浅析Redis复制
早期的 RDBMS 被设计为运行在单个CPU之上,读写操作都由经单个数据库实例完成,复制技术使得数据库的读写操作可以分散在运行于不同CPU之上的独立服务器上.Redis作为一个开源的、优秀的key-value缓存及持久化存储解决方案,也提供了复制功能,本文主要介绍Redis的复制原理及特性。
Redis复制概论
数据库复制指的是发生在不同数据库实例之间,单向的信息传播的行为,通常由被复制方和复制方组成,被复制方和复制方之间建立网络连接,复制方式通常为被复制方主动将数据发送到复制方,复制方接收到数据存储在当前实例,最终目的是为了保证双方的数据一致、同步。
Redis复制方式
Redis的复制方式有两种,一种是主(master)-从(slave)模式,一种是从(slave)-从(slave)模式,因此Redis的复制拓扑图会丰富一些,可以像星型拓扑,也可以像个有向无环:
通过配置多个Redis实例独立运行、定向复制,形成Redis集群,master负责写、slave负责读。
复制优点
通过配置多个Redis实例,数据备份在不同的实例上,主库专注写请求,从库负责读请求,这样的好处主要体现在下面几个方面:
a)高可用性
在一个Redis集群中,如果master宕机,slave可以介入并取代master的位置,因此对于整个Redis服务来说不至于提供不了服务,这样使得整个Redis服务足够安全。
b)高性能
在一个Redis集群中,master负责写请求,slave负责读请求,这么做一方面通过将读请求分散到其他机器从而大大减少了master服务器的压力,另一方面slave专注于提供读服务从而提高了响应和读取速度。
c)水平扩展性
通过增加slave机器可以横向(水平)扩展Redis服务的整个查询服务的能力。
复制缺点
复制提供了高可用性的解决方案,但同时引入了分布式计算的复杂度问题,认为有两个核心问题:
a)数据一致性问题,如何保证master服务器写入的数据能够及时同步到slave机器上。
b)编程复杂,如何在客户端提供读写分离的实现方案,通过客户端实现将读写请求分别路由到master和slave实例上。
上面两个问题,尤其是第一个问题是Redis服务实现一直在演变,致力于解决的一个问题。
复制实时性和数据一致性矛盾
Redis提供了提高数据一致性的解决方案,本文后面会进行介绍,一致性程度的增加虽然使得我能够更信任数据,但是更好的一致性方案通常伴随着性能的损失,从而减少了吞吐量和服务能力。然而我们希望系统的性能达到最优,则必须要牺牲一致性的程度,因此Redis的复制实时性和数据一致性是存在矛盾的。
slave指向master
举个例子,我们有四台redis实例,M1,R1、R2、R3,其中M1为master,R1、R2、R3分别为三台slave redis实例。在M1启动如下:
./redis-server ../redis8000.conf --port 8000
下面分别为R1、R2、R3的启动命令:
./redis-server ../redis8001.conf --port 8001 --slaveof 127.0.0.1 8000 ./redis-server ../redis8002.conf --port 8002 --slaveof 127.0.0.1 8000 ./redis-server ../redis8003.conf --port 8003 --slaveof 127.0.0.1 8000这样,我们就成功的启动了四台Redis实例,master实例的服务端口为8000,R1、R2、R3的服务端口分别为8001、8002、8003,集群图如下:
上面的命令在slave启动的时候就指定了master机器,我们也可以在slave运行的时候通过slaveof命令来指定master机器。

复制过程
Redis复制主要由SYNC命令实现,复制过程如下图:
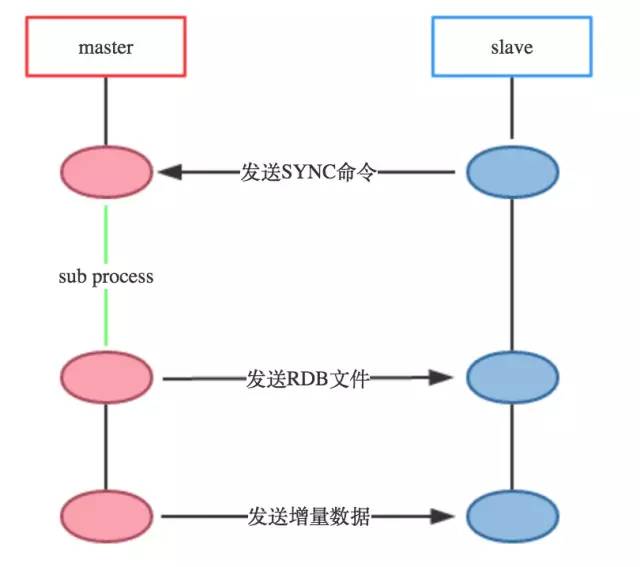
上图为Redis复制工作过程:
a) slave向master发送sync命令。
b) master开启子进程来讲dataset写入rdb文件,同时将子进程完成之前接收到的写命令缓存起来。
c) 子进程写完,父进程得知,开始将RDB文件发送给slave。
d) master发送完RDB文件,将缓存的命令也发给slave。
