[CSAPP笔记][第十章 系统级I/O]
第十章 系统级I/O
输入/输出(I/O) : 是指主存和外部设备(如磁盘,终端,网络)之间拷贝数据过程。
高级别
I/O函数scanf和printf<<和>>- 使用系统级
I/O函数实现
系统级
I/O函数。Q:大多数时候高级别I/O函数都运行良好,为什么我们还要学Unix I/OA:
- 了解
Unix I/O将帮助你理解其他的系统概念。
- 要深入理解其他概念,必须理解
I/O。
- 要深入理解其他概念,必须理解
- 有时你除了使用
Unix I/O别无选择
- 标准
I/O库没有提供读取文件元数据的方式。
- 如
文件大小或文件创建时间。
- 如
- 用于
网络编程十分冒险。
- 标准
- 了解
10.1 Unix I/O
一个
Unix 文件就是一个m个字节的序列:
- 所有
I/O设备都被模型化为文件。 - 而所有的输入和输出都被当做相应文件的
读和写。
- 所有
设备优雅地映射成文件,允许Unix内核引出一个简单,低级的应用接口。叫做Unix I/O使得所有的输入输出都能以一种统一且一致的方式来执行。
打开文件: 应用程序要求内核打开文件
内核返回一个小的非负整数,叫做描述符- 等于
内核分配一个文件名,来标示当前的文件。 内核记录有关这个打开文件的所有信息。应用程序只需要记住标示符。
- 等于
Unix外壳创建进程时都有三个打开的文件- 标准输入(标示符
0) - 标准输出(标示符
1) - 标准错误(标示符
2) - 头文件
<unistd.h>定义了常量代替显式的描述符值
STDIN_FILENOSTDOUT_FILENOSTDERR_FILENO
- 标准输入(标示符
改变当前文件的位置(非文件目录)
对于每个打开的文件,内核保持一个
文件位置k- 初始为
0。 文件位置即是从文件开头起始的字节偏移量。
- 初始为
执行
lseek操作,显式地设置文件位置。
读写文件。
一个
读操作就是从文件拷贝n个字节到存储器,然后将k增加到k+n。- 给定一个大小为
m字节的文件,当k>=m时执行读操作会触发一个称 为end-of-file(EOF)的条件。
- 应用程序能检测到这个
条件(或者说信号?) - 文件结尾并没有这样的符号。
- 应用程序能检测到这个
- 给定一个大小为
写操作就是从存储器拷贝n个字节到一个文件,从当前文件位置k开始,然后更新k。
关闭文件 :当应用程序完成了文件的访问,通知
内核关闭文件。响应
内核释放文件打开时创建的数据结构。- 将
描述符恢复到可用的描述符池中。
无论一个进程因为何种原因被关闭,内核会关闭所有它打开的文件。
10.2 打开和关闭文件
进程是通过调用 open函数来打开一个已存在的文件或者创建一个新文件的
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
int open(char *filename,int flags,mode_t mode);
//返回:若成功则为新文件描述符,若出错为-1
open函数将filename转换为一个文件描述符,并且返回描述符数字。
返回的
描述符总是在进程当前没有打开的最小描述符。flags参数指明了进程打算如何访问这个文件:- 可是以一个多个
掩码的或。(拿二进制思想思考) O_RDONLY: 只读O_WRONLY: 只写
O_CREAT: 如果文件不存在,就创建一个截断的(truncated)(空)文件。O_TRUNC: 如果文件已存在,就截断它(长度被截为0,属性不变)O_APPEND: 在每次写操作前,设置文件位置到文件的结尾
O_RDWR: 可读可写例子代码 //已只读模式打开一个文件 fd = Open("foo.txt",O_RDONLY,0); //打开一个已存在的文件,并在后面面添加一个数据 fd = Open("foo.txt",O_WRONLY|O_APPEND,0);
- 可是以一个多个
mode参数指定了新文件的访问权限位。每个进程都有
umask权限掩码,或权限屏蔽字- 所有被设置的权限都要减去这个
权限掩码才是实际权限。
777-022=755或者是777&~022。
- 通过
umask()函数设置
mode并不是实际权限- 文件的权限位被设置为
mode & ~umask,也可以表示两者相减。
- 文件的权限位被设置为
例子
#define DEF_MODE S_IRUSR|S_IWUSER|S_IRGRP|S_IWGRP|S_IROTH|S_IWOTH //所有人都能读和写 #define DEF_UMASK S_IWGRP|S_IWOTH //屏蔽了用户组的写和其他人的写 umask(DEF_UMASK); fd=oepn("foo.txt",O_CREAT|O_TRUNC|O_WRONLY,DEF_MODE); //创建了一个新文件,文件的拥有者有读写权利,其他人只有读权限。(屏蔽了用户组的写和其他人的写)![[CSAPP笔记][第十章 系统级I/O]_第1张图片](http://img.e-com-net.com/image/info5/2cf9c053089447deab3de8bc041c9058.jpg)
close函数关闭一个打开的文件
#include <unistd.h>
int close(int fd);
//返回: 若成功则为0,若出错则为-1
关闭一个已关闭的描述符会出错。
10.3 读和写文件
调用read和write完成输入输出
#include <unistd.h>
ssize_t read(int fd,void *buf,size_t n);
//read函数从描述符fd的当前文件位置拷贝最多n个字节到存储器buf
返回:若成功则为读的字节数,若EOF则为0,若出错为 -1.
