Oracle RAC Cache Fusion 机制 详解 【偶像大神--dave】
Cache Fusion 是RAC 的核心机制,之前在blog里有小提到一些。
Oracle RAC 并发与架构
http://blog.csdn.net/tianlesoftware/archive/2010/03/07/5353087.aspx 【dave原创】
http://blog.csdn.net/panfelix/article/details/19946223 【转载dave】
在网上找到一篇很详细的资料,转过来。 链接如下:
http://avdeo.com/2008/07/21/oracle-rac-10g-cache-fusion/
一. Introduction
This post is about Oracle Cache Fusion technology, which is implemented in Oracle database 10g RAC. We are going to discuss just about cache fusion. You should have the architecture knowledge about RAC. Please check Oracle documentation for understanding Oracle RAC architecture. Also you can visit my previous post about Oracle RAC installation to get some basic information and installation details.
Cache fusion technology was partially implemented in Oracle 8i in OPS (Oracle Parallel Server). Before Oracle 8i the situation was different. If we take a case of multi-instance Oracle Parallel server and if one of the instance ask for a block of data which is currently modified by other instance of same database, then the holding instance needs to write the data to disk so that requesting instance can read the same data. This is called “Disk Ping”. This has greatly effected the performance of the database. With Oracle 8i, partial cache fusion was implemented.
Oracle 8i (Oracle Parallel Server) has a background process called “Block Server Process” which was responsible for cache fusion in Oracle 8i OPS. Following table gives the scenario when cache fusion works in Oracle 8i OPS and scenario where cache fusion was not working. Of course these limitations are not present in Oracle 10g RAC.
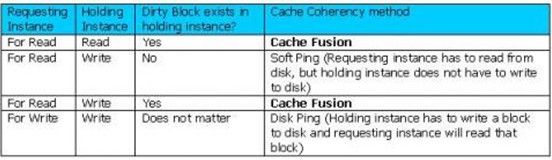
So when requesting instance ask for a block which is present in holding instance in a read or write mode and if the block is dirtied, then cache fusion used to work and block from cache of holding instance used to get copied to requesting instance. But if block is not dirtied and block is present in holding instance then requesting instance has to read the block from datafile. Also if the block is opened for write in holding instance and other instance wants to update the same block then holding instance have to write the block to disk so that requesting instance can read it.
二. Concept of cache fusion
Cache Fusion basically is about fusing the memory buffer cache of multiple instance into one single cache. For example if we have 3 instance in a RAC which is using the same datafiles and each instance is having its own memory buffer cache in there own SGA, then cache fusion will make the database behave as if it has a single instance and the total buffer cache is the sum of buffer cache of all the 3 instance. Below figure shows what I mean.
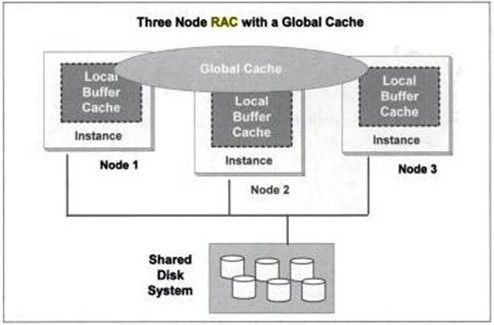
This behavior is possible because of high speed interconnect existing in the cluster between each instance. Each of instance is connected to other instance using a high-speed interconnect. This makes it possible to share the memory between 2 or more servers. Previously only datafile sharing was possible, now because of interconnect, even the cache memory can be shared.
But how this helps? Well, for example if we have a data block in one of the instance and its updating the block and other instance needs the same data block then this data block can be copied from holding instance buffer cache to requesting instance buffer cache using this high-speed interconnect. This high speed interconnect is a private connection made just for sending data blocks and more by instances. External users cannot use this connection. It is this interconnect which makes multiple server behave like a cluster. These servers are bind together using this interconnect.
Moving further, now we know how the cluster is formed and what is the back bone of cluster and what exactly we call “cache fusion”. Next we will see how cache fusion works. But before that we need to discuss few important headings which is very important to understand.
