hadoop实战之eclipse开发环境搭建
前言
上一篇博客里面讲了如何搭建hadoop环境。如果你不了解,请参考:hadoop环境搭建(伪分布式)。
这篇文章的主要目的是eclipse开发环境的搭建,如果你已经一步一步地根据上一篇博客的步骤来搭建好环境的话,那么接下来的事情就很简单了。
步骤
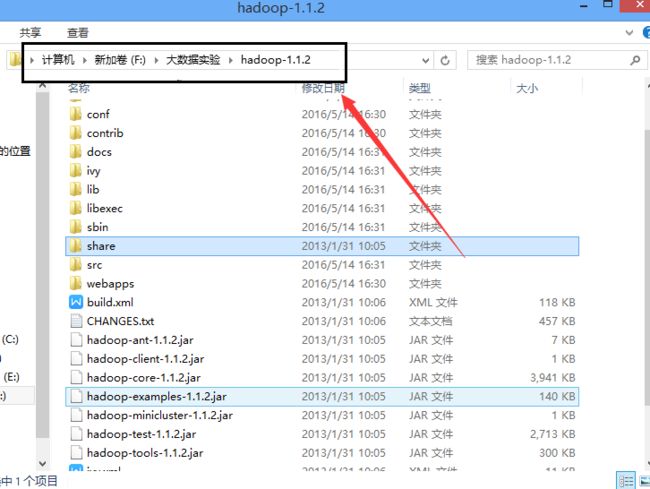
1、我们现在把之前放到ubuntu里面的hadoop-1.1.2.tar.gz这个文件复制出来。然后解压到windows任意文件夹,为了演示,我就解压到了这个文件夹了(F:\大数据实验\hadoop-1.1.2):
2、找到hadoop-eclipse-plugin-1.1.2.jar这个包,复制到你下载下来并解压的eclipse的plugin文件夹中。至于eclipse怎么下,百度就行0.0。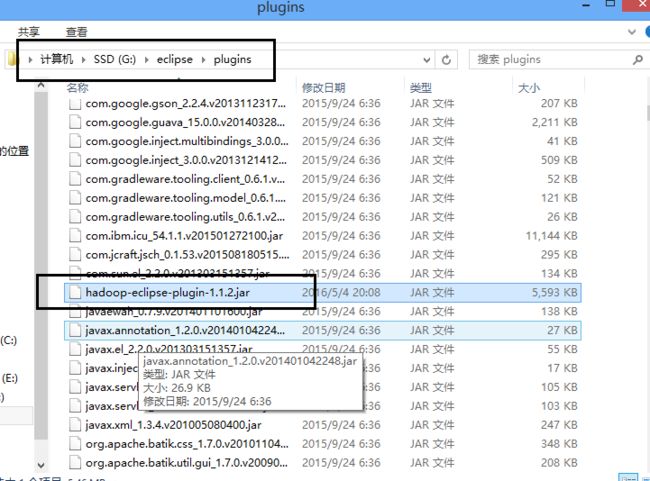
3、现在启动eclipse,现在会发现,eclipse已经自动加载了hadoop-eclipse-plugin-1.1.2.jar这个包。我们现在得打开下面这个选项:

然后我们会发现,现在比之前多了一个hadoop map/reduce选项:
现在我们在旁边的Hadoop installation directory这里填上我们刚刚解压的hadoop包的路径(F:\大数据实验\hadoop-1.1.2),然后完成。
4、OK,现在我们又会发现,eclipse主界面的右上角多了一个玩意儿,那就是:

