datastage transformer控件详解
序言
在之前的工作中,用到的都是一些很简单的transformer的转换功能,比如直接加一些函数做一些判断然后输出,或者构造一些列!没有用到他的loop功能及stage variable功能,这篇主要是对他们的学习
transformer基本功能回顾
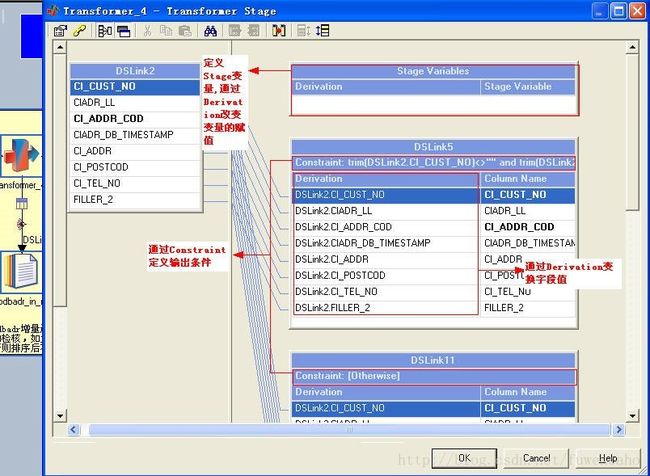
Constraint通过限定条件使符合条件的数据输出到这个output link。
Derivation通过定义表达式来转换字段值。
在Constraint及Derivation中可以使用Job parameters及Stage Variables。
Ø 注意:Transformer Stage功能强大,但在运行过程中是以牺牲速度为代价的。在只有简单的变换,拷贝等操作时,最好用Modify Stage,Copy Stage,Filter Stage等来替换Transformer Stage。
循环的使用
例子一

循环实际讲解
Defining a loop condition
You specify that the Transformer stage loops when processing each input row by defining a loop condition. The loop continues to iterate while the condition is true.
About this task
To define a loop condition:
Procedure
- If required, open the Loop Condition grid by clicking the arrow on the title bar.
- Double-click the Loop While condition, or type CTRL-D, to open the expression editor.
- In the expression editor, specify the expression that controls your loop. The expression must return a result of true or false.
What to do next
It is possible to define a faulty loop condition that results in infinite looping, and yet still compiles successfully. To catch such events, you can specify a loop iteration warning threshold in the Loop Variable tab of the Stage Properties window. A warning is written to the job log when a loop has repeated the specified number of times, and the warning is repeated every time a multiple of that value is reached.
So, for example, if you specify a threshold of 100, warnings are written to the job log when the loop iterates 100 times, 200 times, 300 times, and so on. Setting the threshold to 0 specifies that no warnings are issued. The default threshold is 10000, which is a good starting value. You can set a limit for all jobs in your project by setting the environment variable APT_TRANSFORM_LOOP_WARNING_THRESHOLD to a threshold value.
The threshold applies to both loop iteration, and to the number of records held in the input row cache (the input row cache is used when aggregating values in input columns).
Defining loop variables
You can declare and use loop variables within a Transformer stage. You can use the loop variables in expressions within the stage.
About this task
You can use loop variables when a loop condition is defined for the Transformer stage. When a loop is defined, the Transformer stage can output multiple rows for every row input to the stage. Loop variables are evaluated every time that the loop is iterated, and so can change their value for every output row. Such variables are accessible only from the Transformer stage in which they are declared. You cannot use a loop variable in a stage variable derivation.
Loop variables can be used as follows:
- They can be assigned values by expressions.
- They can be used in expressions which define an output column derivation.
- Expressions evaluating a variable can include other loop variables or stage variables or the variable being evaluated itself.
Any loop variables you declare are shown in a table in the right pane of the links area. The table looks like the output link table and the stage variables table. You can maximize or minimize the table by clicking the arrow in the table title bar.
