DEDECMS之九 文章采集
到很多网友都为织梦(DEDECMS)的采集教程头疼,的确,官方出的教程太笼统了,什么都没说,换个网站你什么都做不了,这个教程是最详尽的教程,让你一看即会!
一、列表采集
第一步、我们打开织梦后台点击采集——采集节点管理——增加新节点
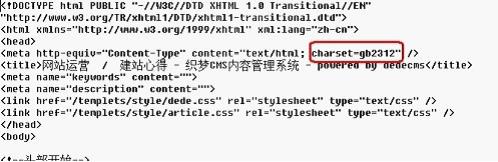

第七步、填写文章网址匹配规则了,回到文章列表页
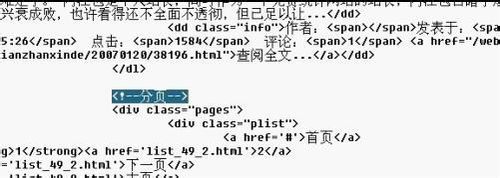
右键查看源文件找到区域开始的HTML,就是找文章列表开始的标志。
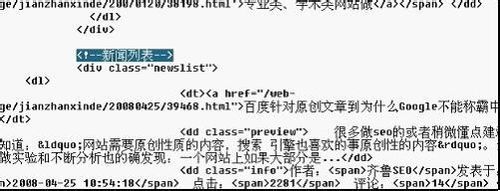
我们很容易的找到了如图中的“新闻列表”。从这里开始,后面就是文章列表里,再找文章列表结束的HTML
就是这个了,一个很容易找到的标志
如果链接中含有图片:
不处理采集为缩略图这里根据自己的需要选择
二、内容页采集
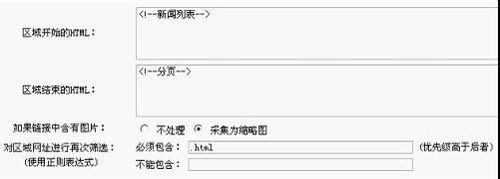
第八步、对区域网址进行再次筛选:
(使用正则表达式)必须包含:(优先级高于后者)
不能包含:打开源文件,我们可以很清楚的看到,文章链接都是以.html结束的所以,我们在必须包含后面填.html如果遇到有些列表很麻烦,还可以填写后面的不能包含
点击保存设置进入下一步,可以看到我们获得的文章网址
看到这些就是对的了,我们保存信息进入下一步设置内容字段获取规则
我们看看文章有没有分页,随便进入一篇文章看看。。我们看到这里的文章没有分页
所以这里的我们就默认了
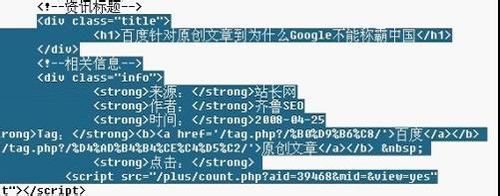
我们现在来找文章标题等等随便进入一篇文章,右键查看源文件
看看这些
依照源码填写

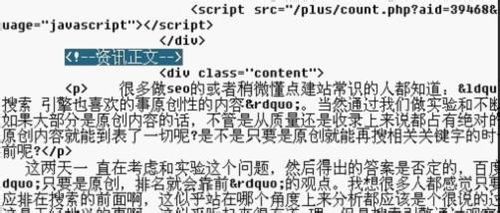
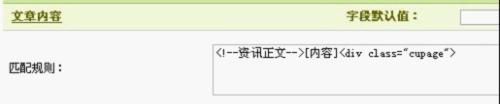
第九步、填写文章内容的开始,结束和上面的一样,找到开始和结束标志.
开始部分如图
结束部分如图
最后填写如图
第十步、你想过滤文章中的什么内容就到过滤规则里写吧,比如要过滤文章中的图片,
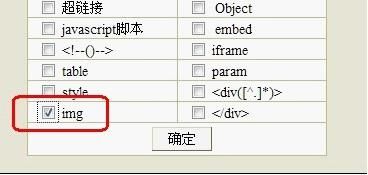
选择常用规则,如图
再勾选IMG,如图
然后确定
这样我们就把正文中的图片过滤了
第十一步、设置完毕后点保存设置并预览,如图
这样一个采集规则就写好了,很简单吧有些网站很难写,可要多下点功夫了哦
我们点保存并开始采集——开始采集网页一会的功夫就采集完了
看看我们采集到的文章
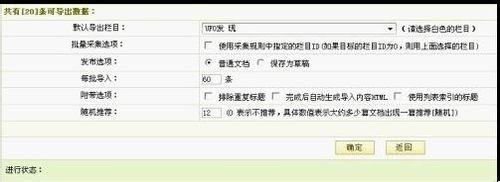
最后、导出数据
首先选择要导入到的栏目,按“请选择”那里即可在弹出的窗口中选择你需要导入的栏目发布选项这里一般默认即可,除非你不想马上发布。每批导入默认是30条,这里修改与否都无所谓,附带选项一般选“排除重复标题”,至于自动生成HTML那个选项建议先别生成,因为我们还要去批量提取摘要和关键字。
文章标题
匹配规则:<title>[内容]</title>
过滤规则:{dede:trimreplace=""}_XXX网站{/dede:trim}
来自百度http://jingyan.baidu.com/article/642c9d34ab179b644a46f782.html
三、采集规则补充
(一)文字过滤与替换的方法
1.去除超链接,这种最常用。
{dede:trim replace=”}<a([^>]*)>{/dede:trim}
{dede:trim replace=”}</a>{/dede:trim}
如果填成这样,那就把链接的文本也一起去掉了
{dede:trim replace=”}<a([^>]*)>(.*)</a>{/dede:trim}
2.过滤JS调用广告,比如GG的广告,就加个这样的:
{dede:trim replace=”}<script([^>]*)>(.*)</script>{/dede:trim}
3.过滤div标签。
这个很重要,如果没过滤干净则可能使发布出来的文章版面错位, 目前大多数遇到采集后错位的原因在此。
{dede:trim replace=”}<div([^.]*)>{/dede:trim}
{dede:trim replace=”}</div>{/dede:trim}
有的时候也需要这样子过滤:
{dede:trim replace=”}<div 选择器>(.*)</div>{/dede:trim}
4.其它的过滤规则可以照以上规律进行推出。
5.过滤摘要和关键字使用,经常要用到。
{dede:trim replace=”}{/dede:trim}
6.简单替换。
{dede:trim replace=’替换后的词语’}要替换的词语{/dede:trim}
采集的内容当然也要求搜索引擎收录, 过滤和替换目的是减少重复,进行伪原创,如何具体的操作,就看个人的要求与喜好了。
(二)内容页指定作者、来源
指定value值即可实现:
{dede:item field='writer' value='小军' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='军事网' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}