ssize_t write(int fd,const void *buf,size_t n)
//write函数从存储器位置buf拷贝至多n个字节到描述符fd的当前文件位置
返回:若成功则为写的字节数,若出错则为-1
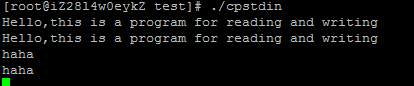
展示了一个程序使用read和write调用一次一个字节的从标准输入拷贝到标准输出。
![[CSAPP笔记][第十章 系统级I/O]_第2张图片](http://img.e-com-net.com/image/info5/2a972b4a44e2449eab306e61d4acc5b3.jpg)
通过调用lseek函数,应用程序能够显示地修改当前文件的位置
ssize_t 和 size_t 有什么区别
- size_t:被定义为
unsigned int- ssize_t:被定义为
int
- 为了出错的时候,返回-1.
- 有趣的是,因为这个-1,使得read的最大值减小了一半。
在某些情况,read和write传送的字节比应用程序要求的要少,有以下原因。
这样的情况返回的值叫做不足值。
- 读时遇到EOF。
从终端读文本行(
stdin和STDIN_FILENO)不足值等于文本行的大小。
读和写网络套接字(
socket)- 内部缓冲约束和较长的网络延迟会引起
read和write返回不足值。 - 你向创建健壮的诸如
Web服务器这样的网络应用,就必须反复调用read和write处理不足值,知道所有需要的字节传送完毕。
- 内部缓冲约束和较长的网络延迟会引起
一般的磁盘文件除了EOF外,一般不会遇到不足值的问题。
10.4 用RIO包健壮地读
RIO包: 全称 Robust I/O包,健壮的I/O包。会自动的处理上文中所述的不足值。
提供两类不同的函数:
无缓冲的输入输出函数
- 直接在存储器和文件之间传送数据,没有应用级缓冲。
- 他们对二进制读写到网络和从网络读写二进制数据尤其有用。
带缓冲的输入函数
- 允许你高效地从文件中读取文本行和二进制数据。
- 这些文件内容
缓存到应用级缓冲区内。
带缓冲的
RIO输入函数是线程安全的,在同一个描述符可以交错调用
10.4.1 RIO的无缓冲的输入输出函数
![[CSAPP笔记][第十章 系统级I/O]_第3张图片](http://img.e-com-net.com/image/info5/ac545b0b84ac4fafa08a13543498e0e9.jpg)
- 与普通
read,write区别
- 在读写
网络套接字的时候不会产生不足值
- 即
rio_writen不可能返回不足值
- 即
- 线程安全的。
- 当
wirte,read被应用信号处理程序的返回中断时,允许手动重启。
- 在读写
源代码
10.4.2 RIO的带缓冲的输入函数
一个文本行就是由一个换行符结尾的ASCII码字符序列。
- 在Unix系统里,换行符(
\n)与ASCII码换行符LF相等,数字值为0x0a
rio_readnb和rio_readlineb 引入
假设我们要编写一个程序计算文本文件中文本行的数量如何实现?
方案1:
read函数一次一个字节地从文件传送到用户存储器,检查每个字节来查找换行符。- 效率低,每读取文件中的一个字符都要求陷入内核。
更好的方法是调用一个包装函数
rio_readlineb。它从一个内部
读缓冲区拷贝一个文本行。- 当缓冲区变空时,会调用
read重新填满缓冲区。
- 当缓冲区变空时,会调用
为什么这样子更快?
- 利用了空间局部性原理
- 使用
rio_readn的带缓冲区版本rio_readnb.
