new ArrayList<String>();
- /* (non-Javadoc)
- * @see org.objectweb.asm.ClassAdapter#visit(int, int, java.lang.String, java.lang.String, java.lang.String, java.lang.String[])
- */
- public void visit(int version, int access, String name, String signature, String superName, String[] interfaces) {
- super.visit(version, access, name, signature, superName, interfaces);
- }
- /**
- * @param visitor
- * @param theClass
- */
- public ProfClassAdapter(ClassVisitor visitor, String theClass) {
- super(visitor);
- this.mClassName = theClass;
- }
- /* (non-Javadoc)
- * @see org.objectweb.asm.ClassAdapter#visitSource(java.lang.String, java.lang.String)
- */
- public void visitSource(final String source, final String debug) {
- super.visitSource(source, debug);
- mFileName = source;
- }
- /* (non-Javadoc)
- * @see org.objectweb.asm.ClassAdapter#visitField(int, java.lang.String, java.lang.String, java.lang.String, java.lang.Object)
- */
- public FieldVisitor visitField(int access, String name, String desc, String signature, Object value) {
- String up = name.substring(0, 1).toUpperCase() + name.substring(1, name.length());
- String getFieldName = "get" + up;
- String setFieldName = "set" + up;
- String isFieldName = "is" + up;
- fieldNameList.add(getFieldName);
- fieldNameList.add(setFieldName);
- fieldNameList.add(isFieldName);
- return super.visitField(access, name, desc, signature, value);
- }
- /* (non-Javadoc)
- * @see org.objectweb.asm.ClassAdapter#visitMethod(int, java.lang.String, java.lang.String, java.lang.String, java.lang.String[])
- */
- public MethodVisitor visitMethod(int arg, String name, String descriptor, String signature, String[] exceptions) {
- if (Manager.isIgnoreGetSetMethod()) {
- if (fieldNameList.contains(name)) {
- return super.visitMethod(arg, name, descriptor, signature, exceptions);
- }
- }
- // 静态区域不注入
- if ("<clinit>".equals(name)) {
- return super.visitMethod(arg, name, descriptor, signature, exceptions);
- }
- MethodVisitor mv = super.visitMethod(arg, name, descriptor, signature, exceptions);
- MethodAdapter ma = new ProfMethodAdapter(mv, mFileName, mClassName, name);
- return ma;
- }
- }
他主要重写visitField和visitMethod这两个方法,其中visitField中主要做的事情就是得到属性名称的get和set方法名称放入集合中,在visitMethod调用的时候先判断是否过滤get和set方法,不对他们进行增强操作。在执行MethodVisitor mv = super.visitMethod(arg, name, descriptor, signature, exceptions);会获得MethodVisitor对象,通过这个对象可以对方法访问进行AOP的代码注入。
- public class ProfMethodAdapter extends MethodAdapter {
- /**
- * 方法ID
- */
- private int mMethodId = 0;
- /**
- * @param visitor
- * @param fileName
- * @param className
- * @param methodName
- */
- public ProfMethodAdapter(MethodVisitor visitor, String fileName, String className, String methodName) {
- super(visitor);
- mMethodId = MethodCache.Request();
- MethodCache.UpdateMethodName(mMethodId, fileName, className, methodName);
- // 记录方法数
- Profiler.instrumentMethodCount.getAndIncrement();
- }
- /* (non-Javadoc)
- * @see org.objectweb.asm.MethodAdapter#visitCode()
- */
- public void visitCode() {
- this.visitLdcInsn(mMethodId);
- this.visitMethodInsn(INVOKESTATIC, "com/taobao/profile/Profiler", "Start", "(I)V");
- super.visitCode();
- }
- /* (non-Javadoc)
- * @see org.objectweb.asm.MethodAdapter#visitLineNumber(int, org.objectweb.asm.Label)
- */
- public void visitLineNumber(final int line, final Label start) {
- MethodCache.UpdateLineNum(mMethodId, line);
- super.visitLineNumber(line, start);
- }
- /* (non-Javadoc)
- * @see org.objectweb.asm.MethodAdapter#visitInsn(int)
- */
- public void visitInsn(int inst) {
- switch (inst) {
- case Opcodes.ARETURN:
- case Opcodes.DRETURN:
- case Opcodes.FRETURN:
- case Opcodes.IRETURN:
- case Opcodes.LRETURN:
- case Opcodes.RETURN:
