Python-Week2-Homework
2.1 在 MONGODB中筛选房源
再在 1-3练习的基础上做修改。获取了url后只需要在获取详情页处添加:
for title,district,img,price,hostName,hostPicSrc,hostSexual in zip(titles,districts,imgs,prices,hostNames,hostPicSrcs,hostSexuals):
data={
'title =':title.get_text(),
'district=':district.get_text().strip(),
'price=': price.get_text(),
'hostName=': hostName.get_text(),
'hostPicSrc=': hostPicSrc.get('src'),
'hostSexual=': GetSuxual(hostSexual.get('class')),
'img=': img.get('src'),
}
sheetTab.insert_one(data)
,然后看到数据库中就把这些添加进去了。

接下来,先把刚才加上去的那句话,sheetTab.insert_one去掉,以免再次运行的时候又反复添加。然后添加筛选条件:
for item in SheetTab.find({'price=':{'$gt':'500'}})
代码
#coding=utf-8
from bs4 import BeautifulSoup
import requests
import time
import pymongo
client = pymongo.MongoClient('localhost',27017)
HouseRent = client['HouseRent']
SheetTab = HouseRent['sheetTab']
url = 'http://bj.xiaozhu.com/search-duanzufang-p1-0/'
header = {
'Content-type': 'text/html;charset=UTF-8',
# 'Referer': 'http://bj.58.com/pbdn/?PGTID=0d409654-01aa-6b90-f89c-4860fd7f9294&ClickID=1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36',
}
#计数的变量
icount = [0]
#获取一个大页面上的详情页地址,并且 判断 当前所抓取的所有url个数是否大于了nbOfUrl
def GetOnePageUrl(url,icount,nbOfUrl):
url_list = []
web_data = requests.get(url,headers = header) # 正常情况下是 Responce[200]
print('请检查当前网络是否正常',web_data.status_code)
soup = BeautifulSoup(web_data.text,'lxml')
urlOnDetail = soup.select('#page_list > ul > li > a ')
#把一个这个页面下的所有详情页的URL装进一个列表里
for urlOnDetail_1 in urlOnDetail:
url_list.append(urlOnDetail_1.get('href'))
#从 urlOnDetail_1里获取数据,装进对象里。或者
icount[0] += 1
if(icount[0] >= nbOfUrl):
break
print('读取URL条数 :',icount[0])
return url_list
#当前页面翻页到下一页
def gotoNextPage(url):
nPage = int(url[-4]) #是否需要添加异常处理.. 如果这个不是数字呢,返回的是什么
a = int(nPage);a += 1
url_s = 'http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(a)
return url_s
#按详情个数去爬,比如爬300条 urls = GetNumberDetail(300) def GetPageUrl_ForPage(nb):
url_ToChange = url
urllist = []
while(icount[0]<nb):
urllist.extend(GetOnePageUrl(url_ToChange, icount, nb))
url_ToChange = gotoNextPage(url)
if(icount[0] > nb):
break
time.sleep(2)
return urllist
#给定大页面个数,按大页面去爬,不管每一页包含有多少详情页
def GetNBPageDetail(nPage):
urllist = []
for i in range(1,nPage+1):
url_ToChange = 'http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(i)
urllist.extend(GetOnePageUrl(url_ToChange, icount,1000000)) #本意是不让这个函数因为到达了nb而跳出,那就把nb设很大
time.sleep(2)
return urllist
#根据传进来的参数来判断性别 #男的是member_ico,女 保存的member_icol
def GetSuxual(strList):
try:
if(len(strList[0])==10):
return '男'
elif(len(strList[0])==11):