- 对于即包含文本行也包含二进制数据的文件(例如 11.5.3节会提到的
HTTP响应). - 和
rio_readlineb一样的读缓冲区中传送原始字节。
- 对于即包含文本行也包含二进制数据的文件(例如 11.5.3节会提到的
rio_readinitb 和 rio_readnb,rio_readlineb 实例
每打开一个描述符都要调用一次rio_readinitb函数。
- 它将描述符
fd和 地址rp处的一个类型为rio_t的读缓冲区联系起来。
![[CSAPP笔记][第十章 系统级I/O]_第4张图片](http://img.e-com-net.com/image/info5/c9f6431f7da3423fbbd1bec5bdc18c13.jpg)
rio_readlineb(&rio,buf,MAXLINE)函数rio_readlineb函数从rio(缓冲区)读出一个文本行(包括结尾的换行符),将它拷贝到存储器位置buf,并用\0字符结束这个文本行。rio_readlineb最多读MAXLINE-1个字符,其余被截断,末尾永远是\0.
rio_readnb(&rio,buf,n)rio_readnb函数从rio最多读n个字节到buf
对同一描述符,对
rio_readlineb和rio_readnb的调用可以任意交叉。- 但是带缓冲的 和 不带缓冲的 不应该交叉引用。
剩余部分给出大量RIO函数的实例。
![[CSAPP笔记][第十章 系统级I/O]_第5张图片](http://img.e-com-net.com/image/info5/aedeb23857944cb1b40733f8e982c682.jpg)
- 图10-5展示了一个
读缓冲区的格式,以及初始化它的rio_readinitb的代码。
rio_readinitb函数创建了一个空的读缓冲区,并且将一个打开的文件描述符与之关联。
图10-6所示的
rio_read函数是RIO读程序的核心。rio_read是Unix read函数的带缓冲版本。
- 当调用
rio_read要求读n个字节. - 此时如果缓冲区为空,调用
read填满,不过也未必会满。 - 读
缓冲区内min(n,rp->rio_cnt)个未读字节。
- 当调用
对于一个应用程序,
rio_read和Unix read函数拥有相同的语义。只是可能有时返回的
不足值可能会不同。- 所以如果抛开不足值的话,两者是一样的。
- 即包装它,让他读满。
- 即后文的
rio_readn和rio_readnb。
两者的相似性,使得在某些情况也能互相替换。
- 如后文的
rio_readn和rio_readnb。
- 如后文的
10.5 读取文件元数据
应用程序能够通过调用stat和fstate函数,检索到关于文件的信息(有时也称为文件的元数据(metadata))
#include<unistd.h>
#include<sys/stat.h>
int stat(const char *filename,struct stat *buf);
int fstat(int fd,struct stat *buf);
//填写stat数据结构中的各个成员
返回 : 成功0 ,出错-1
![[CSAPP笔记][第十章 系统级I/O]_第6张图片](http://img.e-com-net.com/image/info5/e1135993e46e45f79da9f7276be6c03d.jpg)
st_size成员包含了文件的字节数大小。st_mode成员则编码了文件访问许可位和文件类型
- 文件类型
- 普通类型:就是我们一般所说的
文件 - 目录文件:包含关于其他文件的信息
- 套接字: 是一种用来通过网络与其他进程通信的文件。
- 普通类型:就是我们一般所说的
- Unix提供的
宏指令根据st_mode来确定文件类型,以下是其中一部分。
S_ISREG()#这是一个普通文件吗S_ISDIR()#这是一个目录文件吗S_ISSOCK()#这是一个网络套接字吗- 在
sys/stat.h中定义
- 文件类型
图10-10展示了如何使用宏和stat函数来读取和解释
10.6 共享文件
除非你很清楚内核是如何表示打开的文件,否则文件共享的概念相当难懂。
内核有三个相关的数据结构来表示打开的文件:
描述符表(descriptor table):- 每个进程都有它独立的
描述符表。 - 它的
表项是由进程打开的文件描述符来索引的。 - 每个打开的
描述符表项指向文件表的一个表项。
- 每个进程都有它独立的
文件表:打开文件的集合是由一张文件表表示的。- 所有的进程共享这张表。
- 每个
文件表项的部分组成是
- 当前的文件位置
引用计数(reference count):即当前指向该表项的描述符项数。
- 关闭一个
描述符会减少相应文件表表项中的引用计数。 - 当
引用计数变为0。内核会删除这个文件表表项。
- 关闭一个
- 以及一个指向
v-node表中对应表项的指针。
v-node- 所有的进程共享这张表。
- 每个表项包含
stat结构的大多数信息。
st_modest_size
打开文件有三种可能的情形:
最常见的类型
- 就是打开两个不同的文件,且文件磁盘位置也不一样。
- 没有进行共享.
