原文链接:
http://www.davedba.com/oracle-deadlocking-latch-is-blocked-waiting-for-the-lock-details.html
锁这东西是纯概念性的东西,但是作用又非常大。 以前整理过两篇文章,今天又看了点书,觉得还不是很清楚。 就重新整理了下。 在想要不要把以前的文章删掉,这样在blog里是比较简介的,但后来又一想。 这些连接在其他的地方可能被引用了。 就决定还是保留着了,也算见证自己成长的一个过程。
ORACLE 锁机制
http://davedba.com/oracle-locking-mechanisms.html
oracle 锁问题的解决
http://davedba.com/oracle-lock-problem-solution.html
关于Oracle 锁的内容,可以参考
Data Concurrency and Consistency(Oracle 并发与一致)
http://download.oracle.com/docs/cd/E11882_01/server.112/e10713/consist.htm#CNCPT1339
一.锁(Lock)
1.1 锁的概念
数据库是一个多用户使用的共享资源。当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况。若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数据库的一致性。
加锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更新操作。
在Oracle 数据库中,它并不是对某个表加上锁或者某几行加上锁,锁是以数据块的一个属性存在的。 也就是说,每个数据块本身就存储着自己数据块中数据的信息,这个地方叫ITL(Interested Transaction List),凡是在这个数据块上有活动的事务,它的信息就会记录在这里面供后续的操作查询,一保证事务的一致性。
1.2 锁的分类
1.2.1. 按用户与系统划分,可以分为自动锁与显示锁
a) 自动锁(Automatic Locks):当进行一项数据库操作时,缺省情况下,系统自动为此数据库操作获得所有有必要的锁。自动锁分DML锁,DDL锁,system locks。
b) 显示锁(Manual Data Locks):某些情况下,需要用户显示的锁定数据库操作要用到的数据,才能使数据库操作执行得更好,显示锁是用户为数据库对象设定的。
Oracle Database performs locking automatically to ensure data concurrency, data integrity, and statement-level read consistency. However, you can manually override the Oracle Database default locking mechanisms. Overriding the default locking is useful in situations such as the following:
Applications require transaction-level read consistency or repeatable reads.
In this case, queries must produce consistent data for the duration of the transaction, not reflecting changes by other transactions. You can achieve transaction-level read consistency by using explicit locking, read-only transactions, serializable transactions, or by overriding default locking.
Applications require that a transaction have exclusive access to a resource so that the transaction does not have to wait for other transactions to complete.
You can override Oracle Database automatic locking at the session or transaction level. At the session level, a session can set the required transaction isolation level with the ALTER SESSION statement. At the transaction level, transactions that include the following SQL statements override Oracle Database default locking:
(1)The SET TRANSACTION ISOLATION LEVEL statement
(2)The LOCK TABLE statement (which locks either a table or, when used with views, the base tables)
(3)The SELECT … FOR UPDATE statement
Locks acquired by the preceding statements are released after the transaction ends or a rollback to savepoint releases them.
If Oracle Database default locking is overridden at any level, then the database administrator or application developer should ensure that the overriding locking procedures operate correctly. The locking procedures must satisfy the following criteria: data integrity is guaranteed, data concurrency is acceptable, and deadlocks are not possible or are appropriately handled.
1.2.2. 按锁级别划分,可分为: 排它锁(Exclusive Locks,即X锁)和共享锁(Share Locks,即S锁)
a) 共享锁( S ): 共享锁使一个事务对特定数据库资源进行共享访问——另一事务也可对此资源进行访问或获得相同共享锁。共享锁为事务提供高并发性,但如拙劣的事务设计+共享锁容易造成死锁或数据更新丢失。
b) 排它锁( X): 事务设置排它锁后,该事务单独获得此资源,另一事务不能在此事务提交之前获得相同对象的共享锁或排它锁。
1.2.3 按操作划分,可分为DML锁(data locks,数据锁)、DDL锁(data dictionary lock)和 System Locks。
| Lock |
Description |
| DML Locks |
Protect data. For example, table locks lock entire tables, while row locks lock selected rows. See "DML Locks". |
| DDL Locks |
Protect the structure of schema objects—for example, the dictionary definitions of tables and views. See "DDL Locks". |
| System Locks |
Protect internal database structures such as data files. Latches, mutexes, and internal locks are entirely automatic. See "System Locks". |
1.2.3.1 DML锁
这部分内容,可以参考Oracle 联机文档
Automatic Locks in DML Operations
http://download.oracle.com/docs/cd/E11882_01/server.112/e10592/ap_locks001.htm#SQLRF55502
DML锁用于控制并发事务中的数据操纵,保证数据的一致性和完整性。DML 锁主要用于保护并发情况下的数据完整性。 它又分为:
(1)TM锁(表级锁)
(2)TX锁(事务锁或行级锁)
当Oracle执行DML语句时,系统自动在所要操作的表上申请TM类型的锁。当TM锁获得后,系统再自动申请TX类型的锁,并将实际锁定的数据行的锁标志位进行置位。这样在事务加锁前检查TX锁相容性时就不用再逐行检查锁标志,而只需检查TM锁模式的相容性即可,大大提高了系统的效率。
在数据行上只有X锁(排他锁)。在Oracle数据库中,当一个事务首次发起一个DML语句时就获得一个TX锁,该锁保持到事务被提交或回滚。当两个或多个会话在表的同一条记录上执行 DML语句时,第一个会话在该条记录上加锁,其他的会话处于等待状态。当第一个会话提交后,TX锁被释放,其他会话才可以加锁。
当Oracle数据库发生TX锁等待时,如果不及时处理常常会引起Oracle数据库挂起,或导致死锁的发生,产生ORA-600的错误。这些现象都会对实际应用产生极大的危害,如长时间未响应,大量事务失败等。
TM锁(表锁)
当事务获得行锁后,此事务也将自动获得该行的表锁(共享锁),以防止其它事务进行DDL语句影响记录行的更新。事务也可以在进行过程中获得共享锁或排它锁,只有当事务显示使用LOCK TABLE语 句显示的定义一个排它锁时,事务才会获得表上的排它锁,也可使用LOCK TABLE显示的定义一个表级的共享锁(LOCK TABLE具体用法请参考相关文档)。
TM锁包括了SS、SX、S、X 等多种模式,在数据库中用0-6来表示。不同的SQL操作产生不同类型的TM锁。
TM锁类型表
| 锁模式 |
锁描述 |
解释 |
SQL操作 |
| 0 |
none |
||
| 1 |
NULL |
空 |
Select |
| 2 |
SS(Row-S) |
行级共享锁,其他对象只能查询这些数据行 |
Select for update、Lock for update、Lock row share |
| 3 |
SX(Row-X) |
行级排它锁,在提交前不允许做DML操作 |
Insert、Update、 Delete、Lock row share |
| 4 |
S(Share) |
共享锁: 阻止其他DML操作 |
Create index、Lock share |
| 5 |
SSX(S/Row-X) |
共享行级排它锁:阻止其他事务操作 |
Lock share row exclusive |
| 6 |
X(Exclusive) |
排它锁:独立访问使用 |
Alter table、Drop able、Drop index、Truncate table 、Lock exclusive |
TX锁(行锁)
当事务执行数据库插入、更新、删除操作时,该事务自动获得操作 表中操作行的排它锁。
对用户的数据操纵,Oracle可以自动为操纵的数据进行加锁,但如果有操纵授权,则为满足并发操纵的需要另外实施加锁。DML锁可由一个用户进程以显式的方式加锁,也可通过某些SQL语句隐含方式实现。 这部分属于Manual Data Locks。
DML锁有如下三种加锁方式:
(1)、共享锁方式(SHARE)
(2)、独占锁方式(EXCLUSIVE)
(3)、共享更新锁(SHARE UPDATE)
其中:
SHARE,EXCLUSIVE用于TM锁(表级锁)
SHARE UPDATE用于TX锁(行级锁)。
(1)共享方式的表级锁(Share)
共享方式的表级锁是对表中的所有数据进行加锁,该锁用于保护查询数据的一致性,防止其它用户对已加锁的表进行更新。其它用户只能对该表再施加共享方式的锁,而不能再对该表施加独占方式的锁,共享更新锁可以再施加,但不允许持有共享更新封锁的进程做更新。共享该表的所有用户只能查询表中的数据,但不能更新。
共享方式的表级锁只能由用户用SQL语句来设置,基语句格式如下:
LOCK TABLE <表名>[,<表名>]… IN SHARE MODE [NOWAIT]
执行该语句,对一个或多个表施加共享方式的表封锁。当指定了选择项NOWAIT,若该锁暂时不能施加成功,则返回并由用户决定是进行等待,还是先去执行别的语句。
持有共享锁的事务,在出现如下之一的条件时,便释放其共享锁:
A、执行COMMIT或ROLLBACK语句。
B、退出数据库(LOG OFF)。
C、程序停止运行。
共享方式表级锁常用于一致性查询过程,即在查询数据期间表中的数据不发生改变。
(2)独占方式表级锁(Exclusive)
独占方式表级锁是用于加锁表中的所有数据,拥有该独占方式表封锁的用户,即可以查询该表,又可以更新该表,其它的用户不能再对该表施加任何加锁(包括共享、独占或共享更新封锁)。其它用户虽然不能更新该表,但可以查询该表。
独占方式的表封锁可通过如下的SQL语句来显示地获得:
LOCK TABLE <表名>[,<表名>]…. IN EXCLUSIVE MODE [NOWAIT]
独占方式的表级锁也可以在用户执行DML语句INSERT、UPDATE、DELETE时隐含获得。
拥有独占方式表封锁的事务,在出现如下条件之一时,便释放该封锁:
(1)、执行COMMIT或ROLLBACK语句。
(2)、退出数据库(LOG OFF)
(3)、程序停止运行。
独占方式封锁通常用于更新数据,当某个更新事务涉及多个表时,可减少发生死锁。
(3)共享更新加锁方式(Share Update)
共享更新加锁是对一个表的一行或多行进行加锁,因而也称作行级加锁。表级加锁虽然保证了数据的一致性,但却减弱了操作数据的并行性。行级加锁确保在用户取得被更新的行到该行进行更新这段时间内不被其它用户所修改。因而行级锁即可保证数据的一致性又能提高数据操作的迸发性。
可通过如下的两种方式来获得行级封锁:
(1)、执行如下的SQL封锁语句,以显示的方式获得:
LOCK TABLE <表名>[,<表名>]…. IN SHARE UPDATE MODE [NOWAIT]
