Spark 定制版:006~Spark Streaming源码解读之Job动态生成和深度思考
本讲内容:
a. Spark Streaming Job生成深度思考
b. Spark Streaming Job生成源码解析
注:本讲内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
上节回顾
上节课,主要是从Spark Streaming+Spark SQL来实现分类最热门商品的在线动态计算的事例代码开始,并通过Spark源代码给大家贯通Spark Streaming流计算框架的运行。
并绘制了Spark Streaming应用运行流程的关键类:
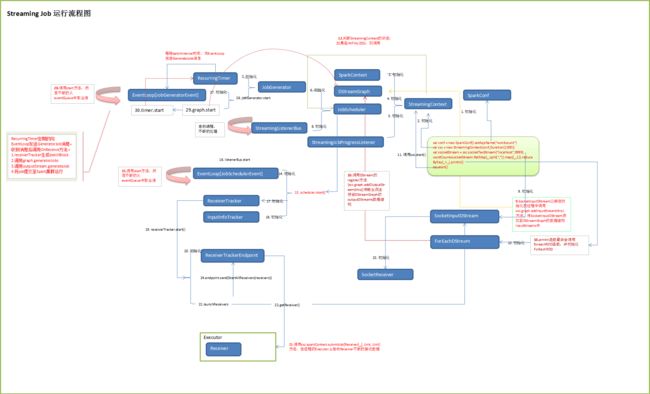
根据上面的运行类图,逐步解密了Spark Streaming流计算框架,了解了Job整个运行的关键类,及其对类中方法的解读。
开讲
数据处理的方式:大致可以分为以下三种:
a. 批处理(基本上是处理静态数据,一次读入大量的数据进行处理并生成输出结果)
b. 微批处理(结合了批处理和连续流操作符,将输入分成多个微批次进行处理;可以这么理解,微批处理是一个“收集后再处理”的计算模型;可以认为接近实时流处理)
c. 连续流模型(连续流操作符则在数据到达时进行处理,没有任何数据收集或处理延迟;此乃真正的实时流处理)
换句话说:微批处理,当时间间隔足够短的时候就形成了流式处理,进而认为到达了实时处理(Spark 2.0 中Spark Streaming 有了重大的改进,可以期待一个Spark实时连续流处理时代的到来!)。
首先,我们来看一下Job动态生成图:
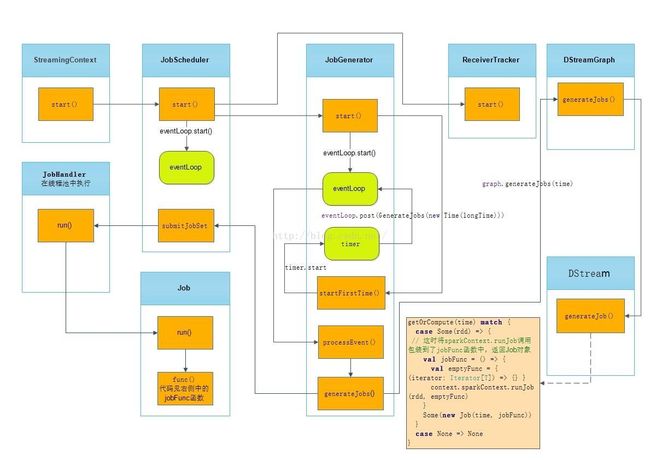
本讲,我们以上图中的JobGenerator类为重心,开始为大家左右延伸,解密Job之动态生成。
JobGenerator这个类生成的Jobs来自DStreams,并驱动检查点获得且是清洗掉上一个timer中DStream的数据之后的元数据。
其构造函数中需要传入JobScheduler对象,而JobScheduler类是Spark Streaming Job生成和提交Job到集群的核心。
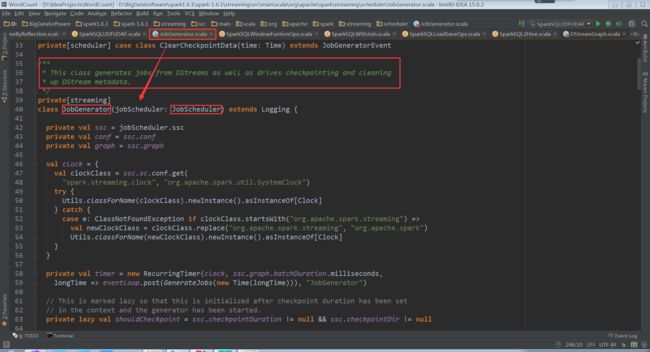
我们可以看到生成Jobs的是JobGenerator的Start()方法。该方法中有个eventLoop,是具体操作事务循环,来不断获事务进程。