The table lists the loop variables together with the expressions that are used to derive their values. Link lines join the loop variables with input columns used in the expressions. Links from the right side of the table link the variables to the output columns that use them, or to the stage variables that they use.
To declare a loop variable:
Procedure
Example
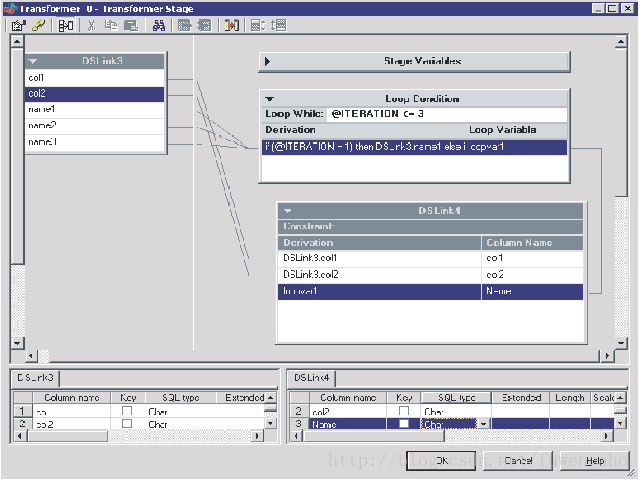
1:Loop example: converting a single row to multiple rows
You can use the Transformer stage to convert a single row for data with repeating columns to multiple output rows.
Input data with multiple repeating columns
When the input data contains rows with multiple columns containing repeating data, you can use the Transformer stage to produce multiple output rows: one for each of the repeating columns.
| Col1 | Col2 | Name1 | Name2 | Name3 |
|---|---|---|---|---|
| abc | def | Jim | Bob | Tom |
| Col1 | Col2 | Name |
|---|---|---|
| abc | def | Jim |
| abc | def | Bob |
| abc | def | Tom |
- Loop condition
-
Enter the following expression as the loop condition.
Because each input row has three columns containing names, you need to process each input row three times and create three separate output rows.@ITERATION <= 3 - Loop variable
-
Define a loop variable to supply the value for the new column Name in your output rows. The value of
LoopVar1is set by the following expression:
IF (@ITERATION = 1) THEN inlink.Name1 ELSE IF (@ITERATION = 2) THEN inlink.Name2 ELSE inlink.Name3 - Output link metadata and derivations
-
Define the output link columns and their derivations:
- Col1 - inlink.col1
- Col2 - inlink.col2
- Name - LoopVar1
You can use the Transformer stage to convert a single row for data with repeating values in a single column to multiple output rows.
Input data with multiple repeating values in a single field
When you have data where a single column contains multiple repeating values that are separated by a delimiter, you can flatten the data to produce multiple output columns: one for each of the delimited values. You can also specify that certain values are filtered out, and not have a new row created.| Col1 | Col2 | Names |
|---|---|---|
| abc | def | Jim/Bob/Tom |
| Col1 | Name |
|---|---|
| abc | Bob |
| abc | Tom |
- Stage variable
-
Define a stage variable to hold a count of the fields separated by the delimiter character. The value of
StageVar1 is set by the following expression:
DCOUNT(inlink.Names, "/") - Loop condition
-
Enter the following expression as the loop condition:
The loop continues to iterate for the count in the Names column.@ITERATION <= StageVar1 - Loop variable
-
Define a loop variable to supply the value for the new column Name in your output rows. The value of
LoopVar1 is set by the following expression:
This expression extracts the substrings delimited by the slash character (/) from the input column.FIELD(inlink.Names, "/", @ITERATION, 1) - Output link constraint
-
Define an output link constraint to filter out the name Jim. Use the following expression to define the constraint:
LoopVar1 <> "Jim" - Output link metadata and derivations
-
Define the output link columns and their derivations. Drop the Col2 column by not including it in the metadata.
- Col1 - inlink.col1
- Name - LoopVar1
3:Loop example: generating new rows
You can use the Transformer stage to generate new rows, based on the value of a column in the input row.