e) master增量的把写命令发给slave。
值得注意的是,当slave跟master的连接断开时,slave可以自动的重新连接master,在redis2.8版本之前,每当slave进程挂掉重新连接master的时候都会开始新的一轮全量复制。如果master同时接收到多个slave的同步请求,则master只需要备份一次RDB文件。
增量复制
上面复制过程介绍的最后提到,slave和master断开了、当slave和master重新连接上之后需要全量复制,这个策略是很不友好的,从Redis2.8开始,Redis提供了增量复制的机制:
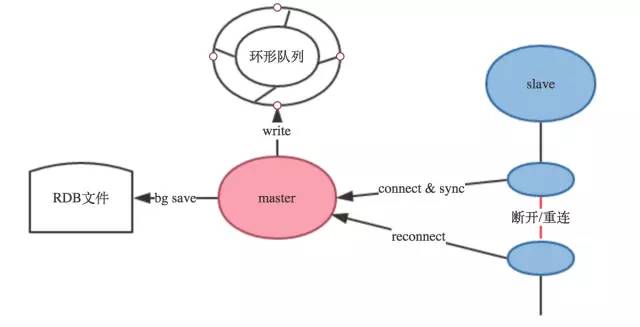
master除了备份RDB文件之外还会维护者一个环形队列,以及环形队列的写索引和slave同步的全局offset,环形队列用于存储最新的操作数据,当slave和maste断开重连之后,会把slave维护的offset,也就是上一次同步到哪里的这个值告诉master,同时会告诉master上次和当前slave连接的master的runid,满足下面两个条件,Redis不会全量复制:
a) slave传递的run id和master的run id一致。
b) master在环形队列上可以找到对的offset的值
满足上面两个条件,Redis就不会全量复制,这样的好处是大大的提高的性能,不做无效的功。
增量复制是由psync命令实现的,slave可以通过psync命令来让Redis进行增量复制,当然最终是否能够增量复制取决于环形队列的大小和slave的断线时间长短和重连的这个master是否是之前的master。
环形队列大小配置参数:
repl-backlog-size 1mb
Redis同时也提供了当没有slave需要同步的时候,多久可以释放环形队列:
repl-backlog-ttl 3600
免持久化复制
免持久化机制官方叫做Diskless Replication,前面基于RDB文件写磁盘的方式可以看出,Redis必须要先将RDB文件写入磁盘,才进行网络传输,那么为什么不能直接通过网络把RDB文件传送给slave呢?免持久化复制就是做这个事情的,而且在Redis2.8.18版本开始支持,当然目前还是实验阶段。
值得注意的是,一旦基于Diskless Replication的复制传送开始,新的slave请求需要等待这次传输完毕才能够得到服务。
是否开启Diskless Replication的开关配置为:
repo-diskless-sync no
为了让后续的slave能够尽量赶上本次复制,Redis提供了一个参数配置指定复制开始的时间延迟:
repl-diskless-sync-delay 5
slave只读模式
自从Redis2.6版本开始,支持对slave的只读模式的配置,默认对slave的配置也是只读。只读模式的slave将会拒绝客户端的写请求,从而避免因为从slave写入而导致的数据不一致问题。
半同步复制
和MySQL复制策略有点类似,Redis复制本身是异步的,但也提供了半同步的复制策略,半同步复制策略在Redis复制中的语义是这样的:
允许用户给出这样的配置:在maste接受写操作的时候,只有当一定时间间隔内,至少有N台slave在线,否则写入无效。
上面功能的实现基于Redis下面特性:
a) Redis slaves每秒钟会ping一次master,告诉master当前slave复制到哪里了。
b) Redis master会记住每个slave复制到哪里了。
我们可以通过下面配置来指定时间间隔和N这个值:
min-slaves-to-write min-slaves-max-lag
当配置了上面两个参数之后,一旦对于一个写操作没有满足上面的两个条件,则master会报错,并且将本次写操作视为无效。这有点像CAP理论中的“C”,即一致性实现,虽然半同步策略不能够完全保证master和slave的数据一致性,但是相对减少了不一致性的窗口期。
原文:http://mp.weixin.qq.com/s?__biz=MzA5ODM5MDU3MA==&mid=2650861687&idx=1&sn=63e9798ebbbd904f297f2aff2fd00c29&scene=23&srcid=0530psTbMWy8mcjJxJJE3On4#rd