- case Opcodes.ATHROW:
- this.visitLdcInsn(mMethodId);
- this.visitMethodInsn(INVOKESTATIC, "com/taobao/profile/Profiler", "End", "(I)V");
- break;
- default:
- break;
- }
- super.visitInsn(inst);
- }
- }
visitAnnotationDefault?( visitAnnotation | visitParameterAnnotation | visitAttribute )*( visitCode( visitTryCatchBlock | visitLabel | visitFrame | visitXxxInsn |visitLocalVariable | visitLineNumber )*visitMaxs )?visitEnd这里所说的ASM访问不是指ASM代码去调用某个类的具体方法,而是指去分析某个类的某个方法的二进制字节码。
在这里visitCode方法将会在ASM开始访问某一个方法时调用,因此这个方法一般可以用来在进入分析JVM字节码之前来新增一些字节码,visitXxxInsn是在ASM具体访问到每个指令时被调用,上面代码中我们使用的是visitInsn方法,它是ASM访问到无参数指令时调用的,这里我们判但了当前指令是否为无参数的return来在方法结束前添加一些指令。
通过重写visitCode和visitInsn两个方法,我们就实现了具体的业务逻辑被调用前和被调用后植入监控运行时间的代码。
我们看重写里面做了什么:
- public ProfMethodAdapter(MethodVisitor visitor, String fileName, String className, String methodName) {
- super(visitor);
- mMethodId = MethodCache.Request();
- MethodCache.UpdateMethodName(mMethodId, fileName, className, methodName);
- // 记录方法数
- Profiler.instrumentMethodCount.getAndIncrement();
- }
这个构造函数里面首先调用了MethodCache.Request()占位并生成方法ID,然后初始化方法信息。
接着是
- public void visitCode() {
- this.visitLdcInsn(mMethodId);
- this.visitMethodInsn(INVOKESTATIC, "com/taobao/profile/Profiler", "Start", "(I)V");
- super.visitCode();
- }
重写这个方法实现了在访问方法前执行Profiler的静态方法start,用于开启时间以及方法信息记录逻辑。
在然后是
- public void visitInsn(int inst) {
- switch (inst) {
- case Opcodes.ARETURN:
- case Opcodes.DRETURN:
- case Opcodes.FRETURN:
- case Opcodes.IRETURN:
- case Opcodes.LRETURN:
- case Opcodes.RETURN:
- case Opcodes.ATHROW:
- this.visitLdcInsn(mMethodId);
- this.visitMethodInsn(INVOKESTATIC, "com/taobao/profile/Profiler", "End", "(I)V");
- break;
- default:
- break;
- }
- super.visitInsn(inst);
- }
通过以上方式实现了无变成的AOP注入。
结下来我们重点看下Profiler的start和end方法是如何将方法做记录的。
首先回到开始Tprofiler的实现原理中的那张图片:
其中使用了一个ThreadData数据用来记录线程性能分析数据。每个线程有自己的ThreadData
ThreadData的数据结构:
ThreadData的数据结构:
- public class ThreadData {
- /**
- * 性能分析数据
- */
- public ProfStack<long[]> profileData = new ProfStack<long[]>();
- /**
- * 栈帧
- */
- public ProfStack<long[]> stackFrame = new ProfStack<long[]>();
- /**
- * 当前栈深度
- */
- public int stackNum = 0;
- /**
- * 清空数据
- */
- public void clear(){
- profileData.clear();
- stackFrame.clear();
- stackNum = 0;ssss
- }
- }
frameData[0] = methodId;方法ID
frameData[1] = thrData.stackNum;调用数
frameData[2] = startTime;开始时间
thrData.stackFrame.push(frameData);
thrData.stackNum++;
这样在执行1个方法的前会做一些记录,并放入自定义栈
在来看看end做了什么:
- /**
- * 方法退出时调用,采集结束时间
- *
- * @param methodId
- */
- public static void End(int methodId) {
- if (!Manager.instance().canProfile()) {
- return;
- }
- long threadId = Thread.currentThread().getId();
- if (threadId >= size) {
- return;
- }
- long endTime;
- if (Manager.isNeedNanoTime()) {
- endTime = System.nanoTime();
- } else {
- endTime = System.currentTimeMillis();
- }
- try {
- ThreadData thrData = threadProfile[(int) threadId];
- if (thrData == null || thrData.stackNum <= 0 || thrData.stackFrame.size() == 0) {
- // 没有执行start,直接执行end/可能是异步停止导致的
- return;
- }
- // 栈太深则抛弃部分数据
- if (thrData.profileData.size() > 20000) {
- thrData.stackNum--;
- thrData.stackFrame.pop();
- return;
- }
- thrData.stackNum--;
- long[] frameData = thrData.stackFrame.pop();
- long id = frameData[0];
- if (methodId != id) {
- return;
- }
- long useTime = endTime - frameData[2];
- if (Manager.isNeedNanoTime()) {
- if (useTime > 500000) {
- frameData[2] = useTime;
- thrData.profileData.push(frameData);
- }
- } else if (useTime > 1) {
- frameData[2] = useTime;
- thrData.profileData.push(frameData);
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
其实挺简单的,就是在方法执行结束后出栈,获取到其对应的开始记录的数据,然后做统计和计算,在吧结果放入到性能分析数据中去。
大体上这个就是Tprofiler的实现原理。至于在外面如何获得这些数据,在后续的文章中在说吧。