共享情况1
![[CSAPP笔记][第十章 系统级I/O]_第7张图片](http://img.e-com-net.com/image/info5/1086e180aaf34031bfee1411a7067428.jpg)
- 多个
描述符也可以通过引用不同的文件表表项来引用同一个文件。 - 内容相同,
文件位置不同(指向的磁盘位置是同一块) - 例子
- 如果以同一个
filename调用open两次,就会出现这种情况。 - 每个
描述符都有它自己的文件位置,所以对不同描述符的读操作可以从文件的不同位置获取数据。
- 如果以同一个
子父进程共享情况
![[CSAPP笔记][第十章 系统级I/O]_第8张图片](http://img.e-com-net.com/image/info5/1226e3eb23054896a8baed830f36734d.jpg)
我们也能理解父子进程如何共享文件。
- 调用
fork后,子进程有一个父进程描述符表副本。 父子进程共享相同的打开
文件表。- 共享相同的
文件位置。
- 共享相同的
一个很重要的结果
- 在内核删除对应文件表表项之前,父子进程必须都关闭它们的描述符。
- 不要以为父进程
close(fd 1)就好了。
- 子进程也要
close(fd 1)
- 子进程也要
10.7 I/O 重定向
Unix外壳提供了I/O重定向功能,允许用户将磁盘文件和标准输入输出联系起来。
例如
unix> ls > foo.txt- 使得
shell加载和执行ls程序,将标准输出重定向到磁盘文件foo.txt。
- 使得
一个
Web程序代表客户端允许CGI程序时,也执行一种相似类型的重定向。
I/O重定向如何工作?
使用
dup2函数#include<unistd.h> int dup2(int oldfd,int newfd); 返回:若成功则为非负的描述符,若出错则为-1dup2函数拷贝描述符表表项oldfd到描述符表表项newfd,覆盖newfd。
- 如果
newfd已经打开,dup2会在拷贝oldfd之前关闭newfd。(废话,不是肯定打开吗?)
- 如果
![[CSAPP笔记][第十章 系统级I/O]_第9张图片](http://img.e-com-net.com/image/info5/7a846b5bd69e48939e410d717e75a3a1.jpg)
左边和右边的
hoinkies
右hoinkies:>左hoinkies:<
10.8 标准I/O
ANSI C定义了一组高级输入输出函数,称为标准I/O库。
这个
库(libc)提供了- 打开和关闭文件的函数(
fopen和fclose) - 读和写字节(
fread和fwrite) - 读和写字符串的函数(
fgets和fputs) - 以及复杂的格式化
I/O函数 (scanf和printf)
- 打开和关闭文件的函数(
标准
I/O库将一个打开的文件模型化为一个流- 对于程序员来说,一个
流就是一个指向FILE类型的结构的指针。 每个
ANSI C程序开始时都有三个打开的流stdin标准输入stdout标准输出stdout标准错误#include<stdio.h> extern FILE *stdin; extern FILE *stdout; extern FILE *stderr;
- 对于程序员来说,一个
类型为
FILE的流是对文件描述符和流缓冲区的抽象。流缓冲区的目的和RIO读缓冲区的目的一样
- 就是使开销较高的
Unix I/O系统调用的数量尽可能的少。
- 就是使开销较高的
10.9 综合: 我该使用哪些 I/O 函数
![[CSAPP笔记][第十章 系统级I/O]_第10张图片](http://img.e-com-net.com/image/info5/ed29e44e44a94330a9896f2240ff20d6.jpg)
图总结了我们讨论过的各种I/O包。
Unix I/O。RIO I/O标准I/O
磁盘和终端设备之选。- 在
网络输入输出使用,有一些问题。
Unix对网络的抽象是一种叫做套接字的文件类型。
- 和任何
Unix文件一样,套接字也是用文件描述符来引用的,称为套接字描述符。 - 应用进程通过读写
套接字描述符来与运行在其他计算机上的进程通信。
- 和任何
- 大多数C程序员,生涯中只用
标准I/O
标准I/O流 某种意义上而言是全双工的,因为程序能够在同一个流上执行输入输出。
然而,对流的限制和对套接字的限制,有时会互相冲突,而又极少有文档描述这些现象:
(不懂)
- 限制一: 跟在输出函数之后的输入函数。
- 如果中间没有插入对
fflush,fseek,fsetpos或者rewind的调用,一个输入函数不能跟在输出函数之后。
fflush函数清空与流相关的缓冲区。- 后三个函数使用
Unix I/O的lseek函数来重置当前的文件位置。
- 如果中间没有插入对
- 限制二: 跟在输入函数之后的输出函数。
- 如果中间没有插入对
fseek,fsetpos或者rewind的调用,一个输出函数不能跟随在一个输入函数之后,除非该输入函数遇到了一个`EOF。
- 如果中间没有插入对
看不懂,看完之后的再看。
![[CSAPP笔记][第十章 系统级I/O]_第11张图片](http://img.e-com-net.com/image/info5/730b5ac39e284721b73a71d92cc9c782.jpg)
因此,我们建议你在网络套接字不要使用标准I/O来进行输入和输出。而要使用RIO
如果需要格式化的输出
- 使用
sprintf函数在存储器格式化一个字符串。 - 然后用
rio_writen把它发送到套接口。
- 使用
如果需要格式化输入
- 使用
rio_readlinb来读一个完整的文本行 - 然后使用
sscanf从文本行提取不同的字段。
- 使用