【论文笔记】Recursive Recurrent Nets with Attention Modeling for OCR in the Wild
写在前面:
我看的paper大多为Computer Vision、Deep Learning相关的paper,现在基本也处于入门阶段,一些理解可能不太正确。说到底,小女子才疏学浅,如果有错误及理解不透彻的地方,欢迎各位大神批评指正!
E-mail:[email protected]。
《Recursive Recurrent Nets with Attention Modeling for OCR in the Wild》已经被CVPR 2016(CV领域三大顶会之一)正式接收了,主要是介绍了在lexicon-free的情况下,使用带Attention Model的recurcive RNN识别自然场景中的文本,也就是用RNN来做OCR(Optical Character Recognition)的工作。我觉得这篇paper有个写得特别好的地方,就在在Section 2介绍方法时,同时将自己的方法与related work进行了实时对比,使得差异更加可见,优势更加凸显,值得借鉴。
此文中的模型是基于参考文献【17】《Deep structured output learning for unconstrained text recognition》所提出的模型的的,这篇paper是用CNN+CRF结合的模型,对字符进行识别后,进行N元文法分析,详见我的论文笔记:【论文笔记】Deep Structured Output Learning for Unconstrained Text Recognition 。
《Recursive Recurrent Nets with Attention Modeling for OCR in the Wild》
论文框架:
Abstract
1.Introduction
2.Methodology
2.1 Character sequence model review
2.2 Recursive CNNs for image featureextraction
2.2.1 Recursive convolutional layer
2.2.2 Untying in recursive convolutional layers
2.3 RNNs for character level languagemodeling
2.4 Attention modeling
3.Experiments
3.1 Datasets
3.2 Implementation details
3.3 Ablation study
3.3.1 Recursive and recurrentconvolutional layers
3.3.2 Character-level languagemodeling
3.3.3 Constrained and unconstrainedtext recognition
4.Conclusion and future directions
1、文章概述
本章提出了一个带有attention modeling的recurcive RNN(recursive recurrent neural networks with attention modeling,![]() )模型,直接用图片进行词汇字符串(word string)学习,实现了对无约束(unconstrained,即lexicon-free,未知word长度)自然场景文本进行识别。主要贡献有:
)模型,直接用图片进行词汇字符串(word string)学习,实现了对无约束(unconstrained,即lexicon-free,未知word长度)自然场景文本进行识别。主要贡献有:
(1)recursive CNNs:相同的参数容量下能够更加有效地提取图片特征;