return '女'
else:
print('检查一下,性别好像没抓对哦',strList)
return None
except(IndexError):
print('检查一下,性别好像没抓到哦')
return None
#获取一个详情页上的所有信息,并返回一个字典()
def GetOneDetailInfor(url):
#需要获取的数据有: title ,district, price, hostPicSrc,hostSexual,
web_data = requests.get(url,headers=header)
soup = BeautifulSoup(web_data.text,'lxml')
titles = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em')
imgs = soup.select('#curBigImage ')
districts = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span.pr5') #它应该返回的是一个列表
prices = soup.select('#pricePart > div.day_l > span')
hostNames = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a')
hostPicSrcs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img')
hostSexuals = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div') #它根据字符数目来判断
for title,district,img,price,hostName,hostPicSrc,hostSexual in zip(titles,districts,imgs,prices,hostNames,hostPicSrcs,hostSexuals):
data={
'title =':title.get_text(),
'district=':district.get_text().strip(),
'price=': price.get_text(),
'hostName=': hostName.get_text(),
'hostPicSrc=': hostPicSrc.get('src'),
'hostSexual=': GetSuxual(hostSexual.get('class')),
'img=': img.get('src'),
}
SheetTab.insert_one(data)
print(data)
urls = GetNBPageDetail(3) #如果调用这个函数,就是获取前3页的所有详情页url了。
for i,url in zip(range(1,len(urls)+1),urls):
print(i,url)
GetOneDetailInfor(url)
for item in SheetTab.find({'price=':{'$gt':'500'}}):
print(item)
执行结果

总结
1. 如何建立一个本地的mongoDB 数据库文件。
2 将查询得出的数据(字典),装入数据库的表单中。
3 通过PYTHON语句查询我某个数据库文件中的数据
foritem in SheetTab.find()
4 查询可以有筛选条件:
foritem in SheetTab.find(‘words’:0)
foritem in SheetTab.find(‘words’:{‘slt’:2}) # item本身就是字典。
查询的字符:
$lt little than
$ lte littlethan (and) equal
$
2-2 爬取58手机号类目下的所有帖子标题和链接
手动试了一下,大概在116就 停止了,后面的页数,都是4个手机号。
代码
#coding=utf-8
from bs4 import BeautifulSoup
import requests
import time
import pymongo
import sys
client = pymongo.MongoClient('localhost',27017)
cellphoneNb = client['cellphoneNb']
SheetTab2_2 = cellphoneNb['SheetTab2_2']
item_info = cellphoneNb['item_info']
#logfile.writelines('爬了一条')
url = 'http://bj.58.com/shoujihao/pn{}'
header = {
'Content-type': 'text/html;charset=UTF-8',
'Referer': 'http://jplhw.5858.com/?adtype=1&entinfo=409713015672287232_0&psid=109366696191845119978662334',
'User-Agent': 'Mozilla/5.0(Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/49.0.2623.112 Safari/537.36',
}
icount = [0]
#获取一个大页面上的详情页地址,并且 判断 当前所抓取的所有url个数是否大于了nbOfUrl
def GetOnePageUrl(url,icount,nbOfUrl):
logfile = open('E:\\Python-TEST\\WEEK2\\58-CellNB-DEMO.txt', 'a',encoding='utf-8')
