Linux Shell 学习笔记
最近在linux下面编写shell脚本,差不多是边学边写。在此记录一些学习心得。
一)shell的引号。
shell的引号有单引号',双引号",反引号`。
由单引号括起来的字符都作为普通字符出现。特殊字符用单引号括起来以后,也会失去原有意义,而只作为普通字符解释。
由双引号括起来的字符,除$、倒引号(`)和反斜线(\)仍保留其特殊功能外,其余字符均作为普通字符对待。“$”表示变量替换,即用其后指定的变量的值来代替$和变量;倒引号表示命令替换;仅当“\”后面的字符是下述字符之一时,“\”才是转义字符,这些字符是:“$”、“`”、“"”、“\”或换行符。转义字符告诉Shell不要对其后面的那个字符进行特殊处理,只是当作普通字符。
倒引号括起来的字符串被shell解释为命令行,在执行时,Shell会先执行该命令行,并以它的标准输出结果取代整个倒引号部分。
二)目录权限。
文件或目录的访问权限分为只读(r),只写(w)和可执行(x)三种。
当我们用ls -l命令的时候,会看到如下内容

其中第一列我们看到了-rw-r--r--的字符,这个就表示当前的文件的权限。
横线代表空许可。注意这里共有10个位置。第一个字符指定了文件类型。在通常意义上,一个目录也是个文件。如果第一个字符是横线,表示是个非目录的文件。如果是d,表示是个目录。除第一个位置外,剩下的每连续三个表示一个权限,第一个连续三字符表示文件拥有者的权限,比如这里的”rw-“表示文件拥有着具有可读可写的权限。第二个连续三字符”r--“表示文件拥有着所在组具有的权限,这里的”r--“表示只读。后面连续三字符表示所有用户的权限,也是只读。
在权限设置中,我们为了简化这种权限设置,通常把r、w、x分别用4、2、1表示,然后把它们相加表示文件的权限。比如上面的两个文件的权限就是644。又比如一个文件的权限是754,那就表示文件的拥有者具有可读可写可执行的权限,所在组具有读和执行的权限,其他用户具有读的权限。
我们可以通过chmod来修改一个文件的权限。这里有两种方式,首先是数字设定法,我们只需要运行下面的命令

或者使用文字设定法,如下

文字设定法中的u+x,g-w-r,o-x-r就表示设定权限,其中u,g,o分别表示文件拥有者,所在组用户,其他用户,而+,-对应增加与删除权限。
当然使用chmod修改文件权限只能是超级用户和文件的拥有者。
除此之外,我们还能用户chgrp修改文件所属组,chown修改文件所属用户或组。
语法:chgrp [选项] 用户组 文件
语法:chown [选项] 用户或组 文件
三)变量。
shell中的变量不需要声明,赋值的话直接[变量名=值]就可以了。比如
num=1 me=fly
在shell中变量引用有几个需要注意的地方,比如你在脚本中使用下面的语句时
echo "I'm ${me}Baby"这时候就不能直接使用$meBaby,因为shell解释的时候就会去找meBaby这个变量。而你只有me这个变量。
在shell中实现变量的运算时,需要注意几个地方,看下图的执行结果
从上面的执行结果我们可以看出,使用shell变量就行运算的时候,可以使用中括号,双小括号,以及expr运算关键字。
除了以上基本的变量外,shell里面还有一些特殊的参数。如下面的参数:
$0 = shell名称或shell脚本名称 $1 = 第一个shell参数 ...
$9 = 第九个shell参数 $# = 位置参数的个数
"$*" = "$1 $2 $3 $4 .. $n",以一个单字符串显示所有向脚本传递的参数。与位置变量不同,此选项参数可超过9个。
"$@" = "$1" "$2" "$3" "$4" .. "$n",与$#相同,但是使用时加引号,并在引号中返回每个参数。
$# 传递到脚本的参数个数。
$- 显示shell使用的当前选项,与set命令功能相同。
$? = 最近执行的命令的退出状态,0表示没有错误,其他任何值表明有错误。
$$ = 当前shell脚本的PID。
$! = 最近启动的后台作业的PID。
形式 如果设置了var 如果没设置var
${var:-string} $var string
${var:+string} string null
${var:=string} $var string (并执行var = string)
${var:?string} $var 返回string然后退出
形式 结果
${var%suffix} 删除位于var结尾的最小匹配模式
${var%%suffix} 删除位于var结尾的最大匹配模式
${var#suffix} 删除位于var开头的最小匹配模式
${var##suffix} 删除位于var开头的最大匹配模式
四)条件与循环。
跟其他编程语言一样,shell中包含if条件语句,while,for,until循环,以及case和select语句。首先介绍if条件语句
if语句结构[if/then/elif/else/fi],其中[ ]与变量之间有空格。
if [ $y -eq 1 ];then y=$(($y+1)) else y=1 fishell命令,可以按照分号分割,也可以按照换行符分割。如果想一行写入多个命令,可以通过“';”分割。
num=3;if [ $num -eq 1 ] ;then echo 1; elif [ $num -eq 2 ] ;then echo 2;else echo 3;fi;在if条件语句中,可以对数字字符串进行大小,匹配比较,还可以对文件夹、文件的权限、存在与否进行判断。
五)函数。
六)时间。
七)grep,sed,awk,tr等工具的使用。
我们从例子入手,下面有一个文件f中的域名取出并排序,内容如下,
http://www.fly_sky520.org/index.html http://www.fly_sky520.org/1.html http://post.fly_sky520.org/index.html http://mp3.fly_sky520.org/index.html http://www.fly_sky520.org/3.html http://post.fly_sky520.org/2.html*注意,各行之间有空行。下面看我的操作
1)首先利用grep与awk工具。
该方法先利用grep -v 取非空行数据,-v参数是反向检索的意思。效果如下:
然后利用awk工具取以"/"分隔符分割的第三个参数,也就是域名了。

