贪心算法之赫夫曼编码
- 贪心算法之赫夫曼编码
- 编码基本介绍
- 等长编码
- 变长编码
- 前缀码
- 赫夫曼编码的构造
- 贪心选择是安全的
- 最优子结构
- 编码实现
- 编码树节点TreeNode
- 优先队列的实现
- 赫夫曼编码的构建
- maincc和Makefile
- 编译运行
贪心算法之赫夫曼编码
赫夫曼编码(Huffman coding)是一种编码方式,赫夫曼编码是变长编码的一种。可以有效的压缩数据,一般可以节约20%~90%的空间,这一般是由文件的数据特性决定的!
编码基本介绍
一般来说吗,文件可以分为两种:文本文件,二进制文件。这种区分只是逻辑上的一种区分,实际上文件在磁盘里面的存储都是以二进制一位一位存储的。文本文件就是基于字符编码的文件,常见的编码有ASCII码,utf8等等,二进制文件顾名思义就是直接在文件里面存入二进制数,也就全都是’0’和’1’,你可以自定义各个二进制的含义。
假设我们要保存一个文件,文件里面保存的全是ASCII码,那么这个文件里面的数据都是以八位对齐的,因为一个ASCII码占用八位,也就是一个字节。比如该文件里面存有’abcdef’,那么对应的文件里面二进制应该为’01100001·01100010·01100011·01100100·01100101·01100110’,文本编辑器在打开该文件的时候每次读出8位解释成对应的字符,于是我们就可以看到’abcdef’。
等长编码
但是你有没有发现,这样似乎太浪费内存了,ASCII之所以要用8位二进制来表示是因为它要表示128种字符,但是在这里就完全没有必要了,因为我们文件里面就只存储了六种字符,于是我们就新创一种新的编码来表示这六种字符:
于是上面的文件我们可以保存为’000·001·010·011·100·101’,在我们打开这个文件的时候就按照我们的编码显示相应的字符就可以啦。但是如果我们用编辑器打开文件的话,发现怎么全是乱码,因为这个编码是你自己创造的,编辑器是不认你的编码的,他们只认ASCII码。那麻烦了,那我们自己岂不是要写一个对应编码的编辑器了?这可不容易啊。。。于是我们想到了在保存的时候我们使用新的较短的编码,在读取的时候,再转换成ASCII码不就行啦,这里我们就实现了一个简单压缩与解压缩功能。
这里我们发现我们的新编码过的文件不是基于任何标准的编码的,而是基于我们自己创造的新的编码解释方式。换句话说,我们新编码的文件就是一个二进制文件。我们在这里建立的’000·001·010·011·100·101’就是这个文件对应的等长编码!在这里我们将文件按照等长编码从每个字符八位转换成每个字符三位,压缩了近乎 38
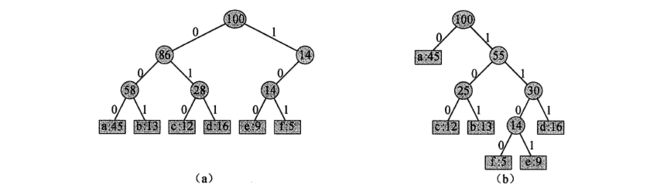
但是上面的每一个字符在文件中占有的比例是相同的,在现实中,各个字符在文件里面占有的比例一般是不同的。比如现在存在一个有100个字符的ASCII码文件:
占用的位数为: (45+13+12+16+9+5)∗3=300
变长编码
正如上面的等长编码的压缩过程,很大程度的压缩了文件,这样是最节省空间的编码方式么?我们采用一种变长编码的形式来重新压缩这个文件,将占有比重大的字符编码变短,将占有比重小的文件编码拉长
占用的位数为: 45∗1+13∗3+12∗3+16∗3+9∗4+5∗4=224 ,相比于上面的等长编码,大约节省了25%的空间
前缀码
这个理所谓的前缀码即没有任何码字是其他码字的前缀。前缀码是变长编码里面的一种,而且前缀码与任何编码相比可以达到最优的数据压缩率。下面我们就来介绍一下前缀码
我们主要将字符文件对应的前缀码按照顺序写入到二进制文件中,比如’abc’转化成对应的前缀码就是’0·101·100’。在我们将这个二进制文件转化为文本文件的过程中,就需要对这些前缀码进行解码,因为没有任何码字是其他码字的前缀,于是我们是可以按照前缀码来还原对应的字符的,比如’0·0·100·111’,解码以后就是’aacd’。我们用二叉树来表示前缀码的解码过程:
我们在二进制文件里面一位一位的读取,遇到’0’我们就转移到左子树,遇到’1’就转移到右子树,就这样不断地读取,直到遇到叶节点,最终的叶节点也就是我们需要的字符。找到字符以后我们再从文件里面读取一位,从根节点开始继续上面的操作直到文件末尾!