Value in an input row column used to generate new output rows
You can use the Transformer stage to generate new rows, based on values held in an input column.| Col1 | Col2 | MaxCount |
|---|---|---|
| abc | def | 5 |
| Col1 | Col2 | EntryNumber |
|---|---|---|
| abc | def | 1 |
| abc | def | 2 |
| abc | def | 3 |
| abc | def | 4 |
| abc | def | 5 |
- Loop condition
-
Enter the following expression as the loop condition:
For each input row, the loop iterates the number of times defined by the value of the MaxCount column.@ITERATION <= inlink.MaxCount - Output link metadata and derivations
-
Define the output link columns and their derivations:
- Col1 - inlink.Col1
- Col2 - inlink.Col2
- EntryNumber - @ITERATION
4:Loop example: aggregating data
You can use the Transformer stage to add aggregated information to output rows.
Aggregation operations make use of a cache that stores input rows. You can monitor the number of entries in the cache by setting a threshold level in the Loop Variable tab of the Stage Properties window. If the threshold is reached when the job runs, a warning is issued into the log, and the job continues to run.
Input row group aggregation included with input row data
You can save input rows to a cache area, so that you can process this data in a loop.For example, you have input data that has a column holding a price value. You want to add a column to the output rows. The new column indicates what percentage the price value is of the total value for prices in all rows in that group. The value for the new Percentage column is calculated by the following expression.
(price * 100)/sum of all prices in group| Col1 | Col2 | Price |
|---|---|---|
| 1000 | abc | 100.00 |
| 1000 | def | 20.00 |
| 1000 | ghi | 60.00 |
| 1000 | jkl | 20.00 |
| 2000 | zyx | 120.00 |
| 2000 | wvu | 110.00 |
| 2000 | tsr | 170.00 |
(price * 100)/200(price * 100)/400| Col1 | Col2 | Price | Percentage |
|---|---|---|---|
| 1000 | abc | 100.00 | 50.00 |
| 1000 | def | 20.00 | 10.00 |
| 1000 | ghi | 60.00 | 30.00 |
| 1000 | jkl | 20.00 | 10.00 |
| 2000 | zyx | 120.00 | 30.00 |
| 2000 | wvu | 110.00 | 27.50 |
| 2000 | tsr | 170.00 | 42.50 |
To implement this scenario in the Transformer stage, make the following settings:
- Stage variable
-
Define the following stage variables:
- NumSavedRows
- SaveInputRecord()
- IsBreak
- LastRowInGroup(inlink.Col1)
- TotalPrice
- IF IsBreak THEN SummingPrice + inlink.Price ELSE 0
- SummingPrice
- IF IsBreak THEN 0 ELSE SummingPrice + inlink.Price
- NumRows
- IF IsBreak THEN NumSavedRows ELSE 0
- Loop condition
-
Enter the following expression as the loop condition:
The loop continues to iterate for the count specified in the NumRows variable.@ITERATION <= NumRows - Loop variables
-
Define the following loop variable:
- SavedRowIndex
- GetSavedInputRecord()
- Output link metadata and derivations
-
Define the output link columns and their derivations:
- Col1 - inlink.Col1
- Col2 - inlink.Col2
- Price - inlink.Price
- Percentage - (inlink.Price * 100)/TotalPrice
SaveInputRecord() is called in the first Stage Variable (NumSavedRows). SaveInputRecord() saves the current input row in the cache, and returns the count of records currently in the cache. Each input row in a group is saved until the break value is reached. At the last value in the group, NumRows is set to the number of rows stored in the input cache. The Loop Condition then loops round the number of times specified by NumRows, calling GetSavedInputRecord() each time to make the next saved input row current before re-processing each input row to create each output row. The usage of the inlink columns in the output link refers to their values in the currently retrieved input row, so will change on each output loop.
