机器学习中使用的神经网络第七讲笔记
博客已经迁移至Marcovaldo’s blog (http://marcovaldong.github.io/)
Geoffery Hinton教授的Neuron Networks for Machine Learning的第七讲介绍了循环神经网络(recurrent neural network, RNN)和Long Short Term Memory。
这是Cousera上的课程链接
Modeling sequences: A brief overview
在这一小节,我们将对应用于序列(sequences)的不同类型的模型做一个概括。我们从最简单的模型——ultra aggressive models(该模型尝试根据前一个序列(term or sequence)去预测下一个序列)开始,接着再讨论该模型使用了隐含层的复杂变形,然后再介绍更多有着hidden state和hidden dynamics的模型(这其中包含了linear dynamics systems和hidden Markov models)。这些模型都与RNN有关,因此先介绍,有兴趣了解模型细节的请自行搜索。
当我们用机器学习来构建序列时,我们通常想要将一种序列转换到另一种序列。例如,我们希望能将英语转换成法语,语音识别中我们希望将语音序列转换成词汇序列等。有时,目标序列不是孤立的,我们可以得到一种教学信号来尝试从输入序列中预测下一个序列,因此目标输出序列只是有着进一步形式的输入序列。比起根据一张图像中所有其他像素点去预测一个像素点或者根据一张图像的其他部分来预测一个部分,这种序列的转换看起来更自然。原因是,对于时间序列来讲会有一个很自然的顺序来预测下一步,而对图像处理来讲你不知道接下来的预测是基于什么(不过类似的方法很适用于图像处理)。另外,在进行序列转换时,监督式学习与非监督式学习的区别可能就模糊了(不太明白,但感觉不是很重要)。

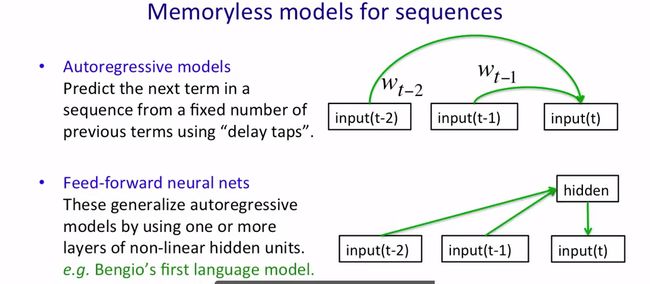
下面介绍序列的无记忆模型(memoryless models for sequences)。自回归模型是一个简单的没有记忆的序列模型,其用some previous terms的加权平均来预测the next term,如下图所示。自回归模型加上隐含单元(hidden units)就构成了更复杂的向前反馈神经网络(feed-forward nerual nets),其结构如下图所示。
下面介绍有记忆的模型,这样的模型有着一些隐含的状态(hidden state),而隐含状态又有着自己的内部动力(internal dynamics)。因此,这些隐含状态根据它们的内部动力演化,产生一些东西。隐含状态能够在很长一段时间内存储信息。如果隐含状态的dynamics有噪声(noisy),由隐含状态产生输出的方式也有噪声,那我们可能永远都不会搞清楚隐含状态是什么样的,我们能做的是推断所有可能的隐含状态向量所在的空间的概率分布(据此你能知道隐含状态向量有可能位于空间中的哪一部分,不太可能位于空间的哪一部分,但不能具体确定其值)。这种对隐含状态的概率分布的推断是非常难的,这里介绍两种比较tractable的隐含状态模型。
首先是线性动态系统(linear dynamical systems),其在工程上应用广泛。模型的hidden state有着线性动力(linear dynamics),如下图中红色箭头所示,而linear dynamics又有着高斯噪声。输入直接影响隐含状态,而隐含状态又决定了输出。这样的系统应用于追踪导弹和行星(观察数据有噪声)。
It turns out that the distribution over the hidden state given the observation so far, that is given the output so far, is also a Gaussian.It’s a full covariance Gaussian, and it’s quite complicated to compute what it is. But it can be computed efficiently. And there’s a technique called Kalman Filtering. This is an efficient recursive way of updating your representation of the hidden state given a new observation. So, to summarize, given observations of the output of the system, we can’t be sure what hidden state it was in, but we can, estimate a Gaussian distribution over the possible hidden states it might have been in. Always assuming, of course, that our model is a correct model of the reality we’re observing.
隐含马尔科夫模型(hidden Markov model)是使用了离散分布的一种隐含状态模型。在该模型中,隐含状态共有N种选择,故有一系列称为状态的东西,而系统总是这些状态中的一个。状态之间的转换是有概率的,这里会有一个转换矩阵控制着状态的转换:在前一个时刻你可能处于state one,转换矩阵告诉你下一个时刻你处于state three的概率。输出模型也是随机的,所以系统所处的状态不能完全决定回产生什么输出,每个状态可以产生的输出会有变化。在某种意义上,正是因为这种概率性(不确定,但有概率可循),状态才被称之为是隐含的。
我们可以得到离散状态的概率分布,由此也就能够预测模型的下一个输出。
It turns out there’s an easy method based on dynamic programming that allows us to take the observations we’ve made and from those compute the probability distribution across the hidden states. Once we have that distribution, there is a nice elegant learning algorithm hidden Markov models, and that’s what made them so appropriate for speech. And in the 1970s, they took over speech recognition.
下图列出了HMM的局限性。
然后下面引出了循环神经网络(recurrent nerual networks)。循环神经网络的强大源于下面两个特点:
- Distributed hidden state that allows them to store a lot of information about the past efficiently.
- Non-linear dynamics that allows them to update their hidden state in complicated ways.
With enough neurons and time, RNNs can compute anything that can be computed by your computer.
下图列出了RNN的一些behavior。