给定一棵前缀码的树 T ,我们可以计算编码一个文件需要多少位二进制。对于字母表 C 里面的每一个字符 c ,令属性 c.freq 为字符在文件中出现的频率,令 dt(c) 表示字符 c 在树中的深度, dt(c) 也是字符 c 的编码长度,则编码文件需要
个二进制位,将 B(T) 定义为树 T 的代价
赫夫曼编码的构造
赫夫曼设计了一个贪心算法来构造最优前缀码,即 B(T) 的代价最小,被称为赫夫曼编码。我们在之前讲过,要设计一个贪心算法,首先要经过三个步骤:
1.将最优化问题简化为这样的形式:最初一个选择以后,只剩下一个子问题需要求解!
2.证明在做出贪心选择以后,原问题总是存在最优解,即贪心选择总是安全的!
3.证明在做出贪心选择以后,剩下的子问题满足性质:其最优解与做出选择的组合在一起得到原问题的最优解,即最优子结构
那我们这里要做出怎么样的贪心选择呢?我们这里的目的是为了保证 B(T) 尽可能的小,那不妨大胆假设将出现次数/频率较低的的编码放在下层,出现次数/频率多的编码放在靠近根节点的位置。即我们做出这样的贪心选择策略:每次选出出现频率最低的两个字符 c1 , c2 ,并新建一个树节点 p ,使得树节点 p 成为字符 c1 , c2 的父节点,父节点对应的出现频率为 p.freq=c1.freq+c2.freq ,将 c1 , c2 从字符里面删除,并插入新的节点 p ,再次重复上面的动作选出两个频率最小的节点。。。知道只剩下一个节点,那么剩下的这个节点就是Huffman树的根节点!
贪心选择是安全的
下面我们来证明这样做是正确的贪心选择,首先贪心选择总是安全的
贪心选择总是安全的
引理:令 C 为一个字母表,其中每一个字符 c 都有一个对应的频率 c.freq 。令 x 和 y 是 C 中频率最低的两个字符,哪么存在一个最优前缀编码, x 和 y 码字长度相同,且只有最优一个二进制不同
证明:现在假设字符集有一最优前缀编码对应的编码树 T ,节点 a 和 b 是树 T 里面深度最大的两个兄弟叶节点,并满足 a.freq≤b.freq 。节点 x 和 y 是树 T 里面频率最低的两个叶节点,并满足 x.freq≤b.freq 。因为 a , b 是 T 里面任意频率的两个节点,因此有: x.freq≤a.freq 且 y.freq≤b.freq
- 如果 x.freq=b.freq 那么通过对 x.freq≤a.freq 且 y.freq≤b.freq 进行夹逼,可知 x.freq=y.freq=a.freq=b.freq ,我们将节点 x 和 a 交换,节点 y 和 b 交换,等到一棵新的编码树 T˙ ,因为 xyab 四个节点彼此相等,于是 T=T˙ ,所以 T˙ 也是一棵最优编码树,引理成立!