Caching selected input rows
You can call the SaveInputRecord() within an expression, so that input rows are only saved in the cache when the expression evaluates as true.
For example, you can implement the scenario described, but save only input rows where the price column is not 0. The settings are as follows:
- Stage variable
-
Define the following stage variables:
- IgnoreRow
- IF (inlink.Price = 0) THEN 1 ELSE 0
- NumSavedRows
- IF IgnoreRecord THEN SavedRowSum ELSE SaveInputRecord()
- IsBreak
- LastRowInGroup(inlink.Col1)
- SavedRowSum
- IF IsBreak THEN 0 ELSE NumSavedRows
- TotalPrice
- IF IsBreak THEN SummingPrice + inlink.Price ELSE 0
- SummingPrice
- IF IsBreak THEN 0 ELSE SummingPrice + inlink.Price
- NumRows
- IF IsBreak THEN NumSavedRows ELSE 0
- Loop condition
-
Enter the following expression as the loop condition:
@ITERATION <= NumRows - Loop variables
-
Define the following loop variable:
- SavedRowIndex
- GetSavedInputRecord()
- Output link metadata and derivations
-
Define the output link columns and their derivations:
- Col1 - inlink.Col1
- Col2 - inlink.Col2
- Price - inlink.Price
- Percentage - (inlink.Price * 100)/TotalPrice
This example produces output similar to the previous example, but the aggregation does not include Price values of 0, and no output rows with a Price value of 0 are produced.
-----------
Outputting additional generated rows
This example is based on the first example, but, in this case, you want to identify any input row where the Price is greater than or equal to 100. If an input row has a Price greater than or equal to 100, then a 25% discount is applied to the Price and a new additional output row is generated. The Col1 value in the new row has 1 added to it to indicate an extra discount entry. The original input row is still output as normal. Therefore any input row with a Price of greater than or equal to 100 will produce two output rows, one with the discounted price and one without.
The input data is as shown in the following table:
| Col1 | Col2 | Price |
|---|---|---|
| 1000 | abc | 100.00 |
| 1000 | def | 20.00 |
| 1000 | ghi | 60.00 |
| 1000 | jkl | 20.00 |
| 2000 | zyx | 120.00 |
| 2000 | wvu | 110.00 |
| 2000 | tsr | 170.00 |
| Col1 | Col2 | Price | Percentage |
|---|---|---|---|
| 1000 | abc | 100.00 | 50.00 |
| 1001 | abc | 75.00 | 50.00 |
| 1000 | def | 20.00 | 10.00 |
| 1000 | ghi | 60.00 | 30.00 |
| 1000 | jkl | 20.00 | 10.00 |
| 2000 | zyx | 120.00 | 30.00 |
| 2001 | zyx | 90.00 | 30.00 |
| 2000 | wvu | 110.00 | 27.50 |
| 2001 | wvu | 82.50 | 27.50 |
| 2000 | tsr | 170.00 | 42.50 |
| 2001 | tsr | 127.50 | 42.50 |
To implement this scenario in the Transformer stage, make the following settings:
- Stage variable
-
Define the following stage variables:
- NumSavedRowInt
- SaveInputRecord()
- AddRow
- IF (inlink.Price >= 100) THEN 1 ELSE 0
- NumSavedRows
- IF AddRow THEN SaveInputRecord() ELSE NumSavedRowInt
- IsBreak
- LastRowInGroup(inlink.Col1)
- TotalPrice
- IF IsBreak THEN SummingPrice + inlink.Price ELSE 0
- SummingPrice
- IF IsBreak THEN 0 ELSE SummingPrice + inlink.Price
- NumRows
- IF IsBreak THEN NumSavedRows ELSE 0
- Loop condition
-
Enter the following expression as the loop condition:
The loop continues to iterate for the count specified in the NumRows variable.@ITERATION <= NumRows - Loop variables
-
Define the following loop variables:
- SavedRowIndex
- GetSavedInputRecord()
- AddedRow
- LastAddedRow
- LastAddedRow
- IF (inlink.Price < 100) THEN 0 ELSE IF (AddedRow = 0) THEN 1 ELSE 0
- Output link metadata and derivations
-
Define the output link columns and their derivations:
- Col1 - IF (inlink.Price < 100) THEN inlink.Col1 ELSE IF (AddedRow = 0) THEN inlink.Col1 ELSE inlink.Col1 + 1
- Col2 - inlink.Col2
- Price - IF (inlink.Price < 100) THEN inlink.Price ELSE IF (AddedRow = 0) THEN inlink.Price ELSE inlink.Price * 0.75
- Percentage - (inlink.Price * 100)/TotalPrice
SaveInputRecord is called either once or twice depending on the value of Price. When SaveInputRecord is called twice, in addition to the normal aggregation, it produces the extra output record with the recalculated Price value. The Loop variable AddedRow is used to evaluate the output column values differently for each of the duplicate input rows.