很多东西没听懂,所以还需要搜索别的资料来学习RNN。
Training RNNs with back propagation
这一小节介绍使用back propagation through time algorithm来训练RNNs,该算法很简单,因为RNN在每一个时间步上和一层的向前反馈神经网络(feed forward neural network)是一样的。下图给出了一个简单的循环神经网络和它按时间展开的形式,可以看到按时间展开的网络其实就是一个传统的网络,每一层的参数是相同的。
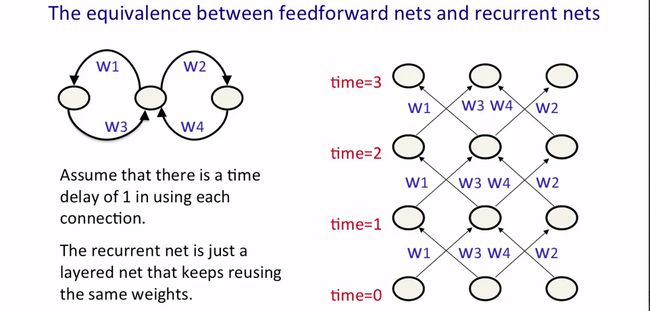
很容易将权值参数间的线性约束结合到back propagation算法中,下图给出了当有 w1=w2 的约束时,算法如何始终满足这一约束的。初始化时,两个权值相等,然后在整个训练过程中要保持两个权值的变化量相等:在每一次更新参数前分别计算梯度,然后用平均值作为更新所用的梯度,这样就保证了模型始终满足约束条件。
下图介绍了backpropagation through time。

我们需要明确所有隐含单元和输出单元的初始状态,可以给这些初始状态一个相同的数值,如0.5。更好地方法是将这些初始状态作为待学习的参数,使用学习权值参数的方法学习它们,下图列出了一个简单的步骤。