- 如果 x.freq≠b.freq ,我们交换 x 和 a 得到新编码树 T˙ , T˙ 中继续交换 y 和 b 得到新的编码树 T¨ ,现在我们需要做的是证明 T¨ 是最优编码树
我们知道树 T 和树 T˙ 的代价之差为:
B(T)−B(T˙)=∑c∈Cc.freq⋅dT(c)−∑c∈Cc.freq⋅dT˙(c)=x.freq∗dT(x)+a.freq∗dT(a)−x.freq∗dT˙(x)−a.freq∗dT˙(a)=x.freq∗dT(x)+a.freq∗dT(a)−x.freq∗dT(a)−a.freq∗dT(x)=(a.freq−x.freq)(dT(a)−dT(x))≥0
类似的,交换 y 和 b 也可以得到 B(T˙)−B(T¨)≥0
但是因为树 T 是最优编码树,不可能存在比 T 更优的编码树,于是 B(T)=B(T˙)=B(T¨) ,所以 T¨ 是最优编码树,引理成立!
因此这个贪心选择是安全的!
最优子结构
下面就需要证明最优子结构了
最优子结构
引理:令 C 为一个给定的字母表,其中每一个字符 c∈C 都有一个给定的频率 c.freq .令 x 和 y 是 C 里面的频率的两个字符,令 C˙ 为 C 去掉 x 和 y ,加入一个新的字符 z 之后得到的字母表,即 C˙=C−{x,y}∪{z} 。类似的,也为 C˙ 定义 freq ,不同之处在于 z.freq=x.freq+y.freq 。令 T˙ 为为字母表 C˙ 的最优前缀编码树。于是我们将节点 z 替换为一个以 x 和 y 为孩子节点内部节点。得到树 T ,那么树 T 是 C 的最优编码树。
证明:首先我们得到树 T 和 T˙ 之间代价的联系:首先我们知道 dT(x)=dT(y)=dT˙(z)+1 ,于是我们有:
x.freq⋅dT(x)+y.freq⋅dT(y)=(x.freq+y.freq)(dT˙(z)+1)=z.freq⋅dT˙(z)+(x.freq+y.freq)
于是我们得到结论:
B(T)=B(T˙)+x.freq+y.freq
即为
B(\dot T) = B(T) - x.freq - y.freqB(T˙)=B(T)−x.freq−y.freq
我们这里采用反证法来证明:假设存在编码树 \dot T T˙ 使得 B(\dot T) < B(T) B(T˙)<B(T) ,于是我们可以得到一棵在去掉节点 x x 和 y y ,并替换为新的节点 z z 的树 \ddot T T¨ ,既满足 \ddot T = \dot T - x.freq - y.freq T¨=T˙−x.freq−y.freq ,那么将会得到一棵更优的编码树,与原假设矛盾,所以引理成立!
于是我们有了最优子结构
由上面的贪心选择是安全的和最优子结构知道我们设计的贪心算法是正确的的!下面我们就开始编码来实现如何通过一个文件构造最优前缀码!
编码实现
在编码之前,我们还是先来画一下流程图
下面我们来分块实现这些功能:
编码树节点TreeNode
编码树节点TreeNode:
#ifndef TREE_NODE_H #define TREE_NODE_H #include <iostream> class TreeNode { public: TreeNode(float _percent = 0.0 , char _data = 0):percent(_percent),data(_data) { leftChild = NULL; rightChild = NULL; } float percent;// 存储百分比 char data;//存储实际的数据 TreeNode * leftChild;//左子树节点 TreeNode * rightChild;//右子树节点 bool operator<(const TreeNode & node) { return this->percent < node.percent; } bool operator>(const TreeNode & node) { return this->percent > node.percent; } bool operator==(const TreeNode & node) { return this->percent == node.percent; } }; #endif就是一个二叉树的节点,只是加入一些额外的数据
data存储字符
percent存储百分比
优先队列的实现
优先队列的实现
这里优先队列的主要作用是最快的速度选出队列里面字符出现频率最小的两个字符 x 和 y ,然后再向里面插入一个新的字符 z , z 保证 z.freq=x.freq+y.freq
优先队列的头文件
#ifndef PRIORITY_QUEUE_H #define PRIORITY_QUEUE_H #include "treeNode.h" #include <vector> #include <iostream> #define PARENT(i) ((i)>>1) #define LEFTCHILD(i) ((i)<<1) #define RIGHTCHILD(i) (((i)<<1)+1) class PriorityQueue { public: /** * 构造函数 * 数组的beginIter和endIter来构造优先队列 */ PriorityQueue(std::vector<TreeNode>::iterator beginIter , std::vector<TreeNode>::iterator endIter); /** 基本操作函数 */ void insert(const TreeNode & treeNode); TreeNode min() const; TreeNode extractMin(); void decreaseKey(unsigned int pos , const TreeNode & newKey); int size(){ return queueNumberCount; } void print() { for (int i = 1; i <= queueNumberCount; ++i) { std::cout<<queueData[i].percent<<"\t"; } std::cout<<std::endl; } private: // 定义队列的最大长度 static const int maxQueueNumber = 30; // 用来存放节点数据 TreeNode queueData[maxQueueNumber+1]; // 节点元素的计数 int queueNumberCount; // 维护堆的性质 void minHeapify(const unsigned int pos); // 构建最大堆 void buildMinHeap(); // 交换两个元素 void exchange(const unsigned int pos1 , const unsigned int pos2); }; #endif这里面实现了优先队列的一些基本的操作,优先对的具体内容请看之前介绍过优先队列的文章《优先队列》
优先队列的源文件
#include "priorityQueue.h" #include <iostream> #include <climits> PriorityQueue::PriorityQueue(std::vector<TreeNode>::iterator beginIter , std::vector<TreeNode>::iterator endIter) { queueNumberCount = 0; // copy data to queue data while(queueNumberCount != maxQueueNumber &&\ beginIter != endIter ) { queueData[++queueNumberCount] = *beginIter; ++beginIter; } // 开始建堆 buildMinHeap(); } /** * 维护堆的性质 * @param pos 维护的开始节点 */ void PriorityQueue::minHeapify(const unsigned int pos) { if(pos > queueNumberCount) return; int leftChild = LEFTCHILD(pos); int rightChild = RIGHTCHILD(pos); int minPos = pos; if(leftChild <= queueNumberCount && \ queueData[leftChild] < queueData[minPos]) minPos = leftChild; if(rightChild <= queueNumberCount &&\ queueData[rightChild] <queueData[minPos]) minPos = rightChild; if(minPos != pos) { exchange(minPos , pos); minHeapify(minPos); } } /** * 交换queueData里面的data * @param pos1 位置1 * @param pos2 位置2 */ void PriorityQueue::exchange(const unsigned int pos1 ,\ const unsigned int pos2) { if(pos1 > queueNumberCount || pos2 > queueNumberCount) return; TreeNode temp = queueData[pos1]; queueData[pos1] = queueData[pos2]; queueData[pos2] = temp; return; } /** * 构建最大堆 */ void PriorityQueue::buildMinHeap() { for (int i = queueNumberCount/2; i >=1 ; --i) { minHeapify(i); } } TreeNode PriorityQueue::min() const { if(queueNumberCount > 0) return queueData[1]; return TreeNode(); } TreeNode PriorityQueue::extractMin() { if(queueNumberCount <= 0) return TreeNode(); TreeNode minNode = queueData[1]; exchange(1,queueNumberCount); --queueNumberCount; minHeapify(1); return minNode; } void PriorityQueue::decreaseKey(unsigned int pos , const TreeNode & newKey) { if(pos > queueNumberCount || queueData[pos] < newKey) return; queueData[pos] = newKey; while(pos > 1) { int parentPos = PARENT(pos); if(queueData[parentPos] < queueData[pos]) break; exchange(parentPos , pos); pos = parentPos; } } void PriorityQueue::insert(const TreeNode & node) { if(queueNumberCount >= maxQueueNumber) return; TreeNode maxNode ; maxNode.percent = INT_MAX; queueData[++queueNumberCount] = maxNode; decreaseKey(queueNumberCount , node); }这里
extractMin和insert操作都是以 O(logn) 为时间代价的,速度应该是很快了,比采用一般方法,即采用插入排序的思想,每次都找到合适的插入位置要快的多!