最后利用sort进行排序,用nuiq -c计数
所以第一个完整命令就是
cat f | grep -v '^$'|awk -F/ '{print $3}'|sort|uniq -c
2)利用tr与grep工具
首先利用tr工具的替换功能

再利用grep工具查找包含域名的项

最后排序计数

所以完整命令就是
cat f |tr "\/" "\n" | grep fly | sort | uniq -c
首先使用cut工具取出域名
cut -d/ -f3的意思就是把文件内容以“/”作为分隔符,并去取出第三部分显示。-d就是自定义分隔符的意思,默认分隔符为制表符,-f就是显示区域
然后,我们再利用tr工具去除空行
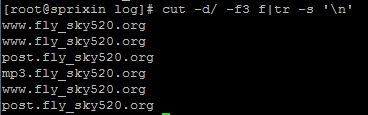
最后排序计数

所以最后的方法为
cut -d/ -f3 f|tr -s '\n'|sort | uniq -c
4)利用sed工具
首先利用sed工具去除空行

sed命令中d为删除的意思。//之间为正则表达式^$表示空行。然后再利用sed的‘s///g’字符替换功能

最后还是排序计数
sed的编辑功能相当强大,比如我要修改配置文件f中【name = “Fly” 】的name为Sky。我只需要输入以下命令
其中-i就是直接修改文件内容的选项,这个命令的操作就是通过/name/先查找出name行,然后修改对应的值。
下面是一些sed的例子
6. 实例
删除:d命令
$ sed '2,$d' example-----删除example文件的第二行到末尾所有行。
$ sed '$d' example-----删除example文件的最后一行。
替换:s命令
$ sed -n 's/^test/mytest/p' example-----(-n)选项和p标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的test被替换成mytest,就打印它。
$ sed 's/^192.168.0.1/&localhost/' example-----&符号表示替换换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加 localhost,变成192.168.0.1localhost。
$ sed -n 's/\(love\)able/\1rs/p' example-----love被标记为1,所有loveable会被替换成lovers,而且替换的行会被打印出来。
$ sed 's#10#100#g' example-----不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。
选定行的范围:逗号
$ sed -n '/test/,/check/p' example-----所有在模板test和check所确定的范围内的行都被打印。
$ sed -n '5,/^test/p' example-----打印从第五行开始到第一个包含以test开始的行之间的所有行。
$ sed '/test/,/check/s/$/sed test/' example-----对于模板test和west之间的行,每行的末尾用字符串sed test替换。
多点编辑:e命令
$ sed -e '1,5d' -e 's/test/check/' example-----(-e)选项允许在同一行里执行多条命令。如例子所示,第一条命令删除1至5行,第二条命令用check替换test。命令的执 行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
$ sed --expression='s/test/check/' --expression='/love/d' example-----一个比-e更好的命令是--expression。它能给sed表达式赋值。
从文件读入:r命令
$ sed '/test/r file' example-----file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面。
写入文件:w命令
$ sed -n '/test/w file' example-----在example中所有包含test的行都被写入file里。
追加命令:a命令
$ sed '/^test/a\\--->this is a example' example<-----'this is a example'被追加到以test开头的行后面,sed要求命令a后面有一个反斜杠。
插入:i命令
$ sed '/test/i\\
new line
-------------------------' example
如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面。
下一个:n命令
$ sed '/test/{ n; s/aa/bb/; }' example-----如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续。
变形:y命令
$ sed '1,10y/abcde/ABCDE/' example-----把1--10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令。
退出:q命令
$ sed '10q' example-----打印完第10行后,退出sed。
保持和获取:h命令和G命令
$ sed -e '/test/h' -e '$G example-----在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将 打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保 持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中 的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。
保持和互换:h命令和x命令
$ sed -e '/test/h' -e '/check/x' example -----互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换。
以上实例内容摘自网友icyheart的帖子,地址是http://www.iteye.com/topic/587673。
八)定时任务。