Instagram的持续部署
在Instagram,我们每天要将后端代码部署30-50次(每当工程师将改动提交到主分支以后,就要重新部署)。其中的大部分部署是不需要人为干预的。尽管这种做法看起来很疯狂,尤其是在Instagram目前的规模情况下,它却工作的很好。本文就介绍了我们是如何实现该系统并使得它能够很好的工作的。
我们为什么要实现这样的系统
对于我们而言,持续部署有很多好处:
- 它使得我们的工程人员可以快速开发。他们可以不受限于每天只能在固定的时间进行固定次数的部署;相反,他们可以在任何有需要的时候部署代码。这就意味着,他们不需要浪费太多时间,而且能够快速的针对变化进行迭代。
- 它使得识别错误提交变得更加容易。持续部署使得工程人员不再需要深入分析上千次的提交才能找到一个新错误的根源。相反的,他们只需要分析一次或者最多2-3次的提交即可找到错误的原因。当你以后发现一个错误需要去调试时,该方法也会非常有用。指明该问题的量度或数据可被用于识别一个精确的开始时间。而从中,我们就可以找到该时间有哪些提交被部署。
- 错误提交可以很快被检测到并进行处理。这就意味着我们不会导致主分支一团混乱,从而导致其他不相关变化的部署时间的巨大延迟。我们总是处于一种可以迅速解决问题的状态。
实现
该实现的成功主要归功于构造的迭代方法。相比于额外的独立构造该系统然后再直接将旧系统全部转换过来的方法,我们采用了迭代策略——针对当前机制进行不断修改,直到他们变成持续部署。
之前的工作机制
在持续部署实现之前,工程师们是依据各自的需要来部署变化的。在代码改动后,如果他们想将其尽快部署,工程师们会运行一次rollout。否则,他们会等待其他的工程师来运行rollout。这时候,工程师们需要知道如何进行小规模的测试:他们首先会针对一台机器进行rollout,登录该机器并检查日志;然后,他们再运行针对整个系统的第二轮rollout。这个过程被实现为了一个Fabric脚本,而且我们拥有一个简单的数据库和UI——Sauron来存储rollout的日志。
金丝雀版本和测试
第一步就是添加金丝雀——脚本化需要工程师完成的工作。不再针对单个机器运行单独的rollout,将脚本部署到金丝雀机器,跟踪用户日志,然后决定是否继续进行全面部署。接下来,针对金丝雀机器进行一些基本分析:一个脚本分析每个请求的HTTP状态代码,将其分类并使用硬编码的百分比阈值(例如,少于0.5%的5xx,至少90%的2xx)。然后,它只会在超过阈值时向用户发出警告。
我们已经有了一个测试套件,但工程师只在他们的部署机器上运行该套件。代码审查人员不得不相信编码人员的话,认为测试已经通过。而且,我们并不知道提交到主分支后的测试状态。因此,我们安装了Jenkins来测试主分支上新的提交,并将结果报告给Sauron。Sauron会追踪最近通过测试的提交,并建议在rollout时使用该提交(而非最近的提交)。
Facebook使用Phabricator进行代码审查,并使用了能够和Phabricator很好集成的持续集成系统——Sandcastle。每当一个diff被创建或更新时,我们利用Sandcastle来运行测试,并将结果报告给diff。
自动化
为了能够自动化,我们首先需要完成一些准备工作。我们对rollout添加了一些状态(运行中、结束、错误)。如果之前的rollout不在“结束”状态的话,脚本会发出警告。我们还在UI中添加了一个可以将状态修改为“放弃”的放弃按钮,并使得脚本偶尔去检查状态、做出响应。我们还添加了全部提交跟踪;Sauron不再仅仅保存最近通过测试的提交,它记录了主分支的每一次提交,并知道每个提交的测试状态。
(点击放大图像)
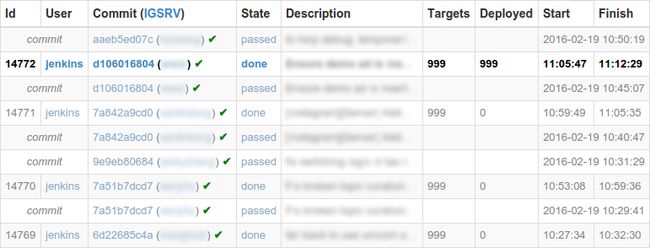
然后,我们将剩余的、需要由人类来定夺的决定自动化。第一个就是究竟选择哪个提交进行rollout。初始算法是总是选择一个通过测试的提交并尽可能的少选——绝对不超过3个。如果每个提交都通过了测试,它每次只选择一个新的提交,而且没有通过测试的连续提交至多只有两个。第二个决定是rollout是否成功。如果超过1%的主机无法部署,该rollout就被认为失败了。
这里,当若干个“yes”出现的时候(接受建议的提交、开始金丝雀版本以及全部署),进行一次rollout。因此,我们允许这些问题可以自动回答,并使得Jenkins运行rollout脚本。刚开始,工程师会在其桌面电脑中监控Jenkins的运行。后来,他们发现自动化完全可以正常进行,便不再监控。