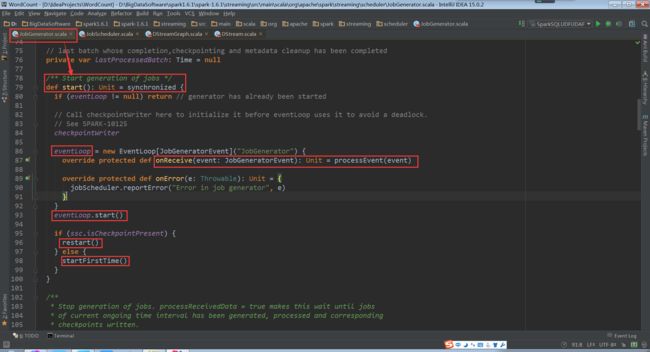
processEvent根据time,来执行相应的操作:generateJobs(time),回到generateJobs(time: Time);
根据time产生Jobs
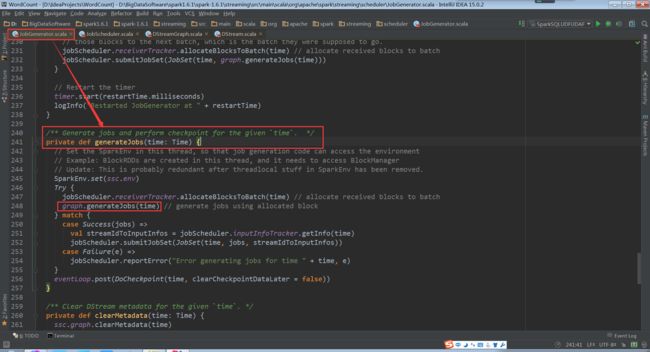
graph.generateJobs(time)进入到generateJobs(time: Time): Seq[Job]
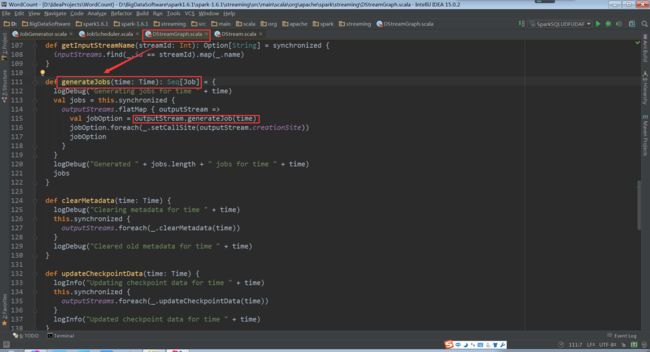
outputStream.generateJob(time)进入到generateJob(time: Time): Option[Job]
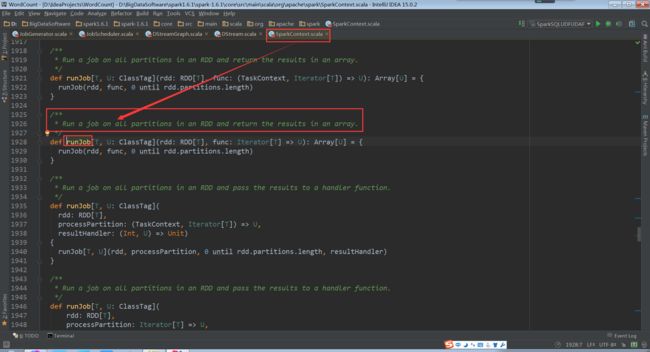
调用context.sparkContext.runJob(rdd, emptyFunc),进入到runJob,计算同一个RDD中的所有数据块,并将结果存放在一个数组里。
至此,我们从新回过头来,看看JobGenerator中的generateJobs(time: Time),里面有个jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))方法
进入到jobScheduler.submitJobSet中,最终交给了new JobHandler(job))
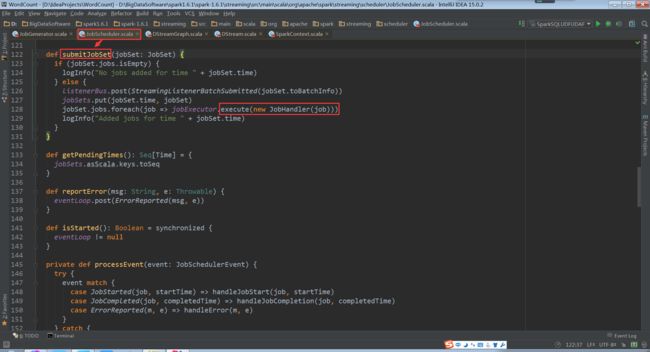
进入到JobHandler中。我们发现继承了Runnable接口。启动了run方法,循环执行各种业务逻辑任务。
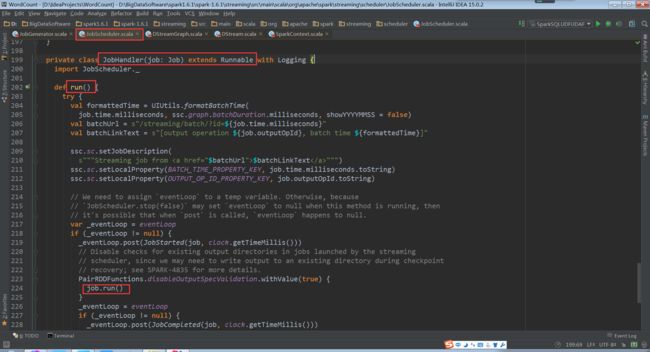
进入上图中的job.run(),执行很多个任务
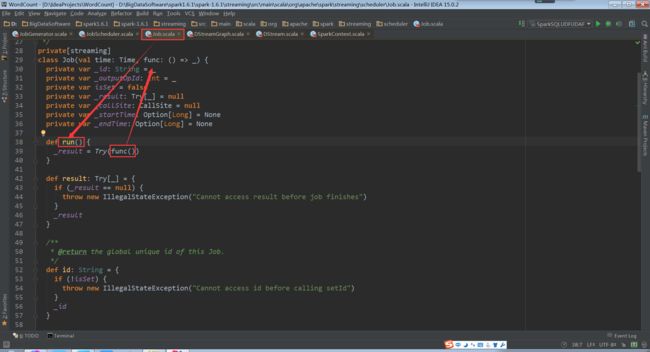
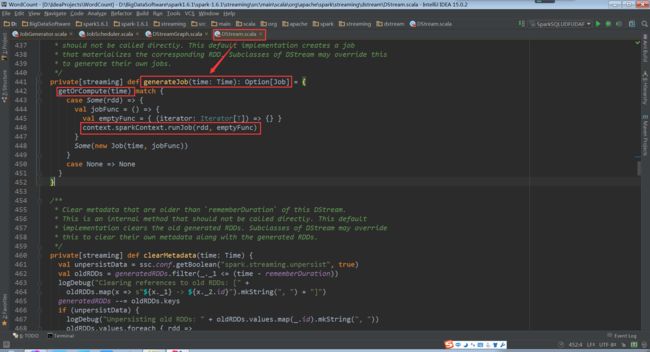
由上图中的func(),再次回到DStream中的 generateJob(time: Time): Option[Job]
至此,我们回到JobScheduler类,start()方法中一个receiverTracker.start()方法