web_data = requests.get(url,headers= header) # 正常情况下是 Responce[200]
print('web_data.status_code',web_data.status_code)
soup = BeautifulSoup(web_data.text,'lxml')
titles = soup.select('strong.number') #a.t > strong.number
urlOnDetail = soup.select('a.t ')
if(len(titles)!=len(urlOnDetail)):
print('标题数',len(titles),'链接数 ',len(urlOnDetail))
#把一个这个页面下的所有详情页的URL装进一个列表里
for title,urlOnDetail_1in zip(titles,urlOnDetail):
url_name_list={
'title':list(urlOnDetail_1.get_text().split('\n\n'))[0].strip('\n') if(len(list(urlOnDetail_1.get_text().split('\n\n')))>0) else urlOnDetail_1.get_text().split('\n\n'),
'url':urlOnDetail_1.get('href')
}
#不要置顶的那堆
if('jump'in url_name_list['url']):
print('跳过置顶 ')
else:
SheetTab2_2.insert_one(url_name_list)
icount[0] += 1
print(icount[0],url_name_list)
#来试试把这些东西也写到文件里
logfile.write((str)(icount[0]));logfile.write(',')
logfile.write(((str)(url_name_list['title'])).strip('\n'));logfile.write(',')
logfile.writelines((str)(url_name_list['url']));logfile.write('\n')
print('当前读取URL条数 :',icount[0])
logfile.close()
time.sleep(2)
#当前页面翻页到下一页
def gotoNextPage(url):
nPage = int(url[-4]) #是否需要添加异常处理.. 如果这个不是数字呢,返回的是什么
a =int(nPage);a += 1
url_s = 'http://bj.58.com/shoujihao/pn{}/'.format(a)
return url_s
#获取nPage个页面上的详情页
def GetNBPageDetail(nPage):
urllist = []
for i in range(1,nPage+1):
url_ToChange = 'http://bj.58.com/shoujihao/pn{}'.format(i)
GetOnePageUrl(url_ToChange,icount, 10000000)
time.sleep(2)
return urllist
#获取详情页信息
def GetItemInfo(url):
wb_data = requests.get(url, headers=header)
if wb_data.status_code== 404:
pass
else:
soup =BeautifulSoup(wb_data.text, 'lxml')
data = {
'price':list(soup.select('div.su_con > span')[0].stripped_strings)if(len(soup.select('div.su_con> span'))) else None,
'pub_date':list(soup.select('li.time')[0].stripped_strings)if (len(soup.select('li.time'))) else None,
'area':list(map(lambda x:x.text, soup.select('#main > div.col.detailPrimary.mb15 >div.col_sub.sumary > ul > li > div.su_con > a'))),
'tel':list(soup.select('#t_phone')[0].stripped_strings)if(soup.select('#t_phone')) else None
}
time.sleep(5)
item_info.insert(data)
print(data)
GetNBPageDetail(116)
for url in SheetTab2_2.find():
print(url['url'])
GetItemInfo(url['url'])
#在插件里看到 只有200+条的信息,查询一下到底装进去后
print(SheetTab2_2.find().count())
执行结果
储存url_list的数据库:
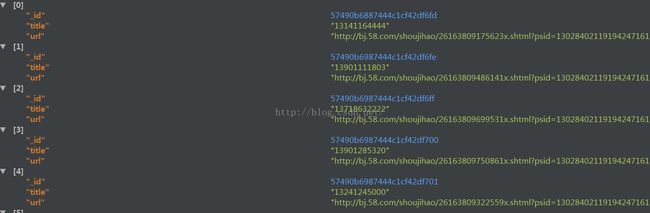
存储item_info的数据库
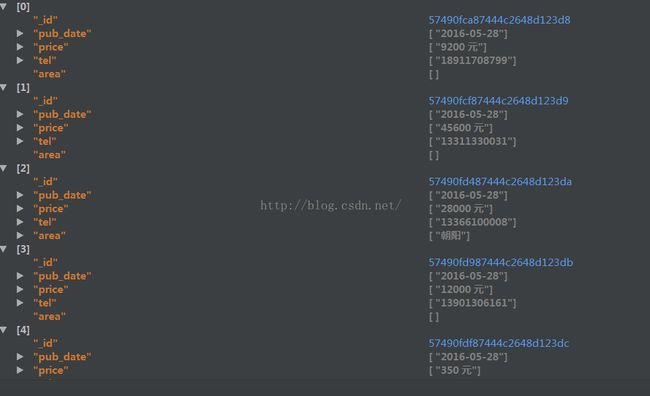
2-3 设置断点续传的功能
老实说…… 我不会…… 于是我去看了参考答案……
以抓取到的手机号为例,我先把所有手机号码的 url存在了名为SheetTab2_2的数据库中。现在我开始获取详情页。中间人为的把程序停止掉,然后再启动程序,查看最终结束后,存储详情页的数据中的count数是否为 3496.
首先需要在获取详情页信息的函数def GetItemInfo(url):中,添加上’url’:url一项
#获取详情页信息
代码
def GetItemInfo(url):
wb_data = requests.get(url, headers=header)
if wb_data.status_code== 404:
pass
else:
soup =BeautifulSoup(wb_data.text, 'lxml')
data = {
'price':list(soup.select('div.su_con > span')[0].stripped_strings)if(len(soup.select('div.su_con> span'))) else None,
'pub_date':list(soup.select('li.time')[0].stripped_strings)if (len(soup.select('li.time'))) else None,
'area':list(map(lambda x:x.text, soup.select('#main > div.col.detailPrimary.mb15 >div.col_sub.sumary > ul > li > div.su_con > a'))),
'tel':list(soup.select('#t_phone')[0].stripped_strings)if(soup.select('#t_phone')) else None,
'url':url
}
time.sleep(5)
item_info.insert(data)
print(data)
然后修改主函数
if __name__ == '__main__':
pool = Pool()
GetNBPageDetail(116)
db_urls = [item['url'] for item in SheetTab2_2.find()]
index_urls = [item['url'] for item in item_info.find()]
x = set(db_urls) # 转换成集合的数据结构
y =set(index_urls)
rest_of_urls = x-y # 相减
for url in rest_of_urls:
print(url)
# GetItemInfo(url)
#在插件里看到 只有200+条的信息,查询一下到底装进去后
print(SheetTab2_2.find().count())
执行结果
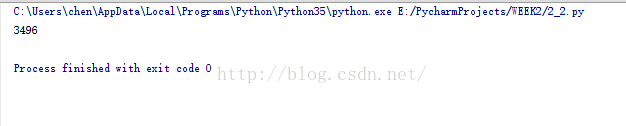
跑的过程同2.3
中间人为停止程序,然后再启动,最后输出item_info的个数,与SheetTab2_2相同,说明没有读到重复的数据。
2.4 大作业
发现手机号的URL地址CSS描述和其他的不一样,所以就先跳过这个,爬取其他的;
2.4.1 将所有类目下url_list存到数据库有中
代码
import requests
from bs4 import BeautifulSoup
import random
import lxml
import time
import pymongo
from multiprocessing import Pool
client = pymongo.MongoClient('localhost',27017)
ganji = client['ganji']
url_list = ganji['url_list']
headers = {
'User-Agent':'Mozilla/5.0(Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/49.0.2623.112 Safari/537.36',
'Connection':'keep-alive' # 这一句是?
}
# http://cn-proxy.com/
proxy_list = [
'http://61.135.217.13:80',
'http://61.135.217.7:80',
'http://180.76.135.145:3128',
]
proxy_ip = random.choice(proxy_list) # 随机获取代理ip
proxies = {'http':proxy_ip}
channel_list = [
'http://bj.ganji.com/jiaju/',
'http://bj.ganji.com/rirongbaihuo/',
'http://bj.ganji.com/shouji/',
#'http://bj.ganji.com/shoujihaoma/', #单独抓一次
'http://bj.ganji.com/bangong/',
'http://bj.ganji.com/nongyongpin/',
'http://bj.ganji.com/jiadian/',
'http://bj.ganji.com/ershoubijibendiannao/',
'http://bj.ganji.com/ruanjiantushu/',
'http://bj.ganji.com/yingyouyunfu/',
'http://bj.ganji.com/diannao/',
'http://bj.ganji.com/xianzhilipin/',
'http://bj.ganji.com/fushixiaobaxuemao/',
'http://bj.ganji.com/meironghuazhuang/',
'http://bj.ganji.com/shuma/',
'http://bj.ganji.com/laonianyongpin/',
'http://bj.ganji.com/xuniwupin/',
'http://bj.ganji.com/qitawupin/',
'http://bj.ganji.com/ershoufree/',
'http://bj.ganji.com/wupinjiaohuan/',
]
index = [1]
#logfile = open('F:\\PythonWebTEST\\week2\\WEEK2_URLLIST.txt','a',encoding='utf-8')
#如果有下一页,返回真,如果没有,返回假
def GetLinkFromChannel(channel, pages,who_sells='o'):
list_view = '{}{}{}/'.format(channel,str(who_sells), str(pages))
wb_data = requests.get(list_view, headers=headers)
tryCount = 1
while(wb_data.status_code== 503):
sleep(5)
wb_data = requests.get(list_view,headers=headers) #, proxies=proxies)
tryCount+= 1
if(tryCount>10):
print('链接超时')
soup = BeautifulSoup(wb_data.text, 'lxml')
for link in soup.select('div dta'): # 大部分用这个是可以得。
item_link= link.get('href')
# url_list.insert_one({'url': item_link})
if(item_link[0:4]=='http'):
print('url',index[0],item_link)
data ={ 'url':item_link,'index':index[0]}
url_list.insert(data)
index[0] += 1
a = soup.select('#wrapper> div.leftBox > div.pageBox > ul > li > a') #第一个就用的
strr = ''
if a:
for i in a:
strr = i.text
if(strr=='下一页'):
print('有下一页,可以继续爬')
returnTrue
else :
print('当前页是最后一页')
return False
#spider1
def GetAllLinkFromChannel(channel):
lasPage = 0
currentPage = 1
while(True):
lasPage =GetLinkFromChannel(channel,currentPage)
print(currentPage)
currentPage += 1
if(lasPage==False):
break;
print(channel,'END')
# spider2
def get_item_info_from(url, data=None):
wb_data = requests.get(url, headers=headers)
if wb_data.status_code== 404:
pass
else:
soup =BeautifulSoup(wb_data.text, 'lxml')
data = {
'title':soup.title.text.strip(),
'price':soup.select('.f22.fc-orange.f-type')[0].text.strip(),
'pub_date':soup.select('.pr-5')[0].text.strip().split(' ')[0],
'area': list(map(lambda x:x.text, soup.select('ul.det-infor > li:nth-of-type(3) > a'))),
'cates': list(soup.select('ul.det-infor> li:nth-of-type(1) > span')[0].stripped_strings),
'url': url
}
print(data)
if __name__ == '__main__':
pool = Pool()
for ind in range(19):
GetAllLinkFromChannel(channel_list[ind])
print('总url条目数 :',url_list.find().count())
运行时截图
结束后,再单独运行一下
GetAllLinkFromChannel(‘http://bj.ganji.com/shoujihaoma/’)
并且将 GetLinkFromChannel函数中,获取URL的方法改为
for link in soup.select('#wrapper > div.leftBox > div.layoutlist > div > div > div > a')
就可以了。最终,打印url_list数据库的个数 ,获取了61338条url,(这么少,是不是漏掉些什么,暂时没有发现)
2.4.2 使用spider2来分别从这些数据库里获得对应的详情页信息
代码
for url in url_list.find():
print(url['url'])
get_item_info_from(url['url'])
def get_item_info_from(url, data=None):
wb_data = requests.get(url, headers=headers)
if wb_data.status_code== 404:
pass
else:
soup =BeautifulSoup(wb_data.text, 'lxml')
data = {
'title':soup.title.text.strip(),
'price':soup.select('.f22.fc-orange.f-type')[0].text.strip()if(len(soup.select('.f22.fc-orange.f-type'))) elseNone,
'pub_date':soup.select('.pr-5')[0].text.strip().split(' ')[0] if(len(soup.select('.pr-5'))) elseNone,
'area': list(map(lambda x:x.text, soup.select('ul.det-infor > li:nth-of-type(3) > a'))),
'cates': list(soup.select('ul.det-infor> li:nth-of-type(1) > span')[0].stripped_strings) if(len(soup.select('ul.det-infor> li:nth-of-type(1) > span'))) else None,
'url': url
}
item_info.insert(data)
print(data)
运行时截图
运行结果
存储URL_LIST的数据库:
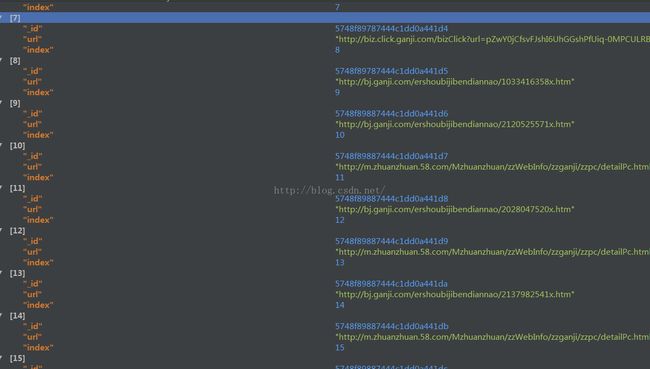
存储详情页的数据库:
…………
加了代理后,没速度,卡着不动 =..= 于是就没用代理了。
试了几次,最远到20000+,总是爬不完,就对方强制关闭了 =..= 要么就是这个错误:

也罢,起码知道方法了,能运行起来所明代码没错。不给赶集服务器增加负担了。有余力了再考虑怎么解决。就先用这2W条数据来进行下一周的学习。
#coding=utf-8
from bs4 import BeautifulSoup
import requests
import time
import pymongo