We will discuss following topics before discussing Cache Fusion
(1)Cache Coherency
(2)Multi-Version consistency model
(3)Resource Co-ordination – Synchronization
(4)Global Cache Service (GCS)
(5)Global Enqueue Service
(6)Global Resource Directory
(7)GCS resource modes and roles
(8)Past Images
(9)Block access modes and buffer states
I promise this wont be too heavy. Lets look into the overview of these concepts. I wont be going into the details, just sufficient for you to understand cache fusion.
2.1 Cache Coherency
If we consider a single instance database, whenever a user queries for data he gets a consistent view of data. For example another user has already read a block of data and changed some rows in buffer cache. If another user want to read the data from same data block then Oracle will make a copy of that data block in buffer cache and apply the undo information present in undo tablespace to get a consistent view of data. This consistent data is then presented to user who wants to read the data. This is called maintaining consistency of data.
Now consider a multi instance system RAC, where a data block might not be present in same instance. A user might be updating data block in some other instance. If data block are already available in local instance then they will be immediately available to the user. if they are present in some other instance with in the cluster, they will be transfered into local buffer cache.
Maintaining the consistency of data blocks in the buffer cache of multiple instance is called “Cache Coherency”.
2.2 Multi-Version consistency model
Multi version consistency model distinguishes between current version of data block and one or mode read consistent version of data block. The current block is the one which contains all the changes, committed as well as uncommitted. Example a user fired a DML on a data block which is not present in any of the instance. Then this block will be read from disk into buffer cache where the value gets changed. After then user commits and fires another DML on same data block. Now that data block is dirty and contains committed as well as uncommitted changes.
Suppose this data block is requested by another user for reading, then oracle will make a copy and apply undo information and make a Consistent Read “CR” copy of this block and ship it to requesting instance. Thus we have multiple versions of same data blocks, each of them are consistent with respect to the user who requested.
During the course of operation there can be many more version of same data block, each of them consistent with respect to some point in time.
关于CR 可以参考我的Blog:
CR (consistent read) blocks create 说明
http://blog.csdn.net/tianlesoftware/archive/2011/06/07/6529401.aspx
2.3 Resource Co-ordination – Synchronization
In case of multi instance system such as RAC, where same resources (example data block) are getting used concurrently, effective synchronization is required for maintaining consistency. With in the shared cache, co-ordination of concurrent task is called synchronization. The synchronization provided by Oracle RAC provides a cluster wide concurrency of resource and in turn ensure integrity of shared data. All though there is synchronization within the cache, there is some cost involved for doing the same. If we talk about low level operation of synchronization, its just a data copy operation or data transfer operation.
According to Oracle studies, accessing the block in a local cache is much faster then accessing the block from another instance cache with in the cluster. Because with local cache is the in memory copy and with other instance cache, the data transfer needs to be done over high speed interconnect which is obviously slower then in memory copy. Worst is the copy from disk, which is much slower then above two process. Below graph shows the block access time using these 3 methods.
For example:
Block access in local cache ~ 0.01 msec
Block access in remote cache ~ 2.5 msec
Block access on disk ~ 14 msec+
2.4 Global Cache Service
Global Cache Service (GCS) is the main component of Oracle Cache Fusion technology. This is represented by background process LMSn. There can be max 10 LMS process for an instance. The main function of GCS is to track the status and location of data blocks. Status of data block means the mode and role of data block (I will explain mode and role further). GCS is the main mechanism by which cache coherency among “multiple cache” is maintained. GCS is also responsible for block transfer between the instances.
2.5 Global Enqueue Service
Global Enqueue Service (GES) tracks the status of all Oracle enqueuing mechanism. This involves all non-cache fusion intra instance operations. GES performs concurrency control on dictionary cache locks, library cache locks and transactions. If performs this operation for resources that are accessed by more then once instance.
Enqueue services are also present in single instance database. These are responsible for locking the rows on a table using different locking modes. To understand more about enqueues, check Oracle documentation about locking.
2.6 Global Resource Directory
GES and GCS together maintains Global Resource Directory (GRD). GRD is like an in-memory database which contains details about all the blocks that are present in cache. GRD know what is the location of latest version of block, what is the mode of block, what is the role of block (Mode and role will be discussed shortly) etc. When ever a user ask for any data block GCS gets all the information from GRD. GRD is a distributed resource, meaning that each instance maintain some part of GRD. This distributed nature of GRD is a key to fault tolerance of RAC. GRD is stored in SGA.