问题
当我们在这个阶段进行持续部署时,过程并不顺利。我们需要解决一些问题。
测试失败
工程师们总会遇到无法通过测试的diff——它们会引起后续的主分支提交无法通过测试,从而使得它们无法部署。相关工程师就需要注意这种情况、撤销引发问题的提交、等待回卷后提交的代码通过测试,并在自动化流程继续之前手动rollout所有积压的提交。这极大的损害了持续部署的主要好处之一——每次rollout部署极少的提交。其问题在于测试非常慢,而且不可靠。为了解决该问题,我们进行了各种优化,将测试时间从12-15分钟缩减到了5分钟,并修复了引起测试框架不可靠的一些问题。
积压
尽管进行了很多改进,我们仍然会遇到很多需要被部署的变化积压在一起的情况。最常见的原因就是金丝雀测试失败(有的是误报,有的是真有问题),当然也有一些其他的原因。当这些问题都被解决以后,自动化的过程就可以继续,每次也只部署一个提交。因此,将积压清除肯定要花费一定的时间,而且会引起新的diff的巨大延迟。这时候,工程师会介入,一次部署所有的积压——这大大损害了持续部署的主要好处之一。
为了改善这种局面,我们在提交选择逻辑中实现了积压处理——当积压出现时,系统自动部署多个提交。其算法的基本想法是为每次提交设定一个时间线(30分钟)。对于队列中的每个提交,它会计算满足时间要求的剩余时间、在剩余时间内能够完成的rollout数目以及每个rollout需要部署的提交数。它会选择最大的提交/rollout值,但上限为3。这使得我们可以在保证提交的rollout时间上限的情况下,完成尽可能多的rollout。
积压的一个特殊原因是随着框架规模的扩大,rollout变得越来越慢。我们已经到了一个尴尬的境地——ssh-agent钳住了整个认证SSH连接的核心,而fab主进程钳住了管理所有任务的核心。其解决方案是切换到Facebook的分布式SSH系统。
指导原则
那么,为了实现我们已经完成的系统,我们需要哪些东西呢?以下就是我们能够使得系统很好工作的一些关键原则,供大家参考:
- 测试:测试套件需要运行速度快。它需要有合适的覆盖率,但并不需要非常完美。测试需要经常运行:代码审查阶段、landing前后。
- 金丝雀:你需要一个自动化的金丝雀,来防止错误提交部署到整个系统。它不需要十分完美,但即使一个简单的统计和阈值集合也就足够了。
- 自动化正常的情况:你不需要自动化每一种情况;只需要自动化已知的、正常的情况。如果出现非正常的情况,将自动化过程停下来加入人工参与。
- 使得人们感觉良好:我认为,这类自动化的一个巨大障碍就是人们觉得失去连接和控制的时候。为了解决该问题,系统需要提供它已经完成、正在进行以及将要进行的工作的内容。它还需要好的停止机制。
- 预见到错误部署:错误的改变总会出现,但没关系。你只需要迅速发现这种情况,并能够迅速回卷。
以上就是很多其他公司都可以实现的内容。持续部署系统不需要复杂。从专注以上原则的简单东西入手,然后慢慢改善。
未来
现在系统运行正常,但我们仍然需要解决一些挑战以及进行一些改善:
- 保持系统快速:Instagram正在快速发展,而提交的速度也会持续增加。我们需要保持rollout的快速,以使得每个rollout的提交数目可以保持在3个以内。一个可能就是将rollout划分成多个阶段,并用流水线来实现。
- 添加金丝雀:随着提交速度的增加,金丝雀失效和积压会越来越影响开发人员。我们希望能够阻止错误提交影响到主分支,从而影响部署。因此,我们正在将金丝雀实现为Landcastle的一部分。在测试通过以后,Landcastle会利用生产环境流量来测试改动。如果改动未通过金丝雀阈值,Landcastle会放弃金丝雀部署。
- 更多的数据:未来,我们希望改进金丝雀的检测能力。因此,我们正在规划收集和检查更多的统计数据,比如每个视图的函数响应代码。我们也正在尝试从一堆控制机器中收集统计数据,并将其与金丝雀统计数据进行比对(而非现在的所采用的,与静态阈值进行比对)。
- 改进探测:如果能够减少没有被金丝雀发现的错误提交的影响,那就最好了。之前,我们总是先在一台机器上进行测试,然后再将其部署到整个系统。未来,我么可以添加更多的中间阶段(一个集群或一个区域),然后在这些阶段检查相关的量度。