(2)、用如下的SELECT …FOR UPDATE语句获得:
SELECT <列名>[,<列名>]…FROM <表名> WHERE <条件> FOR UPDATE OF <列名>[,<列名>]…..[NOWAIT]
一旦用户对某个行施加了行级加锁,则该用户可以查询也可以更新被加锁的数据行,其它用户只能查询但不能更新被加锁的数据行.如果其它用户想更新该表中的数据行,则也必须对该表施加行级锁.即使多个用户对一个表均使用了共享更新,但也不允许两个事务同时对一个表进行更新,真正对表进行更新时,是以独占方式锁表,一直到提交或复原该事务为止。行锁永远是独占方式锁。
当出现如下之一的条件,便释放共享更新锁:
(1)、执行提交(COMMIT)语句;
(2)、退出数据库(LOG OFF)
(3)、程序停止运行。
执行ROLLBACK操作不能释放行锁。
1.2.3.2 DDL锁(dictionary locks)
DDL锁用于保护数据库对象的结构,如表、索引等的结构定义。
DDL锁又可以分为:排它DDL锁、共享DDL锁、分析锁
(1) 排它DDL锁:
创建、修改、删除一个数据库对象的DDL语句获得操作对象的 排它锁。如使用alter table语句时,为了维护数据的完成性、一致性、合法性,该事务获得一排它DDL锁。
(2) 共享DDL锁:
需在数据库对象之间建立相互依赖关系的DDL语句通常需共享获得DDL锁。如创建一个包,该包中的过程与函数引用了不同的数据库表,当编译此包时,该事务就获得了引用表的共享DDL锁。
(3) 分析锁:
ORACLE使用共享池存储分析与优化过的SQL语句及PL/SQL程序,使运行相同语句的应用速度更快。一个在共享池中缓存的对象获得它所引用数据库对象的分析锁。分析锁是一种独特的DDL锁类型,ORACLE使用它追踪共享池对象及它所引用数据库对象之间的依赖关系。当一个事务修改或删除了共享池持有分析锁的数据库对象时,ORACLE使共享池中的对象作废,下次在引用这条SQL/PLSQL语 句时,ORACLE重新分析编译此语句。
DDL级加锁也是由ORACLE RDBMS来控制,它用于保护数据字典和数据定义改变时的一致性和完整性。它是系统在对SQL定义语句作语法分析时自动地加锁,无需用户干予。
字典/语法分析加锁共分三类:
(1)字典操作锁:
用于对字典操作时,锁住数据字典,此封锁是独占的,从而保护任何一个时刻仅能对一个字典操作。
(2)字典定义锁:
用于防止在进行字典操作时又进行语法分析,这样可以避免在查询字典的同时改动某个表的结构。
(3)表定义锁:
用于一个SQL语句正当访问某个表时,防止字典中与该表有关的项目被修改。
Automatic Locks in DDL Operations
http://download.oracle.com/docs/cd/E11882_01/server.112/e10592/ap_locks002.htm#SQLRF55509
A data dictionary (DDL) lock protects the definition of a schema object while an ongoing DDL operation acts on or refers to the object. Only individual schema objects that are modified or referenced are locked during DDL operations. The database never locks the whole data dictionary.
Oracle Database acquires a DDL lock automatically on behalf of any DDL transaction requiring it. Users cannot explicitly request DDL locks. For example, if a user creates a stored procedure, then Oracle Database automatically acquires DDL locks for all schema objects referenced in the procedure definition. The DDL locks prevent these objects from being altered or dropped before procedure compilation is complete.
Exclusive DDL Locks
An exclusive DDL lock prevents other sessions from obtaining a DDL or DML lock. Most DDL operations, except for those described in "Share DDL Locks", require exclusive DDL locks for a resource to prevent destructive interference with other DDL operations that might modify or reference the same schema object. For example, DROP TABLE is not allowed to drop a table while ALTER TABLE is adding a column to it, and vice versa.
Exclusive DDL locks last for the duration of DDL statement execution and automatic commit. During the acquisition of an exclusive DDL lock, if another DDL lock is already held on the schema object by another operation, then the acquisition waits until the older DDL lock is released and then proceeds.
Share DDL Locks
A share DDL lock for a resource prevents destructive interference with conflicting DDL operations, but allows data concurrency for similar DDL operations.
For example, when a CREATE PROCEDURE statement is run, the containing transaction acquires share DDL locks for all referenced tables. Other transactions can concurrently create procedures that reference the same tables and acquire concurrent share DDL locks on the same tables, but no transaction can acquire an exclusive DDL lock on any referenced table.