Typically GRD contains following and more information
(1)Data Block Address – This is the address of data block being modified
(2)Location of most current version of data block
(3)Modes of data block
(4)Roles of data block
(5)SCN number of data block
(7)Image of data block – Could be current image or past image.
2.7 GCS resource modes and roles
Mode of data block is decided based on whether a resource holder intends to modify the data or read the data. The modes are as follows:
(1)Null (N) Mode: Null mode is the least restrictive mode. It indicates no access rights. It acts as a place holder.
(2)Shared (S) Mode: Shared mode indicate that database block is being read and not modified. However another session can read the data block
(3)Exclusive (X) Mode: Exclusive mode indicate exclusive access to block. Other resource cannot have write over this data block. However it can have consistent read on this datablock.
GCS resources also has roles. Following are the different roles present:
(1)Local: When a data block is first read into the instance from the disk it has a local role. Meaning that only 1 copy of data block exists in the cache. No other instance cache has a copy of this block.
(2)Global: Global role indicates that multiple copy of data block exists in clustered instance. For example a user connected to one of the instance request for a data block. This data block is read from disk into an instance. The role granted is local. If another instance request for same block this block will get copied to the requesting instance and the role becomes global.
This role and mode information is maintained in GRD (Global Resource Directory) by GCS (Global Cache Service).
2. 8 Past Images
Past Image concept was introduced in Oracle 9i to maintain data integrity. In an Oracle database, a typical block is not written to disk immediately after it is dirtied. This is to reduce excessive IO. When the same dirty block is requested by some other instance for write of read purpose, an image of the block is created in owning instance and then the block is shifted to requesting instance. This image copy of the block is called Past Image (PI). In the event of failure Oracle can reconstruct the block by reading PIs. It is also possible to have more then 1 PI of the block, depending on how many times the block was requested in dirty stage.
A past image of the block is different then CR (Consistent read) image. Past image is required to create CR by applying undo data.
“Juggling” Data with Multiple Past Images
(1)Multiple Past Image versions of a data block may be kept by different instances
(2)Upon a checkpoint, only the current image is written to disk; Past Images are discarded
(3)In the event of a failure, current version of block can be reconstructed from PIs
(4)Since PIs are kept in memory, they aid in avoiding frequent disk writes
(5)This avoids “disk pinging” experienced with 8i OPS due to frequent writes to disk
(6)Data is “juggled” in memory, without touching down on the disk
Oracle RAC Past Image(PI) 说明
http://blog.csdn.net/tianlesoftware/archive/2011/06/07/6529870.aspx
2.9 Block access modes and buffer states
An additional concurrency control concept is the buffer state which is the state of a buffer in the local cache of an instance. The buffer state of a block relates to the access mode of the block. For example, if a buffer state is exclusive current (XCUR), an instance owns the resource in exclusive mode.
To see a buffer’s state, query the “status” column of the V$BH dynamic performance view.
The V$BH view provides information about the block access mode and their buffer state names as follows:
(1)With a block access mode of NULL the buffer state name is CR — An instance can perform a consistent read of the block. That is, if the instance holds an older version of the data.
(2)With a block access mode of S the buffer state name is SCUR — An instance has shared access to the block and can only perform reads.
(3)With a block access mode of X the buffer state name is XCUR –An instance has exclusive access to the block and can modify it.
(4)With a block access mode of NULL the buffer state name is PI — An instance has made changes to the block but retains copies of it as past images to record its state before changes.
关于v$bh 视图的更多内容参考官网链接:
http://download.oracle.com/docs/cd/B19306_01/server.102/b14237/dynviews_1051.htm#REFRN30029
Only the SCUR and PI buffer states are Real Application Clusters-specific. There can be only one copy of any one block buffered in the XCUR state in the cluster database at any time. To perform modifications on a block, a process must assign an XCUR buffer state to the buffer containing the data block.
For example, if another instance requests read access to the most current version of the same block, then Oracle changes the access mode from exclusive to shared, sends a current read version of the block to the requesting instance, and keeps a PI buffer if the buffer contained a dirty block.