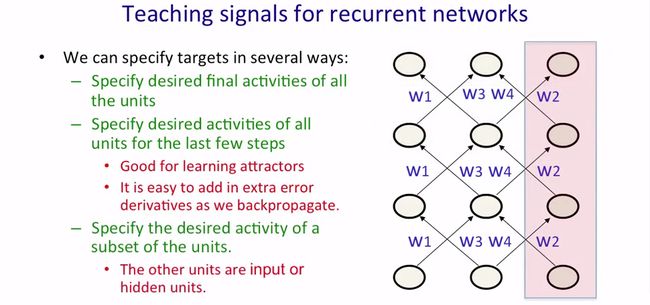
下图给出了specify targets的集中方法。
A toy example of training an RNN
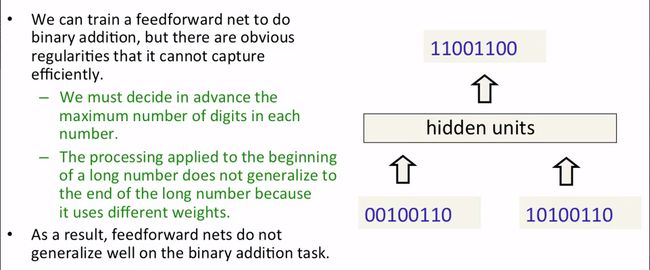
这一小节演示使用RNN来解决二进制数字相加的问题。该问题可以用向前反馈神经网络来解决,但不方便,下图给出理由。
下图给出了RNN的示意图,图中有四个状态,分别表示“无进位打印0”(no carry print 0)、“无进位打印1”(no carry print 1)、“有进位打印0”(carry print 0)和“有进位打印1”(carry print 1),以及状态之间的转换。算法从二进制数字低位开始计算,每次计算时都一个状态,输入是该位上两个二进制数字的值,计算完后得到一个新的状态。例如,计算上图中的两个数字相加,从右边开始,最低位的两个数字0和0相加得到状态“无进位打印0”,最低位计算结果为0;右边第二位数字1和1相加,状态变成了“有进位打印0”,右边第二位计算结果为0;右边第三位数字1和1相加,状态变成了“有进位打印1”,右边第三位计算结果为1;如此进行下去,直至没有输入(即最高位也加完了),就得到了两数相加的结果。(这段文字叙述要结合下面三张图)
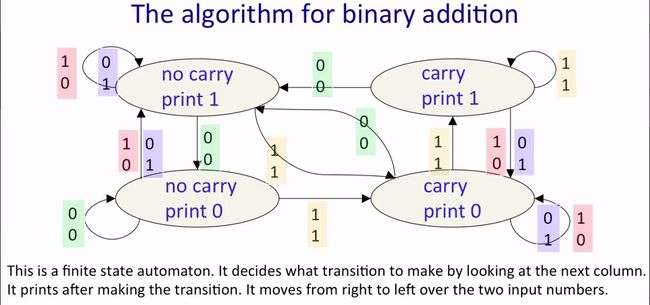
下图总结了RNN要解决这个问题需要学习到什么。

Why it is difficult to train an RNN
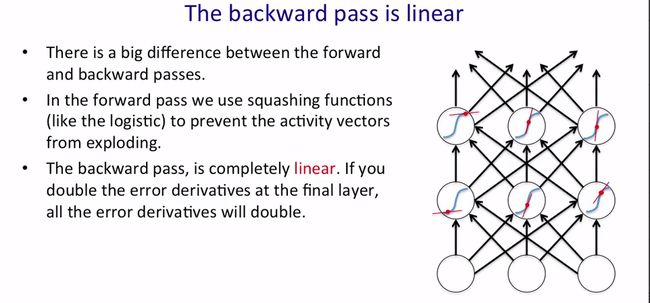
这一小节介绍训练RNN时会遇到的难点。我们先介绍RNN中前向(the forward pass)和反向(the backward pass)之间的重要区别:在前向中,我们使用逻辑函数等挤压函数(squashing function)来避免activity vectors的exploding,如逻辑函数将每一层的输入映射到0~1之间,如下图中绿色曲线所示。而反向则完全是线性的。当你做反向传播时如果最后一层的error derivatives加倍,你会发现所有的error derivatives都会加倍。不太明白下面这段什么意思,所以直接贴上了原文。
So, if you look at the red dots that I put on the blue curves, we’ll suppose those are the activity levels of the neurons on the forward pass. And so, when you back propagate, you’re using the gradients of the blue curves at those red dots. So the red lines are meant to throw the tangents to the blue curves at the red dots. And, once you finish the forward pass, the slope of that tangent is fixed. You now back propagate and the back propagation is like going forwards though a linear system in which the slope of the non-linearity has been fixed. Of course, each time you back propagate, the slopes will be different because they were determined by the forward pass. But during the back propagation, it’s a linear system and so it suffers from a problem of linear systems, which is when you iterate, they tend to either explode or die.
所以就有了梯度爆炸和梯度消失的问题:
- What happens to the magnitude of the gradients as we backpropagate through many layers? If the weights are small, the gradients shrink exponentially. If the weights are big, the gradients grow exponentially.
- Typical feed-forward neural nets can cope with these exponential effects because they only have a few hidden layers.
- In an RNN trained on long sequences (e.g. 100 time steps) the gradients can easily explode or vanish.
- Even with goog initial weights, its very hard to detect that the current target output depends on an input from many time-steps ago.
So RNNs have difficulty dealing with long-range dependencies.
下图列举了一个梯度消失和梯度爆炸的例子。
下图列出了四种学习RNN的有效方法,下一小节我们会介绍Last Short Term Memory。

