除Hadoop外的9个大数据技术:
1.Apache Flink
2.Apache Samza
3.Google Cloud Data Flow
4.StreamSets
5.Tensor Flow
6.Apache NiFi
7.Druid
8.LinkedIn WhereHows
9.Microsoft Cognitive Services
Hadoop是大数据领域最流行的技术,但并非唯一。还有很多其他技术可用于解决大数据问题。除了Apache Hadoop外,另外9个大数据技术也是必须要了解的。
1.Apache Flink
是一个高效、分布式、基于Java实现的通用大数据分析引擎,它具有分布式MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。
这是一种由社区驱动的分布式大数据分析开源框架,类似于Apache Hadoop和Apache Spark。它的引擎可借助数据流和内存中(in-memory)处理与迭代操作改善性能。目前Apache Flink已成为一个顶级项目(Top Level Project,TLP),于2014年4月被纳入Apache孵化器,目前在全球范围内有很多贡献者。
Flink受到了MPP数据库技术(Declaratives、Query Optimizer、Parallel in-memory、out-of-core 算法)和Hadoop MapReduce技术(Massive scale out, User Defined functions, Schema on Read)的启发,有很多独特功能(Streaming, Iterations, Dataflow, General API)。
2.Apache Samza:
是一个开源、分布式的流处理框架,它使用开源分布式消息处理系统Apache Kafka来实现消息服务,并使用资源管理器Apache Hadoop Yarn实现容错处理、处理器隔离、安全性和资源管理。
该技术由LinkedIn开发,最初目的是为了解决Apache Kafka在扩展能力方面存在的问题,包含诸如Simple API、Managed state、Fault Tolerant、Durable messaging、Scalable、Extensible,以及Processor Isolation等功能。

Samza的代码可作为Yarn作业运行,还可以实施StreamTask接口,借此定义process()调用。StreamTask可以在任务实例内部运行,其本身也位于一个Yarn容器内。
3.Cloud Dataflow:
Dataflow是一种原生的Google Cloud数据处理服务,是一种构建、管理和优化复杂数据流水线的方法,用于构建移动应用,调试、追踪和监控产品级云应用。它采用了Google内部的技术Flume和MillWhell,其中Flume用于数据的高效并行化处理,而MillWhell则用于互联网级别的带有很好容错机制的流处理。
该技术提供了简单的编程模型,可用于批处理和流式数据的处理任务。该技术提供的数据流管理服务可控制数据处理作业的执行,数据处理作业可使用Data Flow SDK(Apache Beam)创建。

Google Data Flow为数据相关的任务提供了管理、监视和安全能力。Sources和Sink可在管线中抽象地执行读写操作,管线封装而成的整个计算序列可以接受外部来源的某些输入数据,通过对数据进行转换生成一定的输出数据。
4.StreamSets:
StreamSets是一种专门针对传输中数据进行过优化的数据处理平台,提供了可视化数据流创建模型,通过开源的方式发行。该技术可部署在内部环境或云中,提供了丰富的监视和管理界面。
数据收集器可使用数据管线实时地流式传输并处理数据,管线描述了数据从源头到最终目标的流动方式,可包含来源、目标,以及处理程序。数据收集器的生命周期可通过管理控制台进行控制。
5.TensorFlow:
是继DistBelief之后的第二代机器学习系统。TensorFlow源自Google旗下的Google Brain项目,主要目标在于为Google全公司的不同产品和服务应用各种类型的神经网络机器学习能力。
支持分布式计算的TensorFlow能够使用户在自己的机器学习基础结构中训练分布式模型。该系统以高性能的gRPC数据库为支撑,与最近发布的Google云机器学习系统互补,使用户能够利用Google云平台,对TensorFlow模型进行训练并提供服务。
这是一种开源软件库,可使用数据流图谱(data flow graph)进行数值运算,这种技术已被包括DeepDream、RankBrain、Smart Replyused在内的各种Google项目所使用。

数据流图谱使用由节点(Node)和边缘(Edge)组成的有向图(Directed graph)描述数值运算。图谱中的节点代表数值运算,边缘代表负责在节点之间进行通信的多维数据阵列(张量,Tensor)。边缘还描述了节点之间的输入/输出关系。“TensorFlow”这个名称蕴含了张量在图谱上流动的含义。
6.Druid:
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析,诞生于2011年,包含诸如驱动交互式数据应用程序,多租户:大量并发用户,扩展能力:每天上万亿事件,次秒级查询,实时分析等功能。Druid还包含一些特殊的重要功能,例如低延迟数据摄入、快速聚合、任意切割能力、高可用性、近似计算与精确计算等。
创建Druid的最初意图主要是为了解决查询延迟问题,当时试图使用Hadoop来实现交互式查询分析,但是很难满足实时分析的需要。而Druid提供了以交互方式访问数据的能力,并权衡了查询的灵活性和性能而采取了特殊的存储格式。
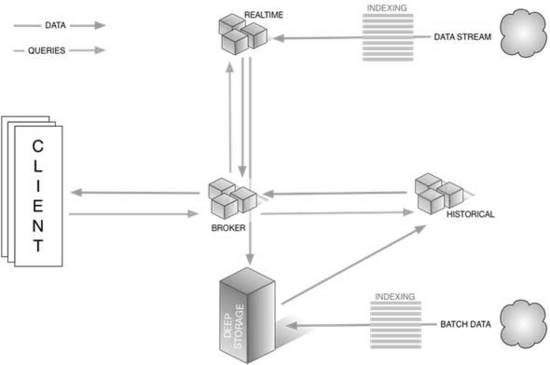
该技术还提供了其他实用功能,例如实时节点、历史节点、Broker节点、Coordinator节点、使用基于JSON查询语言的索引服务。 了解详情
7.Apache NiFi:
Apache NiFi是一套强大可靠的数据处理和分发系统,可用于对数据的流转和转换创建有向图。借助该系统可以用图形界面创建、监视、控制数据流,有丰富的配置选项可供使用,可在运行时修改数据流,动态创建数据分区。此外还可以对数据在整个系统内的流动进行数据起源跟踪。通过开发自定义组件,还可轻松对其进行扩展。
Apache NiFi的运转离不开诸如FlowFile、Processor,以及Connection等概念。
8.LinkedIn WhereHows:
WhereHows提供带元数据搜索的企业编录(Enterprise catalog),可以让您了解数据存储在哪里,是如何保存到那里的。该工具可提供协作、数据血统分析等功能,并可连接至多种数据源和提取、加载和转换(ETL)工具。
该工具为数据发现提供了Web界面,支持API的后端服务器负责控制元数据的爬网(Crawling)以及与其他系统的集成。
9.Microsoft Cognitive Services:
该技术源自Project Oxford和Bing,提供了22种认知计算API,主要分类包括:视觉、语音、语言、知识,以及搜索。该技术已集成于Cortana Intelligence Suite。
这是一种开源技术,提供了22种不同的认知计算REST API,并为开发者提供了适用于Windows、IOS、Android以及Python的SDK。
阿里百川(baichuan.taobao.com) 是阿里巴巴集团的无线开放平台,通过“技术、商业及大数据”的开放,提供移动场景下的高内聚、开放式、行业领先的技术产品矩阵、成熟的商业组件和完善的服务体系,帮助移动开发者快速搭建APP、加速APP商业化进程,全方位赋能移动开发者及移动创业者。