At this point, the first instance has the current block and the requesting instance also has the current block in shared mode. Therefore, the role of the resource becomes global. There can be multiple shared current (SCUR) versions of this block cached throughout the cluster database at any time.
三. Block transfer using Cache Fusion
Lets consider a very details example of how the block transfer happens between different instances. For explaining this example I am assuming a 3 node RAC system and also another assumption is that any DML statement is followed by a commit. So if I say that a user executed update that means user executed update + commit. But there is no checkpoint until the end.
Stage 1
In stage 1 datablock is requested by a user C who is connected to instance 3. So a data block is read into the buffer cache of instance 3.
SQL>select sales_rank from salesman where salesid = 10;
Assume this gives a value of 30. This block is read for the first time and its not present in any other instance. So the role of block is LOCAL and the block is read in SHARED mode. Also there are NO PAST IMAGES. So we describe this stage has instance 3 having SL0 mode (SHARED, LOCAL, 0 PAST IMAGES).
关于这些Lock Modes,在我的Blog里有说明:
Oracle RAC Past Image(PI) 说明
http://blog.csdn.net/tianlesoftware/archive/2011/06/07/6529870.aspx
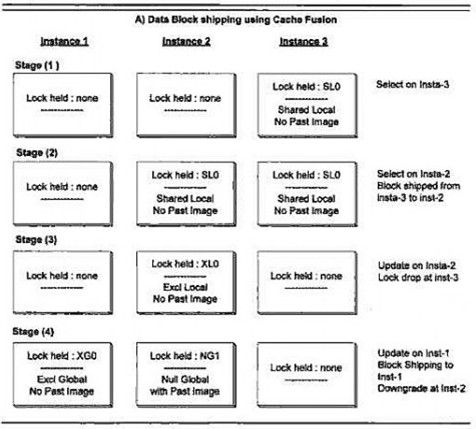
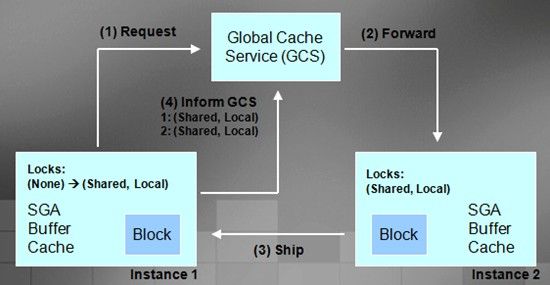
Stage 2
In stage 2 user B issues the same select statement against the salesman table. Instance 2 will need the same block; therefore, the block is shipped from instance 3 to instance 2 via cache fusion interconnect. There is no disk read at this time. Both instances are in SHARED mode (S) and role is LOCAL (L). Here if you see carefully that even though the block is present in more then once instance, still we say that role is local because the block is not yet dirtied. Had the block been dirty and then requested by other instance, then in that case the role will change to global.
Stage 3
In stage 3 user B decides to update the row and commit at instance 2. The new sales rank is 24. At this stage, instance 2 acquires EXCLUSIVE lock for updating the data at instance 2 and SHARED lock from instance 3 is downgraded to NULL lock.
SQL>update salesman set sales_rank = 24 where salesid = 10;
SQL>commit;
So instance 2 is having a mode XL0 (Exclusive, Local with 0 past images) and instance 3 is having a NULL lock, which is just a place holder. Also the role of the block is still LOCAL because the block is dirtied for the first time only on instance 2 and no other instance is having any dirty copy of that. If another instance now tries to update same block the role will change to global.
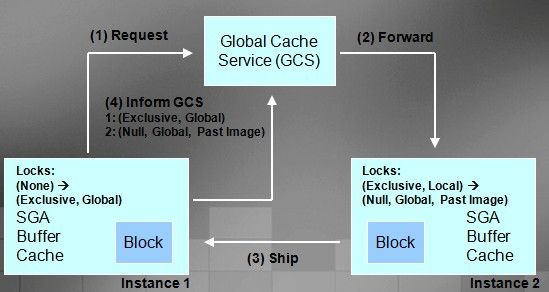
Stage 4
In stage 4 user A decides to update in instance 1 the same row and hence the same block with sales rank of 40. It finds that block is dirtied in instance 2. Therefore the data block is shipped to instance 1 from instance 2, however, a PAST IMAGE of the data block is created on instance 2 and lock mode on instance 2 is downgraded to NULL with a GLOBAL role. Instance 2 now has NG1 (NULL lock with GLOBAL role and 1 PAST IMAGE). At this time instance 1 will have EXCLUSIVE lock with GLOBAL role (XG0).