Long-term Short-term-memory
这一小节介绍用来训练RNN的Long term short term memory。考虑将神经网络的动态状态作为一个短期存储器,通过添加一个特殊的模块以在需要的时候将信息存入或释放,从而达到长时间保存信息的目的。(You can consider the dynamic state of a neural network to be a short term memory. And the idea is, you want to make that short term memory last for a long time. This is done by creating special modules that are designed to allow information to be gated in, and then information to be gated out when needed.)在中间时刻,特殊模块的门是关闭的,从而保证其中的信息不受干扰。
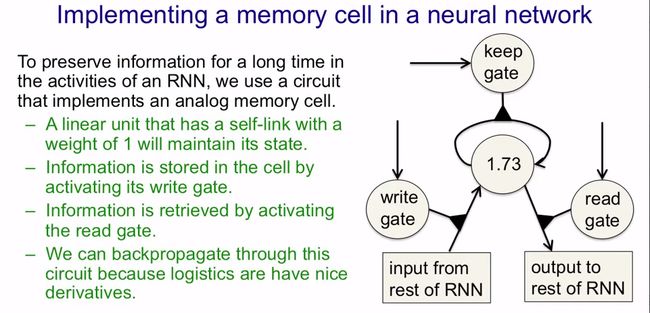
LSTM在手写识别上有着很好的性能,应用了LSTM的RNN可以在数百个时间步内保存信息。LSTM通过使用互相控制的逻辑单元或线性单元设计了一个存储单元(memory cell),当“write”门打开的时候信息就可以进入,只要“keep”门开着信息就会一直保存在存储单元中,当“read”门打开的时候信息就可以被读取出来了。存储单元存储了一个模拟值,所以我们可以将其看作是一个线性神经元,该神经元在每一个时刻将其上的模拟值乘上一个权值(就是1)后再传递给它本身,从而实现了信息的存储。而1这个权值是由keep gate决定的,而这个logistic keep gate又由系统的其他部分决定:当keep gate被置为1后,信息就被保存在了这个神经元中;当系统想要删除这个信息时,只需将keep gate的值置为0,然后信息就没了。为了在存储单元实现信息的写入和读出,这里还设计了write gate和read gate,具体如下图所示。
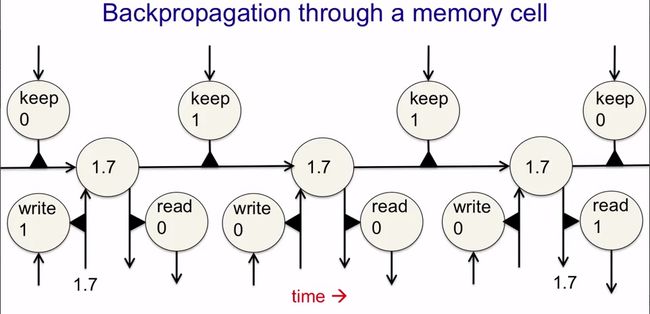
下面给出了一个具体的例子,如何存入、保持、取出信息,如下图所示。这里提到了backpropagation,但没听明白。
下图介绍了使用了LSTM的RNN在连笔手写识别上的一个应用。

下面是Alex Graves对使用RNN来实现在线手写识别的一个证明。视频的最后是一小段在线手写识别的演示,这里只截了最后的画面,详情请自行搜索。这里给出本讲视频的链接