我们现在选择<Map/Reduce>。
5、好吧,现在我们得新建一个hadoop location:
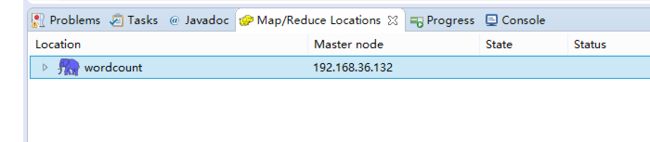
在这里,右键——>new hadoop location。然后再写上相关的配置:
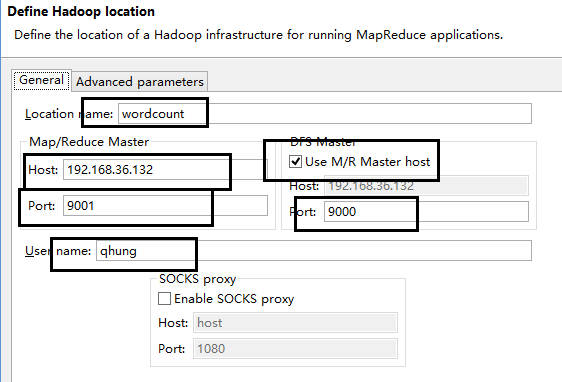
- location name随便写
- host为你linux的IP 地址。
- username为你linux用户名
- 端口号固定的,之前在上一篇博客里面hadoop配置里配置过了。
现在打开advanced parameters:
配置hadoop.tmp.dir,这个路径我们也在上一篇博客里面配置好了,在 core-site.xml 这个配置文件里有写,我当时配置的是/home/qhung/Public/temp,所以这里就写/home/qhung/Public/temp。
好了,现在配置完成,接下来打开hadoop,上一篇博客也介绍过了怎么打开。现在我们又会发现,左侧project explorer栏里面多了一个:
如果你打开这个DFS Locations,出现的是类似我这个界面,说明你的eclipse已经连接上了linux里面的hadoop。当然,这里一般都会出现很多问题,这个需要耐心一个一个地去解决。一般就是防火墙没关啊什么的问题。
现在这个地方可以上传文件和下载文件,这里对应的是linux中hadoop的HDFS文件系统,后面运行的wordcount例子的输入文件就会上传到这里面。
我们现在已经配置好了eclipse开发环境,接下来我们来运行一个简单的例子。
wordcount程序
这个程序是统计文本中各单词出现的次数的,也是很多学者的入门程序。
首先在eclipse中 ,新建一个map/reduce工程:
File->new->other->map reduce project。然后填写上项目名就可以finish了。
先来看看项目的结构:
框里面是我们要写的东西,过会儿再说,下面很多jar包,其实就是我们解压后的hadoop文件夹里面的jar包,我们程序里面要用到的。
先贴出WordCount.java里面的内容:
package wordcount;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
String s = tokenizer.nextToken();
word.set(s);
System.out.println(s);
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
String[] path = new String[2];
path[0] = "hdfs://192.168.36.132:9000/home/qhung/Public/wordcount/wordcount.txt";
path[1] = "hdfs://192.168.36.132:9000/home/qhung/Public/wordcount/WordCountoutput";
String[] otherArgs = new GenericOptionsParser(conf, path).getRemainingArgs();
conf.setJobName("worscount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(conf, new Path(otherArgs[1]));
JobClient.runJob(conf);
}
}
代码的话,以后再讲,现在先把代码贴进去。然后再在dfs location里面上传输入文件,这个文件对应的是上面程序是path[0]的输入文件位置:
然后直接运行程序,运行成功后:
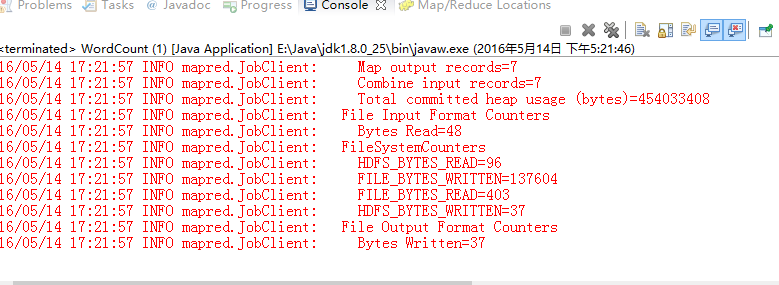
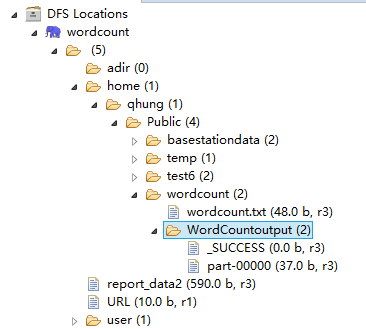
里面的part-00000就是输出文件,我们可以打开看看,输出的结果。

到此,我们的第一个程序运行成功。