A share DDL lock lasts for the duration of DDL statement execution and automatic commit. Thus, a transaction holding a share DDL lock is guaranteed that the definition of the referenced schema object remains constant during the transaction.
Breakable Parse Locks
A parse lock is held by a SQL statement or PL/SQL program unit for each schema object that it references. Parse locks are acquired so that the associated shared SQL area can be invalidated if a referenced object is altered or dropped. A parse lock is called a breakable parse lock because it does not disallow any DDL operation and can be broken to allow conflicting DDL operations.
A parse lock is acquired in the shared pool during the parse phase of SQL statement execution. The lock is held as long as the shared SQL area for that statement remains in the shared pool.
1.2.3.2 System Locks
System Locks
http://download.oracle.com/docs/cd/E11882_01/server.112/e10713/consist.htm#CIHJBIBB
Oracle Database uses various types of system locks to protect internal database and memory structures. These mechanisms are inaccessible to users because users have no control over their occurrence or duration.
Latches
Latches are simple, low-level serialization mechanisms that coordinate multiuser access to shared data structures, objects, and files. Latches protect shared memory resources from corruption when accessed by multiple processes. Specifically, latches protect data structures from the following situations:
(1)Concurrent modification by multiple sessions
(2)Being read by one session while being modified by another session
(3)Deallocation (aging out) of memory while being accessed
Typically, a single latch protects multiple objects in the SGA. For example, background processes such as DBWn and LGWR allocate memory from the shared pool to create data structures. To allocate this memory, these processes use a shared pool latch that serializes access to prevent two processes from trying to inspect or modify the shared pool simultaneously. After the memory is allocated, other processes may need to access shared pool areas such as the library cache, which is required for parsing. In this case, processes latch only the library cache, not the entire shared pool.
Unlike enqueue latches such as row locks, latches do not permit sessions to queue. When a latch becomes available, the first session to request the latch obtains exclusive access to it. Latch spinning occurs when a process repeatedly requests a latch in a loop, whereas latch sleeping occurs when a process releases the CPU before renewing the latch request.
Typically, an Oracle process acquires a latch for an extremely short time while manipulating or looking at a data structure. For example, while processing a salary update of a single employee, the database may obtain and release thousands of latches. The implementation of latches is operating system-dependent, especially in respect to whether and how long a process waits for a latch.
An increase in latching means a decrease in concurrency. For example, excessive hard parse operations create contention for the library cache latch. The V$LATCH view contains detailed latch usage statistics for each latch, including the number of times each latch was requested and waited for.
Mutexes
A mutual exclusion object (mutex) is a low-level mechanism that prevents an object in memory from aging out or from being corrupted when accessed by concurrent processes. A mutex is similar to a latch, but whereas a latch typically protects a group of objects, a mutex protects a single object.
Mutexes provide several benefits:
(1)A mutex can reduce the possibility of contention.
Because a latch protects multiple objects, it can become a bottleneck when processes attempt to access any of these objects concurrently. By serializing access to an individual object rather than a group, a mutex increases availability.
(2)A mutex consumes less memory than a latch.
(3)When in shared mode, a mutex permits concurrent reference by multiple sessions.
Internal Locks
Internal locks are higher-level, more complex mechanisms than latches and mutexes and serve various purposes. The database uses the following types of internal locks:
(1)Dictionary cache locks
These locks are of very short duration and are held on entries in dictionary caches while the entries are being modified or used. They guarantee that statements being parsed do not see inconsistent object definitions. Dictionary cache locks can be shared or exclusive. Shared locks are released when the parse is complete, whereas exclusive locks are released when the DDL operation is complete.
(2)File and log management locks
These locks protect various files. For example, an internal lock protects the control file so that only one process at a time can change it. Another lock coordinates the use and archiving of the online redo log files. Data files are locked to ensure that multiple instances mount a database in shared mode or that one instance mounts it in exclusive mode. Because file and log locks indicate the status of files, these locks are necessarily held for a long time.
(3)Tablespace and undo segment locks
These locks protect tablespaces and undo segments. For example, all instances accessing a database must agree on whether a tablespace is online or offline. Undo segments are locked so that only one database instance can write to a segment.
二. 死锁
A situation in which two or more users are waiting for data locked by each other. Such deadlocks are rare in Oracle Database.
定义: 当两个用户希望持有对方的资源时就会发生死锁.
即两个用户互相等待对方释放资源时,oracle认定为产生了死锁,在这种情况下,将以牺牲一个用户作为代价,另一个用户继续执行,牺牲的用户的事务将回滚.