(2)隐式学习的字符级语言模型:嵌入了RNN(recurrent neural network),避免进行N元文法分析(Ps:个人理解就是用一个RNN代替了【17】中N元文法分析的功能);
(3)使用了soft-attention机制:使模型能够有选择地利用图片特征, 并且可以使用标准的反向传播来进行端到端训练。
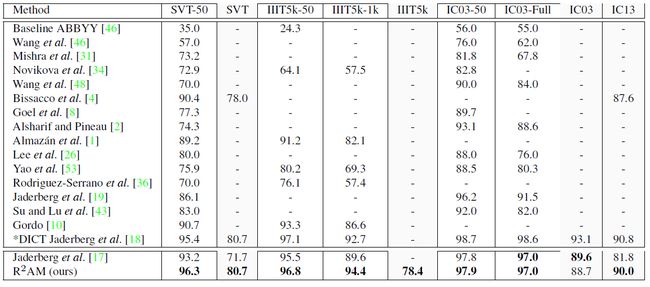
本文在Street View Text, IIIT5K, ICDR以及Synth90k这几个数据集上进行了实验,详细分析了所提出模型组件的性能,实验得出文中提出的网络结构获得了最优的结果,超出了之前unconstrained文本识别的最佳结果,例如:在Street View Text上提高了9%,在ICDAR 2013上提高了8.2%。
2.方法
在这篇论文中,我们关注于场景文本的识别工作,预测一张单个词汇的裁剪图片中的所有字符。也就是说这篇论文的输入为裁剪的词汇区域。这一章介绍相关文献以及所提出的R2AM网络结构。图1展示了我们的整体系统结构。
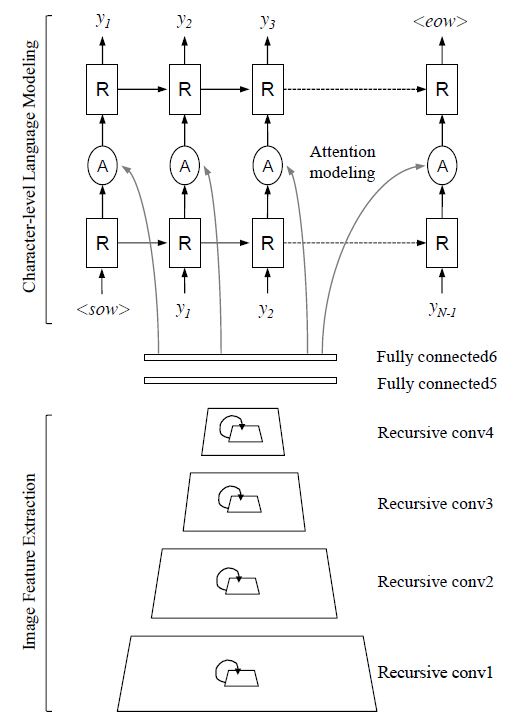
图 1.带有attention modeling的RNN(![]() )
)
(1)字符序列模型
许多文本方法在系统流程的第一步总是获得一个词汇的每一个字符,然后使用统计语言模型或者视觉结构预测来修正错误分类的字符,如【46,48,32,4,39,26,53】。然而,由于每个字符与这个词汇中的其他字符在位置上密切相连,使得这里存在一个很大的挑战,因此,经典的字符识别组件需要处理大量的类间(inter-class)和类中(intra-class)混淆,这一点在【32】中的图3给出了很多的解释。尽管复杂的语言识别系统结合了高级别的基于CRFs或Markov模型的语言先验,但是这个系统的性能还是由系统处理流程的第一步——字符识别组件来主导。
Goodfellow等人【9】第一次使用带有位置灵敏字符分类器的CNN对街道编号进行分类。最近,Jaderberg等人【18,17】提出了一种字符序列模型,直接使用深度CNN来对一个词汇中每一个位置的字符进行编码,然后预测一个图像区域的字符序列。这个方法对场景字符中不能由基于滑窗的字符识别方法很好衡量的自然间距和重叠模式直接建模,很大程度上克服了前面提到的问题,详见【17】。在这篇论文中我们称这个基本方法为Base CNN(并且在图3中标记为Base CNN)。此文中所提出的系统建立在Base CNN模型之上。
(2)用于图像特征提取的recursive CNN
a.recursive convolutional layer
前面提到的字符线性模型巨大成功的一个关键是在字符预测时通过在整个输入图像中应用多层卷积层来捕捉上下文依赖。
要改进上述Base CNN,使之具有平均变化更大的上下文依赖来进行字符预测,一种可行的方式是考虑每层卷积使用更大的卷积核,或者更深的网络,来增加相应接受域的大小。然而,这种方法需要更多的参数,增加了模型的复杂度,由此会导致潜在的训练和迭代的问题。
另一个在控制模型容量的同时扩大更长数据依赖的方法是使Base CNN 网络递归(recursive)或者循环(recurrent),如【35,7,29】中所介绍的那样。通过使用递归或者循环的卷积层,网络结构可以具有任意深度,并且通过在每一层多次重用相同的卷积权值矩阵,并不会很大程度上增加参数的总数。
本文中的方法使用了recursive CNN:在时间t时,recursive卷积层输入图像/特征的关系为:
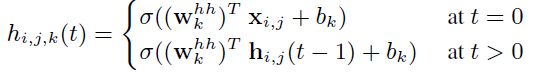 式(1)
式(1)
其中![]() 表示向量化前馈,
表示向量化前馈,![]() 表示feature map上以为中心的输入patchaes。为输出channel的向量化前馈权值。
表示feature map上以为中心的输入patchaes。为输出channel的向量化前馈权值。![]() 为输出channel的偏差。
为输出channel的偏差。![]() 为确定的非线性转换函数。
为确定的非线性转换函数。
recursive CNNs在相同参数容量的情况下增加了传统CNNs的深度,同时也比CNNs产生更加紧凑的特征响应。recursive相互作用也可以视为feature map中的一种“横向连接性”,使得给定层的表示更好捕捉到高层依赖。
b. Untying in recursive convolutional layer
式(1)约束所有的权值共享相同的内部值——他们“捆绑(tied)”一起。这种捆绑的一种结果就是所有层的channels数目将使一样的,因为共享权值总是将输入feature maps映射到相同维数(宽*高*channels的数目)的输出feature map。
本文提出一种recursive卷积层的“非捆绑(untied)”变体,区别在于层间(inter-layer)前馈权值![]() ,后面的层内(intra-layer)recursive权值
,后面的层内(intra-layer)recursive权值![]() 。这种方法允许在不同层具有不同数目的channel,并且时recursive权值可以更加自由特化。
。这种方法允许在不同层具有不同数目的channel,并且时recursive权值可以更加自由特化。
通过在时间t=0的时候untying前馈权值,式(1)变为:
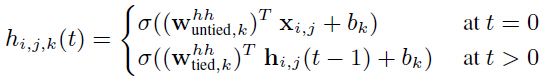 式(2)
式(2)
通过这种方法,任意recursive卷积层的channels数目可以由untied权值![]() 来进行调整,控制整体的计算代价。可以使用相容的逻辑来untierecurrent卷积层,如图2所示。
来进行调整,控制整体的计算代价。可以使用相容的逻辑来untierecurrent卷积层,如图2所示。
图2.untied recursive卷积层和untied recurrent卷积层。在![]() 时untie第一个前馈权值,并且在时保持前馈权值不变(文中用了rest这个词)。蓝色框中的层具有tied(shared)权值。
时untie第一个前馈权值,并且在时保持前馈权值不变(文中用了rest这个词)。蓝色框中的层具有tied(shared)权值。
图1中的pipeline选择了recursive Base CNN作为整个架构的底层部分(后面对多种可能都进行了实验,最终发现recursive的版本性能最好,固择之)。
(3) 用于字符级语言建模的RNN
文中使用RNNs(recurrent neural networks)来对文本字符级统计进行建模。RNN及其变体LSTM(Long Short-Term Memory)在处理序列数据的时候非常有效。识别图片中的字符可以将其视为解决sequential dynamics和学习从像素强度到自然字符级向量映射的问题。这个模型获取单张图片,并且生成一个字符序列,每个字符为K个编码字符中的一个。
![]() 式(3)
式(3)
其中K为可能的字符的个数(即样本集中出现的字符的种类),N为word的长度。
这里使用RNN通过在图像特征![]() 上每个时间步产生一个单词来产生一个word串,先前的隐层状态和输入
上每个时间步产生一个单词来产生一个word串,先前的隐层状态和输入![]() 使用下面的递归公式:
使用下面的递归公式:
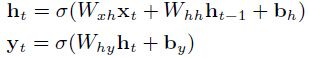 式(4)
式(4)
其中![]() 为元素级非线性转换函数,
为元素级非线性转换函数,![]() 为带有M个单元的隐层状态,输入
为带有M个单元的隐层状态,输入![]() 可以为图片特征
可以为图片特征![]() 或者前面产生的字符
或者前面产生的字符![]() ,取决了所使用的RNN的结构。编码图像特征
,取决了所使用的RNN的结构。编码图像特征![]() 从CNN模型最后的一层全连接层提取得到。这个CNN模型可以为普通CNN、递归CNN或者循环CNN(文中作者使用了多种CNN模型,并在后面对CNN模型进行了比较)。
从CNN模型最后的一层全连接层提取得到。这个CNN模型可以为普通CNN、递归CNN或者循环CNN(文中作者使用了多种CNN模型,并在后面对CNN模型进行了比较)。
将一个图像特征![]() 传输到一个RNN有许多中方式,RNN本身也可以有许多种不同的结构。图3展示了base CNN与5种RNN变体相结合的结构:
传输到一个RNN有许多中方式,RNN本身也可以有许多种不同的结构。图3展示了base CNN与5种RNN变体相结合的结构:
Base CNN:基线字符序列CNN,使用多种损失函数进行训练,每个损失函数针对于字符的位置(如2.2所述)。
Base CNN + RNN 1c:一个单层RNN。提取到的图像特征![]() 仅仅在第一次的时候送入到RNN中。RNN在t-1时间的预测字符
仅仅在第一次的时候送入到RNN中。RNN在t-1时间的预测字符![]() 在时间t的时候送入到RNN,知道获得word最后一个标签。这个变体作为一个很好的完整性检查,并且帮助验证给定一个最初的CNN表达时, RNN进行字符级语言建模的能力。
在时间t的时候送入到RNN,知道获得word最后一个标签。这个变体作为一个很好的完整性检查,并且帮助验证给定一个最初的CNN表达时, RNN进行字符级语言建模的能力。
Base CNN + RNN 1u:一个非因式分解的单层RNN,图像特征![]() 输入到每个时间步。因此,字符预测始终以图像特征和前面的隐层状态为条件。
输入到每个时间步。因此,字符预测始终以图像特征和前面的隐层状态为条件。
Base CNN + RNN 2u:一个非因式分解的双层RNN,使用了两个RNN进行堆叠。这个模型在每个时间步上具有更深的结构。这个结构在每个时间步上都可以获得字符特征。
Base CNN + RNN 2f:一个因式分解的 双层RNN,使用了两个RNN进行堆叠。这个变体只有第二层RNN才能获得图像特征。通过这种方法,使第一层RNN专注于字符级语言建模,使第二层RNN专注于语言统计与图像特征的结合。
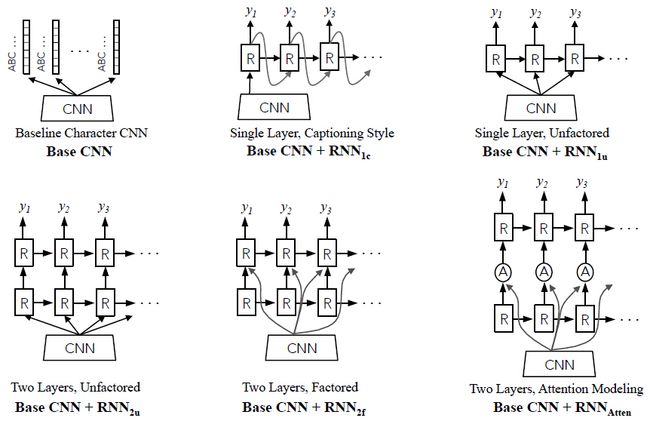
图3.五种时间上递归的结构变体。探索图像说明风格RNN、RNN深度的影响、因式分解形式的影响,及attention modeling的影响。
(4) Attention modeling
Attention-based机制使得模型专注于输入特征的最重要的分割,并且可能添加一个可解释性(interpretability)的级别。一般有两类attention-based图像理解:hard-attention和soft-attention。Hard-attention模型学习选择一序列离散的glimpse location,但是很难训练,因为损失梯度(loss gradients)很难处理。本文使用的是一个soft-attention模型,可以使用标准的反向传播来进行训练。
图3中的Base CNN+RNN atten:在每一步t的输出中,attention函数以图像特征![]() 以及第一层RNN的输出为条件计算一个能量向量(energy vector):
以及第一层RNN的输出为条件计算一个能量向量(energy vector):
![]() 式(5)
式(5)
其中![]() 和
和![]() 可以是多层感知机(multilayer perceptrons)或者一个简单的权值举矩阵,简单地将
可以是多层感知机(multilayer perceptrons)或者一个简单的权值举矩阵,简单地将![]() 和映射到相同空间。然后语境向量(context vector)
和映射到相同空间。然后语境向量(context vector)![]() 基于时间t的能量系数
基于时间t的能量系数![]() ,计算作为加权图像特征:
,计算作为加权图像特征:
式(6)
其中![]() 为Hadamard卷积。这个机制产生一组正权重
为Hadamard卷积。这个机制产生一组正权重![]() ,可以理解为给定一个融合图像特征
,可以理解为给定一个融合图像特征![]() 的位置d 的相对重要性。然后计算的语境向量
的位置d 的相对重要性。然后计算的语境向量![]() 被送入到第二层RNN来进行最终的输出预测。
被送入到第二层RNN来进行最终的输出预测。
3.实验及结果
(1)数据集
ICDAR 2003、ICDAR 2013、Street View Text、IIIT5k、Synth90k。
(使用Synth90k进行训练,通过验证集来选择参数。)
(2) 实现细节
Base CNN模型的网络结构如表A1所示。它有8个卷积层,每一层的channel分别为64、64、128、128、256、256、512、512,并且每一个卷积层使用3*3的spatial extent。卷积步长为1,使用了0填充及ReLU激活函数。在第二层、第四层和第六层卷积层的后面跟有2*2大小的polling层。两个全连接层有4096个units。输入图片归一化为32*100的灰度图。
下面详细介绍表A1中提出的untied recursive CNN网络结构。 注意,偶数层卷积层使用它们自己的共享权值矩阵,输入和输出具有相同的位数,所以在recursive(recurrent和recursive,还是用原词比较直观)卷积层多次将feature map映射到统一空间,与Base CNN模型具有相同的参数容量。
表A1.左边:Base CNN网络架构。右边:条形图展示了在Synth90k数据集上,不同深度的网络所对应的性能。文章在实验中逐渐增加【17】中baseline CHAR model 的深度,从5层卷积层到8层卷积层。但是,使用提出的untied recursive CNNs可以获得同样的性能。注意,recursive CNNs与Base CNN具有相同的参数,但是可以获得更高的准确率
对于字符级语言建模,文中使用了带有1024个隐层单元的RNN,使用了双正切激活函数。pipeline如图1所示。
使用backpropagation through time(BPTT)算法来对模型进行训练,SGD为256 batch size,dropout rate=0.5。初始learning rate=0.002,以5倍的速度降低,因为在两次epoch中验证错误停止降低。所有的变体使用相同的机制,总共有30次epoch(由验证集定义)。梯度剪裁(gradient clipping)的量级为10,发现它带有适当的权重衰减(weight decay),并不会有额外的性能提升。所有的权重从高斯分布中取样,标准偏差为0.01。这个系统在开元深度学习框架Caffe中实现。在一个NVIDIA Titan X GPU上,整个系统框架对每张图片的识别时间为2.2ms(在自然场景文本识别中少有提时间的paper,特别是那些加上定位的paper,基本不提时间)。
(3) 实验结果
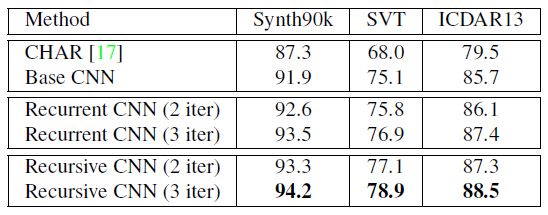
a. recursive卷积层 vs. recurrent 卷积层
下表展示了在unconstrained文本识别上,recurrent CNNs与Base CNN模型性能的对比。结果显示“迭代”对于recursive和recurrent CNNs来说同样重要,recursive CNNs在三个数据集上表现都更为突出。由此选择recursive CNNs作为最终的系统架构。
b. 字符级语言建模
下表展示了图3中每种架构变体对UN从strainted文本识别的结果。结果显示带有attention建模的RNN获得了最佳结果。
、
c. Constrained与unconstrained文本识别
下表对比了文中的方法和【17】中的方法在unconstrained文本识别中的性能。
尽管文中的方法是针对于unconstrained 文本识别的,作者还是将其结果与constrained文本识别结果进行了对比。下表展示了准确率的对比。