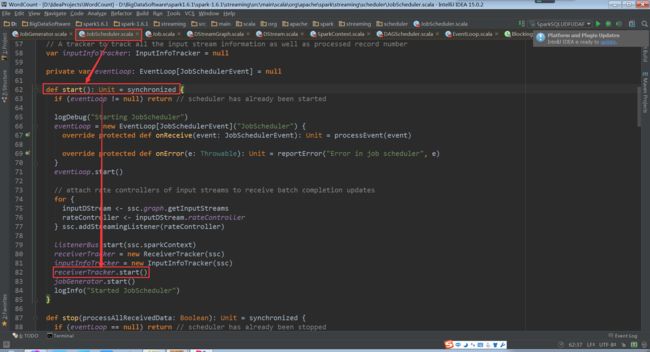
进入到receiverTracker.start()方法中
进入到ReceiverTrackerEndpoint
思考一个问题:DStreamGraph逻辑级别翻译成物理级别的RDD Graph,最后一个操作是RDD的action操作,是否会立即触发Job?
a. action触发作业,这个时候作为Runnable接口封装,他会定义一个方法,这个方法里面是基于DStream的依赖关系生成的RDD。翻译的时候 是将DStream的依赖关系翻译成RDD的依赖关系,由于DStream的依赖关系最后一个是action级别的,翻译成RDD的时候,RDD的最后一 个操作也应该是action级别的,如果翻译的时候直接执行的话,就直接生成了Job,就没有所谓的队列,所以会将翻译的事件放到一个函数中或者一个方法fun() 中,因此,如果这个函数没有指定的action触发作业是执行不了的。
b. Spark Streaming根据时间不断的去管理我们的生成的作业,所以这个时候我们每个作业又有action级别的操作,这个action操作是对 DStream进行逻辑级别的操作,他生成每个Job放到队列的时候,他一定会被翻译为RDD的操作,那基于RDD操作的最后一个一定是action级别 的,如果翻译的话直接就是触发action的话整个Spark Streaming的Job就不受管理了。因此我们既要保证他的翻译,又要保证对他的管理,把DStream之间的依赖关系转变为RDD之间的依赖关系, 最后一个DStream使得action的操作,翻译成一个RDD之间的action操作,整个翻译后的内容他是一块内容,他这一块内容是放在一个函数体 中的,这个函数体,他会函数的定义,这个函数由于他只是定义还没有执行,所以他里面的RDD的action不会执行,不会触发Job,当我们的 JobScheduler要调度Job的时候,转过来在线程池中拿出一条线程执行刚才的封装的方法。
我们再次聚焦Spark 作业动态生成三大核心
a. JobGenerator: 负责Job生成
b. JobSheduler:负责Job调度
c. ReceiverTracker:获取元数据
备注:
1、DT大数据梦工厂微信公众号DT_Spark
2、Spark大神级专家:王家林
3、新浪微博: http://www.weibo.com/ilovepains