例子:
1:用户1对A表进行Update,没有提交。
2:用户2对B表进行Update,没有提交。
此时双反不存在资源共享的问题。
3:如果用户2此时对A表作update,则会发生阻塞,需要等到用户一的事物结束。
4:如果此时用户1又对B表作update,则产生死锁。此时Oracle会选择其中一个用户进行会滚,使另一个用户继续执行操作。
起因:
Oracle的死锁问题实际上很少见,如果发生,基本上都是不正确的程序设计造成的,经过调整后,基本上都会避免死锁的发生。
在Oracle系统中能自动发现死锁,并选择代价最小的,即完成工作量最少的事务予以撤消,释放该事务所拥有的全部锁,记其它的事务继续工作下去。
从系统性能上考虑,应该尽可能减少资源竞争,增大吞吐量,因此用户在给并发操作加锁时,应注意以下几点:
1、对于UPDATE和DELETE操作,应只锁要做改动的行,在完成修改后立即提交。
2、当多个事务正利用共享更新的方式进行更新,则不要使用共享封锁,而应采用共享更新锁,这样其它用户就能使用行级锁,以增加并行性。
3、尽可能将对一个表的操作的并发事务施加共享更新锁,从而可提高并行性。
4、在应用负荷较高的期间,不宜对基础数据结构(表、索引、簇和视图)进行修改
如果死锁不能自动释放,就需要我们手工的kill session。 步骤如下:
1. 查看有无死锁对象,如有kill session
/* Formatted on 2010/8/18 9:51:59 (QP5 v5.115.810.9015) */
SELECT 'alter system kill session ''' || sid || ',' || serial# || ''';' "Deadlock"
FROM v$session
WHERE sid IN (SELECT sid
FROM v$lock
WHERE block = 1);
如果有,会返回类似与如下的信息:
alter system kill session '132,731';
alter system kill session '275,15205';
alter system kill session '308,206';
alter system kill session '407,3510';
kill session:
执行alter system kill session '391,48398'(sid为391);
注意: 应当注意对于sid在100以下的应当谨慎,可能该进程对应某个application,如对应某个事务,可以kill.
2. 查看导致死锁的SQL
/* Formatted on 2010/8/18 0:06:11 (QP5 v5.115.810.9015) */
SELECT s.sid, q.sql_text
FROM v$sqltext q, v$session s
WHERE q.address = s.sql_address AND s.sid = &sid – 这个&sid 是第一步查询出来的
ORDER BY piece;
返回:
SID SQL_TEXT
———- —————————————————————-
77 UPDATE PROFILE_USER SET ID=1,COMPANY_ID=2,CUSTOMER_ID=3,NAMED
77 _INSURED_ID=4,LOGIN=5,ROLE_ID=6,PASSWORD=7,EMAIL=8,TIME_ZON
77 E=9 WHERE PROFILE_USER.ID=:34
3 rows selected.
3. 查看谁锁了谁
/* Formatted on 2010/8/18 0:07:49 (QP5 v5.115.810.9015) */
SELECT s1.username
|| '@'
|| s1.machine
|| ' ( SID='
|| s1.sid
|| ' ) is blocking '
|| s2.username
|| '@'
|| s2.machine
|| ' ( SID='
|| s2.sid
|| ' ) '
AS blocking_status
FROM v$lock l1,
v$session s1,
v$lock l2,
v$session s2
WHERE s1.sid = l1.sid
AND s2.sid = l2.sid
AND l1.BLOCK = 1
AND l2.request > 0
AND l1.id1 = l2.id1
AND l2.id2 = l2.id2;
或者
/* Formatted on 2010/8/18 0:03:46 (QP5 v5.115.810.9015) */
SELECT /*+ rule */
LPAD (' ', DECODE (l.xidusn, 0, 3, 0))
|| l.oracle_username
User_name,
o.owner,
o.object_name,
o.object_type,
s.sid,
s.serial#
FROM v$locked_object l, dba_objects o, v$session s
WHERE l.object_id = o.object_id AND l.session_id = s.sid
ORDER BY o.object_id, xidusn DESC
三.锁 和 阻塞
3.1 相关概念
通常来讲,系统如果平时运行正常,突然会停止不动,多半是被阻塞(Blocked)住了。 我们可以通过v$lock 这张视图,看查看阻塞的信息。
SQL> desc v$lock;
名称 是否为空? 类型
—————————————– ——– —————–
ADDR RAW(4)
KADDR RAW(4)
SID NUMBER
TYPE VARCHAR2(2)
ID1 NUMBER
ID2 NUMBER
LMODE NUMBER
REQUEST NUMBER
CTIME NUMBER
BLOCK NUMBER
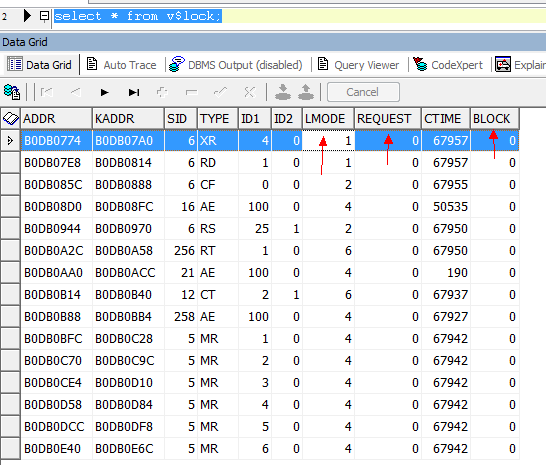
我们关注的比较多的是request 和 block 字段。
如果某个request列是一个非0值,那么它就是在等待一个锁。 如果block列是1,这个SID 就持有了一个锁,并且阻塞别人获得这个锁。 这个锁的类型由TYPE 字段定义。锁的模式有LMODE 字段定义,ID1和ID2 字段定义了这个锁的相关信息。ID1相同,就代表指向同一个资源。 这样就有可能有加锁者和等待者。 LMODE 的6中模式参考上面的TM锁类型表。
可以结合v$lock 和 v$session 视图来查询相关的信息:
/* Formatted on 2010/8/18 10:03:08 (QP5 v5.115.810.9015) */
SELECT sn.username,
m.SID,
sn.SERIAL#,
m.TYPE,
DECODE (m.lmode,
0,
'None',
1,
'Null',
2,
'Row Share',
3,
'Row Excl.',
4,
'Share',
5,
'S/Row Excl.',
6,
'Exclusive',
lmode,
LTRIM (TO_CHAR (lmode, '990')))
lmode,
DECODE (m.request,
0,
'None',
1,
'Null',
2,
'Row Share',
3,
'Row Excl.',
4,
'Share',
5,
'S/Row Excl.',
6,
'Exclusive',
request,
LTRIM (TO_CHAR (m.request, '990')))
request,
m.id1,
m.id2
FROM v$session sn, v$lock m
WHERE (sn.SID = m.SID AND m.request != 0) –存在锁请求,即被阻塞
OR (sn.SID = m.SID –不存在锁请求,但是锁定的对象被其他会话请求锁定
AND m.request = 0 AND lmode != 4
AND (id1, id2) IN
(SELECT s.id1, s.id2
FROM v$lock s
WHERE request != 0
AND s.id1 = m.id1
AND s.id2 = m.id2))
ORDER BY id1, id2, m.request;
或者
/* Formatted on 2010/8/18 0:03:02 (QP5 v5.115.810.9015) */
SELECT /*+ rule */
s .username,
DECODE (l.TYPE, 'TM', 'TABLE LOCK', 'TX', 'ROW LOCK', NULL)
LOCK_LEVEL,
o.owner,
o.object_name,
o.object_type,
s.sid,
s.serial#,
s.terminal,
s.machine,
s.program,
s.osuser
FROM v$session s, v$lock l, dba_objects o
WHERE l.sid = s.sid AND l.id1 = o.object_id(+) AND s.username IS NOT NULL
3.2 引起阻塞的几种常见情况
(1)DML语句引起阻塞
(2)外键没有创建索引
3.2.1 DML 语句
当一个会话保持另一个会话正在请求的资源上的锁定时,就会发生阻塞。被阻塞的会话将一直挂起,直到持有锁的会话放弃锁定的资源为止。4个常见的dml语句会产生阻塞
INSERT
UPDATE
DELETE
SELECT…FOR UPDATE
INSERT
Insert发生阻塞的唯一情况就是用户拥有一个建有主键约束的表。当2个的会话同时试图向表中插入相同的数据时,其中的一个会话将被阻塞,直到另外一个会话提交或会滚。一个会话提交时,另一个会话将收到主键重复的错误。回滚时,被阻塞的会话将继续执行。
Update 和 Delete
UPDATE 和DELETE当执行Update和delete操作的数据行已经被另外的会话锁定时,将会发生阻塞,直到另一个会话提交或会滚。
Select …for update
当一个用户发出select..for update的错作准备对返回的结果集进行修改时,如果结果集已经被另一个会话锁定,
此时Oracle已经对返回的结果集上加了排它的行级锁,所有其他对这些数据进行的修改或删除操作都必须等待这个锁的释放(操作commit或rollback.),产生的外在现象就是其他的操作将发生阻塞.
同样这个查询的事务将会对该表加表级锁,不允许对该表的任何ddl操作,否则将会报出Ora-00054:resource busy and acquire with nowait specified.
可以通过发出 select… for update nowait的语句来避免发生阻塞,如果资源已经被另一个会话锁定,则会返回以下错误:Ora-00054:resource busy and acquire with nowait specified.
3.2.2 外键没有创建索引
如果系统中有主,外键引用关系,并且满足一下三个条件中的任意一个,那么就应该考虑给外键字段创建索引,否则系统的性能可能会下降甚至阻塞。
(1) 主表上有频繁的删除操作
(2) 主键上有频繁的修改操作。
(3) 业务上经常会出现主表和从表做关联查询的情况。
第一和第二个条件操作的时候,主表会在从表上创建一个锁定,以保证主表主键的修改不会导致从表的数据在引用上出现问题,这是一个数据引用完整性的要求。 如果主表上经常出现这样的删除或者是对主键列进行修改的操作,或者每次操作的记录数很多,都将会造成从表长时间被锁定,而影响其他用户的正常操作。 比如主表每次删除1000行数据,它就需要扫描从表1000次,以确定每一行记录的改变都不会造成从表数据在引用上的不完整。
特别是在OLAP 系统中,从表经常会是非常巨大的表,在这种情况下,如果从表没有索引,那么查询几乎是不可想象的。
Oracle OLAP 与 OLTP 介绍
http://davedba.com/introduction-to-oracle-olap-and-oltp.html
四. Latch 和 等待
Latch 属于System Locks. 在前面的内容里里,已有相关的说明。 Latch 是Oracle 为保护内存结构而发明的一种资源。
在Oracle 复杂的内存结构中,比如SGA中,各种数据被反复从磁盘读取到内存,又被重新写回到磁盘上,如果有并发的用户做相同的事情,Oracle必须使用一种机制,来保证数据在读取的时候,只能由一个会话来完成,这种保护机制就是Latch。
并发(concurrency):是说有超过两个以上的用户对同样的数据做修改(可能包括插入,删除和修改)。
并行(parallel):是说将一件事情分成很多小部分,让每一部分同时执行,最后将执行结果汇总成最终结果。
可以把Latch 理解为一种轻量级的锁,它不会造成阻塞,只会导致等待。 阻塞是一种系统设计上的问题,等待是一种系统资源争用的问题。
如果发现系统中经常由于Lock 导致用户等待,这时需要考虑系统在逻辑设计上是否有问题,比如多用户对主键的删除或者修改,是否有用户使用select … for update这样的语法,外键是否创建索引的因素。 这些因素是需要结合系统的业务逻辑性来进行数据库对象设计的。
如果发现系统慢是因为很多的Latch争用,就要考虑系统及数据库自身设计上是否存在问题,比如是否使用绑定变量,是否存在热快,数据存储参数设计是否合理等因素。
导致Latch争用而等待的原因非常多,内存中很多资源都可能存在争用。 最常见的两类latch争用如下:
(1) 共享池中的Latch争用。
(2) 数据缓冲池中的latch争用。
Oracle 内存 架构 详解
http://davedba.com/oracle-memory-architecture-details.html
4.1 共享池中的Latch争用
共享池中如果存在大量的SQL被反复分析,就会造成很大的Latch争用和长时间的等待,最常见的现象就是没有绑定变量。
最常见的集中共享池里的Latch是 library cache。 可以通过一下SQL 来查询:‘’
SQL> select * from v$latchname where name like 'library cache%';
在分析系统性能时,如果看到有library cache 这样的Latch争用,就可以断定是共享池中出现了问题,这种问题基本是由SQL语句导致的,比如没有绑定变量或者一些存储过程被反复分析。
4.2 数据缓冲池Latch争用
访问频率非常高的数据块被称为热快(Hot Block),当很多用户一起去访问某几个数据块时,就会导致一些Latch争用,最常见的latch争用有:
(1) buffer busy waits
(2) cache buffer chain
这两个Latch的争用分别发生在访问数据块的不同时刻。
Oracle 常见的33个等待事件
http://davedba.com/oracle-common-33-waiting-for-events.html
当一个会话需要去访问一个内存块时,它首先要去一个像链表一样的结构中去搜索这个数据块是否在内存中,当会话访问这个链表的时候需要获得一个Latch,如果获取失败,将会产生Latch cache buffer chain等待,导致这个等待的原因是访问相同的数据块的会话太多或者这个列表太长(如果读到内存中的数据太多,需要管理数据块的hash列表就会很长,这样会话扫描列表的时间就会增加,持有chache buffer chain latch的时间就会变长,其他会话获得这个Latch的机会就会降低,等待就会增加)。
当一个会话需要访问一个数据块,而这个数据块正在被另一个用户从磁盘读取到内存中或者这个数据块正在被另一个会话修改时,当前的会话就需要等待,就会产生一个buffer busy waits等待。
产生这些Latch争用的直接原因是太多的会话去访问相同的数据块导致热快问题,造成热快的原因可能是数据库设置导致或者重复执行的SQL 频繁访问一些相同的数据块导致。
热快产生的原因不尽相同,按照数据块的类型,可以分成一下几种类型,不同热快类型处理的方式都是不同的。
(1) 表数据块
(2) 索引数据块
(3) 索引根数据块
(4) 文件头数据块
4.2.1 表数据块
比如在OLTP系统中,对于一些小表,会给出某些数据块被频繁查询或者修改的操作,这时候,这些被频繁访问的数据块就会变成热块,导致内存中Latch争用。
如果出现这样热块的情况,并且表不太大,一个方法是可以考虑将表数据分布在更多的数据块上,减少数据块被多数会话同时访问的频率。
可以通过一下命令将每个数据块存放记录的数量减少到最少:
Alter table minimize records_per_block;
我们把数据分布到更多的数据块上,大大降低了一个数据块被重复读取的概率。 但是这种方法的缺点很明显,就是降低了数据的性能,在这种情况下,访问相同的数据意味着需要读取更多的数据块,性能会有所降低。
4.2.2 索引数据块
这样的情况通常发生在一个RAC架构里,某个表的索引键值出现典型的“右倾”现象,比如一个表的主键使用一个序列来生成键值,那么在这个主键在索引数据块上的键值就是以一种顺序递增的方式排列的,比如:1,2,3,4,5….,由于这些键值分布得非常接近,当许多用户在RAC的不同实例来向表中插入主键时,就会出现相同的索引数据块在不同实例的内存中被调用,形成一种数据块的争用,对于这种情况,使用反向索引可以缓解这种争用。 反向索引是将从前的索引键值按照反向的方式排列,在正常的主键B-Tree索引中,键值会按照大小的顺序排列,比如:1234,反向索引,键值就变成4321.
这样,本来是放在相同的索引数据块上的键值,现在分布熬不同的数据块上,这样用户在RAC不同的实例上插入的主键值因为分布在不同的数据块上,所以不会导致热块的产生,这基本是反向索引被使用的唯一情况。
反向索引使用场合之所以如此受限制,是因为它丢弃了B-Tree 索引的一个最重要的功能:
Index range scan
索引访问方式中,这个方式最常见,但是反向索引却不能使用这个功能,因为反向索引已经把键值的排列顺序打乱,当按照键值顺序查找一个范围时,在反向索引中,由于键值被反向存储,这些值已经不是连续存放的了。 所以Index range scan 的方式在反向索引中没有任何意义。在反向索引中只能通过全表扫描或者全索引扫描的方式来实现。 这就是反向索引的一个非常严重的缺陷。
Oracle 索引 详解
http://davedba.com/oracle-index-details.html
4.2.3 索引根数据块
热块也可能发生在索引的根数据块上。 在B-Tree索引里,当Oracle 访问一个索引键值时,首先访问索引的根,然后是索引的分支,最后才是索引的叶块。索引的键值就是存储在叶块上面。 如图:
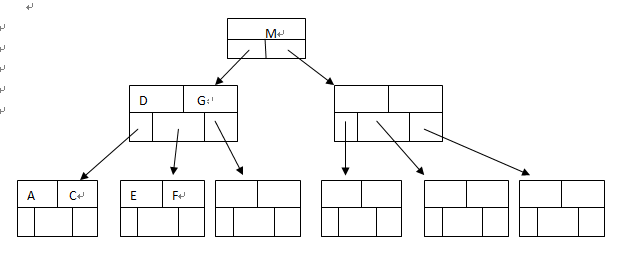
当索引的根,枝数据都集中在几个数据块上时,比如D,G所在的枝数据块,当用户访问的范围从A-F,都会访问这个数据块,如果很多用户频繁的访问这个范围的索引键值,有可能导致这个枝数据块变成热快。
当出现这种现象时,可以考虑对索引做分区,以便于使用这些根,枝数据块分布到不同的数据段(分区)上,减少数据块的并行访问的密度,从而避免由于索引根,枝数据块太集中导致热块产生。
4.2.4 段头数据块
在Oracle 9i 之前,数据块的空间使用情况需要手工来管理,在每个数据段的段头有一个或者几个Free list 列表,用于存放段中哪些数据块可以使用。
当数据块的数据达到数据块总容量的一个比例时(PCT_FREE 参数决定),数据块就会从Free list中删除,这个数据块就不能在插入数据。
当数据块的空间减少到一个比例时(PCT_USED参数决定),数据块就会被放到Free list列表中,这些数据库可以被用来插入数据。
在OLTP系统中,一些数据段的Free List可能会是一个访问很频繁的数据块,比如这个数据库上有些表有很多删除,插入的动作,很多会话需要不断访问这些数据块的Free List列表,以便获得需要的数据块信息。此时这个数据块(称作段头数据块)就会变成一个热块,此时内存中就会出现如cacha buffer chain这样的Latch等待事件。
当出现这个问题时,一个常见的解决方法是增加Free List的数量,以便于分散会话访问数据块的密度。
从Oracle 9i开始,引入了一个自动段管理的技术ASSM(Automatic Segment Space Management: ASSM),它让Oracle 自动管理“Free List”。 实际上在ASSM里,已经没有Free List 这样的结构,Oracle使用位图方式来标记数据块是否可用,这种数据块的空间管理方式比用一个列表来管理效率更高。
关于ASSM 可以参考Oracle 官方连接文档。 可以可以参考我的Blog:
Oracle 自动段空间管理(ASSM:auto segment space management)
http://davedba.com/oracle-automatic-segment-space-management-assmauto-segment-space-management.html
对于OLTP系统,表的DML操作非常密集,对于这些表,使用ASSM方式来管理会比人工管理更加方便和准确,能有效的避免段头变成热块。
对于OLAP系统,这个参数并没有太大的实际意义,因为在这样的数据库中,很少有表发生频繁的修改,OLAP系统主要的工作是报表和海量数据的批量加载。
PS:
整理这篇文章花费了4天的时间,应该是比较长的的。 首先是自己要理解这些内容,然后要用一定的组织形式把这些内容整理出来,通俗易懂。而且这些内容又比较抽象,费了不少功夫,不过整理之后,再次看的时候就会清楚很多。 最后还是那句话,随着时间的推移,对Oracle 的理解也在慢慢变化,以后可能有更加深刻的理解。