Runtime errors
The number of calls to SaveInputRecord() and GetSavedInputRecord() must match for each loop. You can call SaveInputRecord() multiple times to add to the cache, but once you call GetSavedInputRecord(), then you must call it enough times to empty the input cache before you can call SaveInputRecord() again. The examples described can generate runtime errors in the following circumstances by not observing this rule:
- If your Transformer stage calls GetSavedInputRecord before SaveInputRecord, then a fatal error similar to the following example is reported in the job log:
APT_CombinedOperatorController,0: Fatal Error: get_record() called on record 1 but only 0 records saved by save_record() - If your Transformer stage calls GetSavedInputRecord more times than SaveInputRecord is called, then a fatal error similar to the following example is reported in the job log:
APT_CombinedOperatorController,0: Fatal Error: get_record() called on record 3 but only 2 records saved by save_record() - If your Transformer stage calls SaveInputRecord but does not call GetSavedInputRecord, then a fatal error similar to the following example is reported in the job log:
APT_CombinedOperatorController,0: Fatal Error: save_record() called on record 3, but only 0 records retrieved by get_record() - If your Transformer stage does not call GetSavedInputRecord as many times as SaveInputRecord, then a fatal error similar to the following example is reported in the job log:
APT_CombinedOperatorController,0: Fatal Error: save_record() called on record 3, but only 2 records retrieved by get_record()
转换的记忆功能
DataStage 的转换有记忆和对键(Key)变化的探测功能。多年来,ETL专家们用一些众所周知的变通方法通过手工编码为DataStage实现同样的功能。在一个DataStage的工作中,一个键的变化包括了拥有同一键的多项纪录,我们要将这些纪录作为一个数组来处理.
在一个转换中有两个新的缓存 ― SaveInputRecord()和GetSavedInputRecord(),你可以保存一条记录并在以后取出,用来比较两个或更多的转换器中的记录。
针对循环和键变化探测有新的系统变量 ― @ITERATION, LastRow()显示同样键中的最后一行,LastTwoInGroup(InputColumn)显示一个指定列的值是否在下一纪录有变化.
下面是一个计算合计的例子,这里根据键的变化, 循环处理每个行并计算每个键的合计.

http://pic.dhe.ibm.com/infocenter/iisinfsv/v8r5/index.jsp?topic=%2Fcom.ibm.swg.im.iis.ds.parjob.dev.doc%2Ftopics%2Fspecifyingaloopcondition.html
--
http://pic.dhe.ibm.com/infocenter/iisinfsv/v8r7/index.jsp?topic=%2Fcom.ibm.swg.im.iis.ds.parjob.dev.doc%2Ftopics%2Fc_deeref_Functions_functions.html
--
http://pic.dhe.ibm.com/infocenter/iisinfsv/v8r5/index.jsp?topic=%2Fcom.ibm.swg.im.iis.ds.parjob.dev.doc%2Ftopics%2Fspecifyingaloopexample4.html