import sys
client = pymongo.MongoClient('localhost',27017)
cellphoneNb = client['cellphoneNb']
SheetTab2_2 = cellphoneNb['SheetTab2_2']
item_info = cellphoneNb['item_info']
#logfile.writelines('爬了一条')
url = 'http://bj.58.com/shoujihao/pn{}'
header = {
'Content-type': 'text/html;charset=UTF-8',
'Referer': 'http://jplhw.5858.com/?adtype=1&entinfo=409713015672287232_0&psid=109366696191845119978662334',
'User-Agent': 'Mozilla/5.0(Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/49.0.2623.112 Safari/537.36',
}
icount = [0]
#获取一个大页面上的详情页地址,并且 判断 当前所抓取的所有url个数是否大于了nbOfUrl
def GetOnePageUrl(url,icount,nbOfUrl):
logfile = open('E:\\Python-TEST\\WEEK2\\58-CellNB-DEMO.txt', 'a',encoding='utf-8')
web_data = requests.get(url,headers= header) # 正常情况下是 Responce[200]
print('web_data.status_code',web_data.status_code)
soup = BeautifulSoup(web_data.text,'lxml')
titles = soup.select('strong.number') #a.t > strong.number
urlOnDetail = soup.select('a.t ')
if(len(titles)!=len(urlOnDetail)):
print('标题数',len(titles),'链接数 ',len(urlOnDetail))
#把一个这个页面下的所有详情页的URL装进一个列表里
for title,urlOnDetail_1in zip(titles,urlOnDetail):
url_name_list={
'title':list(urlOnDetail_1.get_text().split('\n\n'))[0].strip('\n') if(len(list(urlOnDetail_1.get_text().split('\n\n')))>0) else urlOnDetail_1.get_text().split('\n\n'),
'url':urlOnDetail_1.get('href')
}
#不要置顶的那堆
if('jump'in url_name_list['url']):
print('跳过置顶 ')
else:
SheetTab2_2.insert_one(url_name_list)
icount[0] += 1
print(icount[0],url_name_list)
#来试试把这些东西也写到文件里
logfile.write((str)(icount[0]));logfile.write(',')
logfile.write(((str)(url_name_list['title'])).strip('\n'));logfile.write(',')
logfile.writelines((str)(url_name_list['url']));logfile.write('\n')
print('当前读取URL条数 :',icount[0])
logfile.close()
time.sleep(2)
#当前页面翻页到下一页
def gotoNextPage(url):
nPage = int(url[-4]) #是否需要添加异常处理.. 如果这个不是数字呢,返回的是什么
a =int(nPage);a += 1
url_s = 'http://bj.58.com/shoujihao/pn{}/'.format(a)
return url_s
#获取nPage个页面上的详情页
def GetNBPageDetail(nPage):
urllist = []
for i in range(1,nPage+1):
url_ToChange = 'http://bj.58.com/shoujihao/pn{}'.format(i)
GetOnePageUrl(url_ToChange,icount, 10000000)
time.sleep(2)
return urllist
#获取详情页信息
def GetItemInfo(url):
wb_data = requests.get(url, headers=header)
if wb_data.status_code== 404:
pass
else:
soup =BeautifulSoup(wb_data.text, 'lxml')
data = {
'price':list(soup.select('div.su_con > span')[0].stripped_strings)if(len(soup.select('div.su_con> span'))) else None,
'pub_date':list(soup.select('li.time')[0].stripped_strings)if (len(soup.select('li.time'))) else None,
'area':list(map(lambda x:x.text, soup.select('#main > div.col.detailPrimary.mb15 >div.col_sub.sumary > ul > li > div.su_con > a'))),
'tel':list(soup.select('#t_phone')[0].stripped_strings)if(soup.select('#t_phone')) else None
}
time.sleep(5)
item_info.insert(data)
print(data)
GetNBPageDetail(116)
for url in SheetTab2_2.find():
print(url['url'])
GetItemInfo(url['url'])
#在插件里看到 只有200+条的信息,查询一下到底装进去后
print(SheetTab2_2.find().count())