Stage 5
User C executes a select statement from instance 3 on same row. The data block from instance 1 being the most recent copy (GRD (Global Resource Directory) knows this information about which instance is having the latest copy of data block), it is shipped to instance 3. As a result the lock on instance 1 is converted to SHARED GLOBAL with 1 PAST IMAGE. The reason the lock gets changed to SHARED and not NULL is because instance 3 asked for shared lock (for reading data) and not exclusive lock (for updating data). If the instance 3 asked for exclusive lock then the instance 1 would have had NULL lock.
Also the instance 3 will now hold SG0 (SHARED, GLOBAL with 0 PAST IMAGES).
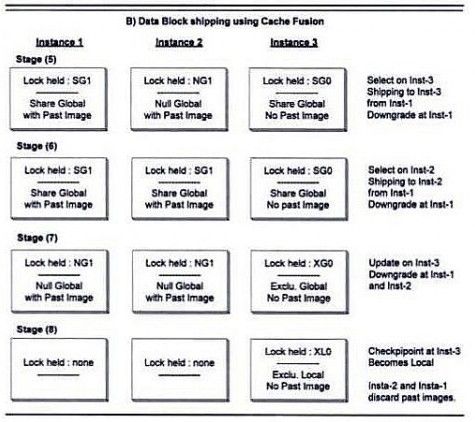
Stage 6
User B issues the same select statement against the salesman table on instance 2. Instance 2 will request for a consistent copy of buffer from another instance, which happens to be the current master.
Therefore instance 1 will ship the block to instance 2, where it will be required with SG1 (SHARED, GLOBAL with 1 PAST IMAGE). So instance 2 mode becomes SG1.
Stage 7
User C on instance 3 updates the same row. Therefore the instance 3 requires an exclusive lock and instance 1 and instance 2 will be downgraded to NULL lock with GLOBAL role and 1 PAST IMAGE. Instance 3 will have EXCLUSIVE lock, GLOBAL role and with no PAST IMAGES (XG0).
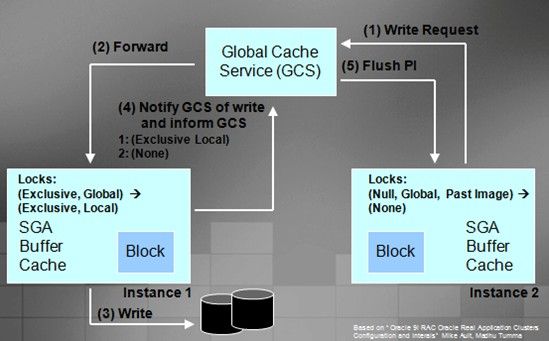
Stage 8
The checkpoint is initiated and a “Write to Disk” takes place at instance 3. As a result previous past images will be discarded (as they are not required for recovery) and instance 3 will hold that block in EXCLUSIVE lock LOCAL role with no PAST IMAGES (XL0).
Further if any instance wants to read or write on the same block then a copy will be again shifted from instance 3.
图示:
Read/Read Cache Fusion – GCS Processing
Write/Write Cache Fusion – GCS Processing
Blocks to Disk – GCS Processing
四. Online Instance Recovery Steps
步骤如下:
(1)Instance Failure detected by Cluster Manager and GCS
(2)Reconfiguration of GES resources (enqueues); global resource directory is frozen
(3)Reconfiguration of GCS resources; involves redistribution among surviving instances
(4)One of the surviving instances becomes the “recovering instance”
(5)SMON process of recovering instance starts first pass of redo log read of the failed instance’s redo log thread
(6)SMON finds BWR (block written records) in the redo and removes them as their PI is already written to disk
(7)SMON prepares recovery set of the blocks modified by the failed instance but not written to disk
(8)Entries in the recovery list are sorted by first dirty SCN
(9)SMON informs each block’s master node to take ownership of the block for recovery
(10)Second pass of log read begins.
(11)Redo is applied to the data files.
(12)Global Resource Directory is unfrozen