赫夫曼编码的构建
赫夫曼编码的构建
这里才是进入正题了,就是构建赫夫曼编码
赫夫曼编码头文件
#ifndef HUFFMAN_CODE_H #define HUFFMAN_CODE_H #include <string> #include <iostream> #include "treeNode.h" void buildHuffmanCode(const std::string & filename);// 构建前缀码 void printHuffmanTree(TreeNode * tree , const std::string & prefix);> #endif赫夫曼编码的源文件实现
#include "huffmanCode.h" #include "priorityQueue.h" #include "treeNode.h" #include <iostream> #include <fstream> #include <vector>> void buildHuffmanCode(const std::string & filename) { // 读取文件里面的code,假设文件里面只包含26个小写英语字母 const int ascDiff = (int)'a'; const int & letterKind = 26; int letterCount[letterKind]; int sum = 0; for (int i = 0; i < letterKind; ++i) { letterCount[i] = 0; } // open the file std::ifstream infile(filename.c_str() , std::ios::in); std::string readLine; while(infile >> readLine) { for(std::string::iterator iter = readLine.begin() ; iter!= readLine.end() ; ++iter) { if('a'<=*iter && 'z'>= *iter) { letterCount[(int)*iter - ascDiff]++; sum++; } } } // create treeNode std::vector<TreeNode> recordVec; for (int i = 0; i < letterKind; ++i) { if(letterCount[i] != 0) { float percent = letterCount[i]/(float)sum; TreeNode newNode(percent , (char)(i+'a')) ; recordVec.push_back(newNode); } } // 下面开始构建最小堆 PriorityQueue pQueue(recordVec.begin() , recordVec.end()); pQueue.print(); // 下面开始建立编码树 TreeNode newNode; while(pQueue.size() > 1) { // get the min TreeNode minNode1 = pQueue.extractMin(); TreeNode minNode2 = pQueue.extractMin(); newNode.percent = minNode1.percent+minNode2.percent;> std::cout<<minNode1.percent<<"+"<<minNode2.percent<<"="<<newNode.percent<<std::endl; TreeNode * newTreeNode1 = new TreeNode(); *newTreeNode1 = minNode1; TreeNode * newTreeNode2 = new TreeNode(); *newTreeNode2 = minNode2;> newNode.leftChild = newTreeNode1; newNode.rightChild = newTreeNode2;> pQueue.insert(newNode); } // 编码树构建成功 // 这里的newNode就是我们目标编码树 std::string str; printHuffmanTree(&newNode , str); } void printHuffmanTree(TreeNode * tree , const std::string & prefix) { if(tree == NULL) return; if(tree->leftChild == NULL && tree->rightChild == NULL) { std::cout<<tree->data<<" ----> "<<prefix<<std::endl; } printTree(tree->leftChild , prefix+"0"); printTree(tree->rightChild , prefix+"1"); }这个文件里里面包含两个函数,一个是
buildHuffmanCode,目的是地区一个ACSII码文件,然后构建字符表,构建最小堆,再构建最优前缀编码二叉树,printHufmanCode就是将这棵二叉树上面的对应的huffman编码打印出来
main.cc和Makefile
main.cc
#include "huffmanCode.h" #include <iostream> using namespace std; int main(int argc, char const *argv[]) { if(argc!= 2) { cerr<<"usage: huffman <filename>"; return -1; } buildHuffmanCode(argv[1]); return 0; }输入一个文件名,然后解析这个文件
Makefile
TARGET=huffman OBJS=priorityQueue.o\ main.o\ treeNode.o\ huffmanCode.o SRCS=$(OBJS:.o=.cc) $(TARGET):$(OBJS) g++ $^ -o $@> %.o:%.cc %.h g++ -c $< -o $@
编译运行
我们现在有一ASCII文件letterFile
文件中各个字符出现的比例为:
字符出现次数a45b13c12d16e9f5
于是我们执行huffman letterFile得到下面结果:0.05 0.09 0.12 0.16 0.13 0.45
0.05+0.09=0.14
0.12+0.13=0.25
0.14+0.16=0.3
0.25+0.3=0.55
0.45+0.55=1
a —-> 0
c —-> 100
b —-> 101
f —-> 1100
e —-> 1101
d —-> 111
为了方便大家参考,博主将源文件放在了这里:http://download.csdn.net/detail/ii1245712564/8686775,供大家下载学习