Hadoop-2.7.1集群环境搭建
由于日志数据量越来越大,数据处理的逻辑越来越复杂,同时还涉及到大量日志需要批处理,当前的flume-kafka-storm-hbase-web这一套流程已经不能满足当前的需求了,所以只能另寻出路,于是想到了Hadoop这个东西。之前的storm是一个基于流式处理的实时分析系统,相比Hadoop的离线批处理各有千秋,两者相比,我有看到一个比较形象的比喻:Hadoop就像是纯净水,一桶一桶地搬,而Storm是用水管,预先接好,打开水龙头,水就源源不断的出来了。
同样,Hadoop的批处理也是相当的强大,高性能、高稳定、高吞吐量、分布式、批处理这些特点都是我们所需要的。于是,在目前的形势下,在之前的实时处理的基础上,我们想再加一个离线的日志批处理,于是用到了Hadoop。首先,我们得搭建好Hadoop集群,由于我也是第一次搭建Hadoop集群,其中遇到了许多的问题,可以说是一把辛酸泪,后面终于把集群搭建起来了,可算不负众望。
下面记录Hadoop的搭建过程:
1、首先到官网上下载一个Hadoop的压缩安装包,我安装用的版本是hadoop-2.7.1.tar.gz,由于我安装的是最新的版本,和Hadoop之前的版本有很大的差异,所以网上很多的教程都不适用,这也是导致在安装过程中遇到问题所在,下载地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
2、下载完成后(这个压缩包比较大,有201M,下载比较慢,耐心等待吧),放到Linux某个目录下,这里我用的系统是:CentOS release 6.5 (Final),我放的目录是:/usr/local/jiang/hadoop-2.7.1.tar.gz,然后执行:tar zxvf hadoop-2.7.1.tar.gz解压(这些操作都是要在集群中的主机上进行,也就是hadoop的master上面)
3、配置host文件
进入/etc/hosts,配置主机名和ip的映射, 这里是集群的每个机子都需要配置,这里我的logsrv02是主机(master),其余两台是从机(slave)
[root@logsrv03 /]# vi /etc/hosts 172.17.6.142 logsrv02 172.17.6.149 logsrv04 172.17.6.148 logsrv034、jdk的安装(这里我的机子上面已经有了,所以就不需要再安装了)
我使用的jdk是jdk1.7.0_71,没有的需要安装,将jdk下载下来,解压到某个目录下,然后到/etc/profile中配置环境变量,在执行java -version验证是否安装成功。
5、配置SSH免密码登陆
这里所说的免密码登录是相对于主机master来说的,master和slave之间需要通信,配置好后,master和slave进行ssh登陆的时候不需要输入密码。
如果系统中没有ssh的需要安装,然后执行:
[root@logsrv03 ~]# ssh-keygen -t rsa会在根目录下生成私钥id_rsa和公钥id_rsa.pub
[root@logsrv03 /]# cd ~ [root@logsrv03 ~]# cd .ssh [root@logsrv03 .ssh]# ll 总用量 20 -rw------- 1 root root 1185 11月 10 14:41 authorized_keys -rw------- 1 root root 1675 11月 2 15:57 id_rsa -rw-r--r-- 1 root root 395 11月 2 15:57 id_rsa.pub
然后将这里的公钥分别拷贝到其余slave中的.ssh文件中,然后要把公钥(id_dsa.pub)追加到授权的key中去:
cat id_rsa.pub >> authorized_keys
然后修改权限(每台机子都需要修改),这点我也没太弄明白,具体可以参考: http://blog.csdn.net/leexide/article/details/17252369
[root@logsrv04 .ssh]# chmod 600 authorized_keys [root@logsrv04 .ssh]# chmod 700 -R .ssh
将生成的公钥复制到从机上的.ssh目录下:
[root@logsrv03 .ssh]# scp -r id_rsa.pub root@logsrv02:~/.ssh/ [root@logsrv03 .ssh]# scp -r id_rsa.pub root@logsrv04:~/.ssh/
然后所有机子都需要重启ssh服务
[root@logsrv03 .ssh]# service sshd restart [root@logsrv02 .ssh]# service sshd restart [root@logsrv04 .ssh]# service sshd restart然后验证免密码登陆是否成功,这里在主机master这里验证:
[root@logsrv03 .ssh]# ssh logsrv02 [root@logsrv03 .ssh]# ssh logsrv04
如果在登陆slave不需要输入密码,则免密码登陆设置成功。
6、开始安装Hadoop,配置hadoop环境变量/etc/profile(所有机子都需要配置)
export HADOOP_HOME=/usr/local/jiang/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin7、修改配置文件:
[root@logsrv03 /]# cd usr/local/jiang/hadoop-2.7.1 [root@logsrv03 hadoop-2.7.1]# cd etc/hadoop/ [root@logsrv03 hadoop]# vi hadoop-env.sh export JAVA_HOME=/usr/local/jdk1.7.0_71(2)、修改 hadoop-2.7.1/etc/hadoop/slaves
[root@logsrv03 hadoop]# vi slaves logsrv02 logsrv04(3)、修改 hadoop-2.7.1/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://logsrv03:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
</property>
<property>
<name>fs.hdfs.impl</name>
<value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
<description>The FileSystem for hdfs: uris.</description>
</property>
<property>
<name>fs.file.impl</name>
<value>org.apache.hadoop.fs.LocalFileSystem</value>
<description>The FileSystem for hdfs: uris.</description>
</property>
</configuration>(4)、修改
hadoop-2.7.1/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>(5)、修改
hadoop-2.7.1/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>logsrv03:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>logsrv03:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>logsrv03:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>logsrv03:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>logsrv03:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>(6)、修改
hadoop-2.7.1/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>logsrv03:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>logsrv03:19888</value>
</property>
</configuration>8、这些配置文件配置完毕后,然后将整个hadoop-2.7.1文件复制到各个从机的目录下,这里目录最好与主机一致
[root@logsrv03 hadoop-2.7.1]# scp -r hadoop-2.7.1 root@logsrv02:/usr/local/jiang/ [root@logsrv03 hadoop-2.7.1]# scp -r hadoop-2.7.1 root@logsrv04:/usr/local/jiang/
9、到这里全部配置完毕,然后开始启动hadoop,首先格式化hdfs
[root@logsrv03 hadoop-2.7.1]# bin/hdfs namenode -format
10、然后启动hdfs
[root@logsrv03 hadoop-2.7.1]# sbin/start-dfs.sh
[root@logsrv03 hadoop-2.7.1]# jps 29637 NameNode 29834 SecondaryNameNode
从机logsrv02、logsrv04:
[root@logsrv04 hadoop-2.7.1]# jps 20360 DataNode
[root@logsrv02 hadoop-2.7.1]# jps 10774 DataNode
11、启动yarn
[root@logsrv03 hadoop-2.7.1]# sbin/start-yarn.sh
到这里,启动的进程:
[root@logsrv03 hadoop-2.7.1]# jps 29637 NameNode 29834 SecondaryNameNode 30013 ResourceManager
从机logsrv02、logsrv04:
[root@logsrv02 hadoop-2.7.1]# jps 10774 DataNode 10880 NodeManager
[root@logsrv04 hadoop-2.7.1]# jps 20360 DataNode 20483 NodeManager
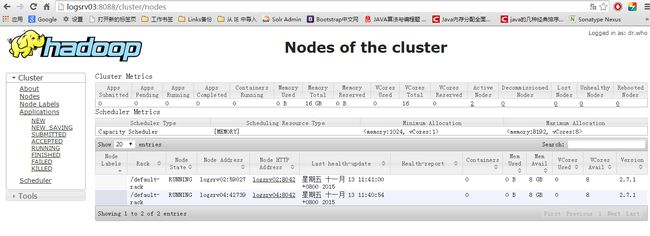
到这里,恭喜整个集群配置完成,可以通过:http://logsrv03:8088/cluster查看hadoop集群图:
查看HDFS: