spark机器学习笔记:(六)用Spark Python构建回归模型
声明:版权所有,转载请联系作者并注明出处 http://blog.csdn.net/u013719780?viewmode=contents
博主简介:风雪夜归子(英文名:Allen),机器学习算法攻城狮,喜爱钻研Meachine Learning的黑科技,对Deep Learning和Artificial Intelligence充满兴趣,经常关注Kaggle数据挖掘竞赛平台,对数据、Machine Learning和Artificial Intelligence有兴趣的童鞋可以一起探讨哦,个人CSDN博客:http://blog.csdn.net/u013719780?viewmode=contents
分类模型处理表示类别的离散变量,而回归模型则处理可以取任意实数的目标变量。但是二者基本的原则类似,都是通过确定一个模型,将输入特征映射到预测的输出。回归模型和分类模型都是监督学习的一种形式。
回归模型可以用在如下一些场景:
预测股票收益和其他经济相关的因素;
预测贷款违约造成的损失(可以和分类模型相结合,分类模型预测违约概率,回归模型预测违约损失);
推荐系统(博文 spark机器学习笔记:(三)用Spark Python构建推荐系统 中的交替最小二乘分解模型在每次迭代时都使用了线性回归);
基于用户的行为和消费模式,预测顾客对于零售、移动或者其他商业形态的存在价值。
本文主要内容如下:
介绍MLlib中的各种回归模型;
讨论回归模型的特征提取和目标变量的变换;
使用MLlib训练回归模型;
介绍如何用训练好的模型做预测;
使用交叉验证研究设置不同的参数对性能的影响。
1 特征提取
因为回归的基础模型和分类模型一样,所以我们可以使用同样的方法来处理输入的特征。实际中唯一的不同是,回归模型的预测目标是实数变量,而分类模型的预测目标是类别编号。为了满足两种情况,MLlib中的LabeledPoint类已经考虑了这一点,类中的label字段使用Double类型。本文选择bike sharing数据集做实验。这个数据集记录了bike
sharing系统每小时自行车的出租次数。另外还包括日期、时间、天气、季节和节假日等相关信息(bike sharing数据集下载地址:http://archive.ics.uci.edu/ml/datasets/Bike+Sharing+Dataset)。各个字段的含义如下:
- instant: record index
- dteday : date
- season : season (1:springer, 2:summer, 3:fall, 4:winter)
- yr : year (0: 2011, 1:2012)
- mnth : month ( 1 to 12)
- hr : hour (0 to 23)
- holiday : weather day is holiday or not (extracted from http://dchr.dc.gov/page/holiday-schedule)
- weekday : day of the week
- workingday : if day is neither weekend nor holiday is 1, otherwise is 0.
+ weathersit :
- 1: Clear, Few clouds, Partly cloudy, Partly cloudy
- 2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
- 3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
- 4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
- temp : Normalized temperature in Celsius. The values are divided to 41 (max)
- atemp: Normalized feeling temperature in Celsius. The values are divided to 50 (max)
- hum: Normalized humidity. The values are divided to 100 (max)
- windspeed: Normalized wind speed. The values are divided to 67 (max)
- casual: count of casual users
- registered: count of registered users
- cnt: count of total rental bikes including both casual and registered
输入命令 sed 1d hour.csv > hour_noheader.csv,将文件hour.csv的第一行头文件去掉并保存到新的 hour_noheader.csv。
import numpy as np
path = '/Users/youwei.tan/Desktop/Bike-Sharing-Dataset/hour_noheader.csv'
raw_data = sc.textFile(path)
num_data = raw_data.count()
records =raw_data.map(lambda x: x.split(','))
first = records.first()
print '数据的第一行:',first
print '数据样本数:',num_data
输出结果:
数据的第一行: [u'1', u'2011-01-01', u'1', u'0', u'1', u'0', u'0', u'6', u'0', u'1', u'0.24', u'0.2879', u'0.81', u'0', u'3', u'13', u'16']
数据样本数: 17379
结果显示,数据集中共有17 379个小时的记录。接下来的实验,我们会忽略记录中的instant和dteday 。忽略两个记录次数的变量casual 和registered , 只保留cnt ( casual 和
registered的和)。最后就剩下12个变量,其中前8个是类型变量,后4个是归一化后的实数变量。对其中8个类型变量,我们使用之前提到的二元编码,剩下4个实数变量不做处理。
因为变量records下文经常要用到,此处对其进行缓存:
records.cache()
为了将类型特征表示成二维形式,我们将特征值映射到二元向量中非0的位置。下面定义这样一个映射函数:
def get_mapping(rdd, idx):
return rdd.map(lambda fields: fields[idx]).distinct().zipWithIndex().collectAsMap()
上面的函数首先将第idx列的特征值去重,然后对每个值使用zipWithIndex函数映射到一个唯一的索引,这样就组成了一个RDD的键值映射,键是变量,值是索引。上述索引便是特征在二元向量中对应的非0位置,最后我们将这个RDD表示成Python的字典类型。
下面,我们用特征矩阵的第三列(索引2)来测试上面的映射函数:
print '第三个特征的类别编码: %s '%get_mapping(records,2)
输出结果:
第三个特征的类别编码: {u'1': 0, u'3': 1, u'2': 2, u'4': 3}
接着,对是类型变量的列(第2~9列)应用该函数:
mappings = [get_mapping(records, i) for i in range(2,10)] #对类型变量的列(第2~9列)应用映射函数
print '类别特征打编码字典:',mappings
cat_len = sum(map(len,[i for i in mappings])) #类别特征的个数
#cat_len = sum(map(len, mappings))
#print map(len,mappings)
num_len = len(records.first()[11:15]) #数值特征的个数
total_len = num_len+cat_len #所有特征的个数
print '类别特征的个数: %d'% cat_len
print '数值特征的个数: %d'% num_len
print '所有特征的个数::%d' % total_len
输出结果:
类别特征的编码字典: [{u'1': 0, u'3': 1, u'2': 2, u'4': 3}, {u'1': 0, u'0': 1}, {u'11': 0, u'10': 1, u'12': 2, u'1': 3, u'3': 4, u'2': 5, u'5': 6, u'4': 7, u'7': 8, u'6': 9, u'9': 10, u'8': 11}, {u'20': 0, u'21': 1, u'22': 2, u'23': 3, u'1': 4, u'0': 5, u'3': 6, u'2': 7, u'5': 8, u'4': 9, u'7': 10, u'6': 11, u'9': 12, u'8': 13, u'11': 14, u'10': 15, u'13': 16, u'12': 17, u'15': 18, u'14': 19, u'17': 20, u'16': 21, u'19': 22, u'18': 23}, {u'1': 0, u'0': 1}, {u'1': 0, u'0': 1, u'3': 2, u'2': 3, u'5': 4, u'4': 5, u'6': 6}, {u'1': 0, u'0': 1}, {u'1': 0, u'3': 1, u'2': 2, u'4': 3}]
类别特征的个数: 57
数值特征的个数: 4
所有特征的个数::61
1.1 为线性模型创建特征向量
接下来用上面的映射函数将所有类型特征转换为二元编码的特征。为了方便对每条记录提取特征和标签,我们分别定义两个辅助函数extract_features和extract_label。如下为代码实现,注意需要引入numpy和MLlib的LabeledPoint对特征向量和目标变量进行封装:
from pyspark.mllib.regression import LabeledPoint
import numpy as np
def extract_features(record):
cat_vec = np.zeros(cat_len)
step = 0
for i,raw_feature in enumerate(record[2:9]):
dict_code = mappings[i]
index = dict_code[raw_feature]
cat_vec[index+step] = 1
step = step+len(dict_code)
num_vec = np.array([float(raw_feature) for raw_feature in record[10:14]])
return np.concatenate((cat_vec, num_vec))
def extract_label(record):
return float(record[-1])
在extract_features函数中,我们遍历了数据的每一行每一列,根据已经创建的映射对每个特征进行二元编码。其中step变量用来确保非0特征在整个特征向量中位于正确的位置(另外一种实现方法是将若干较短的二元向量拼接在一起)。数值向量直接对之前已经被转换成浮点数的数据用numpy的array进行封装。最后将二元向量和数值向量拼接起来。定义extract_label函数将数据中的最后一列cnt的数据转换成浮点数。
下面对数据进行特征提取:
data = records.map(lambda point: LabeledPoint(extract_label(point),extract_features(point)))
first_point = data.first()
print '原始特征向量:' +str(first[2:])
print '标签:' + str(first_point.label)
print '对类别特征进行独热编码之后的特征向量: \n' + str(first_point.features)
print '对类别特征进行独热编码之后的特征向量长度:' + str(len(first_point.features))
输出结果:
原始特征向量:[u'1', u'0', u'1', u'0', u'0', u'6', u'0', u'1', u'0.24', u'0.2879', u'0.81', u'0', u'3', u'13', u'16']
标签:16.0
对类别特征进行独热编码之后的特征向量:
[1.0,0.0,0.0,0.0,0.0,1.0,0.0,0.0,0.0,1.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0,0.0,1.0,0.0,0.0,0.0,0.0,0.24,0.2879,0.81,0.0]
对类别特征进行独热编码之后的特征向量长度:61
1.2 为决策树创建特征向量
我们已经知道,决策树模型可以直接使用原始数据(不需要将类型数据用二元向量表示)。因此,只需要创建一个分割函数简单地将所有数值转换为浮点数,最后用numpy的array封装:
def extract_features_dt(record):
return np.array(map(float, record[2:14]))
data_dt = records.map(lambda point: LabeledPoint(extract_label(point), extract_features_dt(point)))
first_point_dt = data_dt.first()
print '决策树特征向量: '+str(first_point_dt.features)
print '决策树特征向量长度: '+str(len(first_point_dt.features))
输出结果:
决策树特征向量: [1.0,0.0,1.0,0.0,0.0,6.0,0.0,1.0,0.24,0.2879,0.81,0.0]
决策树特征向量长度: 12
2 回归模型的训练和应用
使用决策树和线性模型训练回归模型的步骤和使用分类模型相同,都是简单将训练数据封装在LabeledPoint的RDD中,并送到相关的train方法上进行训练。注意在Scala中,如果要自定义不同的模型参数(比如SGD优化的正则化和步长),就需要初始化一个新的模型实例,使用实例的optimizer变量访问和设置参数。
Python提供了方便我们访问所有模型参数的方法,因此只要使用相关方法即可。可以通过引入相关模块,并调用train方法中的help函数查看这些方法的具体细节:
from pyspark.mllib.regression import LinearRegressionWithSGD
from pyspark.mllib.tree import DecisionTree
help(LinearRegressionWithSGD.train)
输出结果:
Help on method train in module pyspark.mllib.regression:
train(cls, data, iterations=100, step=1.0, miniBatchFraction=1.0, initialWeights=None, regParam=0.0, regType=None, intercept=False, validateData=True, convergenceTol=0.001) method of __builtin__.type instance
Train a linear regression model using Stochastic Gradient
Descent (SGD).
This solves the least squares regression formulation
f(weights) = 1/(2n) ||A weights - y||^2,
which is the mean squared error.
Here the data matrix has n rows, and the input RDD holds the
set of rows of A, each with its corresponding right hand side
label y. See also the documentation for the precise formulation.
:param data: The training data, an RDD of
LabeledPoint.
:param iterations: The number of iterations
(default: 100).
:param step: The step parameter used in SGD
(default: 1.0).
:param miniBatchFraction: Fraction of data to be used for each
SGD iteration (default: 1.0).
:param initialWeights: The initial weights (default: None).
:param regParam: The regularizer parameter
(default: 0.0).
:param regType: The type of regularizer used for
training our model.
:Allowed values:
- "l1" for using L1 regularization (lasso),
- "l2" for using L2 regularization (ridge),
- None for no regularization
(default: None)
:param intercept: Boolean parameter which indicates the
use or not of the augmented representation
for training data (i.e. whether bias
features are activated or not,
default: False).
:param validateData: Boolean parameter which indicates if
the algorithm should validate data
before training. (default: True)
:param convergenceTol: A condition which decides iteration termination.
(default: 0.001)
.. versionadded:: 0.9.0
调用决策树模型的trainRegressor方法查看帮助信息
help(DecisionTree.trainRegressor)
输出结果:
Help on method trainRegressor in module pyspark.mllib.tree:
trainRegressor(cls, data, categoricalFeaturesInfo, impurity='variance', maxDepth=5, maxBins=32, minInstancesPerNode=1, minInfoGain=0.0) method of __builtin__.type instance
Train a DecisionTreeModel for regression.
:param data: Training data: RDD of LabeledPoint.
Labels are real numbers.
:param categoricalFeaturesInfo: Map from categorical feature
index to number of categories.
Any feature not in this map is treated as continuous.
:param impurity: Supported values: "variance"
:param maxDepth: Max depth of tree.
E.g., depth 0 means 1 leaf node.
Depth 1 means 1 internal node + 2 leaf nodes.
:param maxBins: Number of bins used for finding splits at each
node.
:param minInstancesPerNode: Min number of instances required at
child nodes to create the parent split
:param minInfoGain: Min info gain required to create a split
:return: DecisionTreeModel
Example usage:
>>> from pyspark.mllib.regression import LabeledPoint
>>> from pyspark.mllib.tree import DecisionTree
>>> from pyspark.mllib.linalg import SparseVector
>>>
>>> sparse_data = [
... LabeledPoint(0.0, SparseVector(2, {0: 0.0})),
... LabeledPoint(1.0, SparseVector(2, {1: 1.0})),
... LabeledPoint(0.0, SparseVector(2, {0: 0.0})),
... LabeledPoint(1.0, SparseVector(2, {1: 2.0}))
... ]
>>>
>>> model = DecisionTree.trainRegressor(sc.parallelize(sparse_data), {})
>>> model.predict(SparseVector(2, {1: 1.0}))
1.0
>>> model.predict(SparseVector(2, {1: 0.0}))
0.0
>>> rdd = sc.parallelize([[0.0, 1.0], [0.0, 0.0]])
>>> model.predict(rdd).collect()
[1.0, 0.0]
.. versionadded:: 1.1.0
在bike sharing 数据上训练回归模型
我们已经从bike sharing数据中提取了用于训练模型的特征,下面进行具体的训练。首先训练线性模型并测试该模型在训练数据上的预测效果:
linear_model = LinearRegressionWithSGD.train(data, iterations=10, step=0.1, intercept =False)
true_vs_predicted = data.map(lambda point:(point.label,linear_model.predict(point.features)))
print '线性回归模型对前5个样本的预测值: '+ str(true_vs_predicted.take(5))
输出结果:
线性回归模型对前5个样本的预测值: [(16.0, 117.89250386724844), (40.0, 116.22496123192109), (32.0, 116.02369145779232), (13.0, 115.67088016754431), (1.0, 115.56315650834314)]
上述代码中我们没有使用默认的迭代次数和步长,而是使用较小的迭代次数以缩短训练时间,关于步长的设置我们稍后会详细介绍。
接下来,我们在trainRegressor中使用默认参数来训练决策树模型(相当于深度为5的树)。注意,这里训练数据集是从原始特征中提取的,名为data_dt(不同于之前线性模型中使用的二元编码的特征)。另外,我们还需要为categoricalFeaturesInfo传入一个字典参数,这个字典参数将类型特征的索引映射到特征中类型的数目。如果某个特征值不在这个字典中,则将其映射设置为空:
dt_model = DecisionTree.trainRegressor(data_dt,{})
preds = dt_model.predict(data_dt.map(lambda p: p.features))
actual = data.map(lambda p:p.label)
true_vs_predicted_dt = actual.zip(preds)
print '决策树回归模型对前5个样本的预测值: '+str(true_vs_predicted_dt.take(5))
print '决策树模型的深度: ' + str(dt_model.depth())
print '决策树模型的叶子节点个数: '+str(dt_model.numNodes())
输出结果:
决策树回归模型对前5个样本的预测值: [(16.0, 54.913223140495866), (40.0, 54.913223140495866), (32.0, 53.171052631578945), (13.0, 14.284023668639053), (1.0, 14.284023668639053)]
决策树模型的深度: 5
决策树模型的叶子节点个数: 63
3 评估回归模型的性能
上一篇博文评估分类模型仅仅关注预测输出的类别和实际类别。特别是对于所有预测的二元结果,某个样本预测的正确与否并不重要,我们更关心预测结果中正确或者错误的总数。对回归模型而言,因为目标变量是任一实数,所以我们的模型不大可能精确预测到目标变量。然而,我们可以计算预测值和实际值的误差,并用某种度量方式进行评估。
一些用于评估回归模型的方法包括:均方误差(MSE,Mean Squared Error)、均方根误差(RMSE,Root Mean Squared Error)、平均绝对误差(MAE,Mean Absolute Error)、R-平方系数(R-squared coefficient)等。
3.1 均方误差和均方根误差
MSE是平方误差的均值,用作最小二乘回归的损失函数,公式如下:
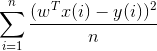
这个公式计算的是所有样本预测值和实际值平方差之和,最后除以样本总数。而RMSE是MSE的平方根。MSE的公式类似平方损失函数,会进一步放大误差。
为了计算模型预测的平均误差,我们首先预测RDD实例LabeledPoint中每个特征向量,然后计算预测值与实际值的误差并组成一个Double数组的RDD,最后使用mean方法计算所有Double值的平均值。计算平方误差函数实现如下:
def squared_error(actual, pred):
return (pred-actual)**2
3.2 平均绝对误差
MAE是预测值和实际值的差的绝对值的平均值。公式如下:
MAE和MSE大体类似,区别在于MAE对大的误差没有惩罚。计算MAE的代码如下:
def abs_error(actual, pred):
return np.abs(pred-actual)
3.3 均方根对数误差
这个度量方法虽然没有MSE和MAE使用得广,但被用于Kaggle中以bike sharing作为数据集的比赛。RMSLE可以认为是对预测值和目标值进行对数变换后的RMSE。这个度量方法适用于目标变量值域很大,并且没有必要对预测值和目标值的误差进行惩罚的情况。另外,它也适用于计算误差的百分率而不是误差的绝对值。计算RMSLE的代码如下:
def squared_log_error(pred, actual):
return (np.log(pred+1)-np.log(actual+1))**2
3.4 R-平方系数
R-平方系数,也称判定系数,用来评估模型拟合数据的好坏,常用于统计学中。R-平方系数具体测量目标变量的变异度(degree of variation),最终结果为0到1的一个值,1表示模型能够完美拟合数据。
3.5 计算不同度量下的性能
根据上面定义的函数,我们在bike sharing数据集上计算不同度量下的性能。
3.5.1 线性模型
我们的方法对RDD的每一条记录应用相关的误差函数,其中线性模型的误差函数为true_vs_predicted,相关代码实现如下:
mse = true_vs_predicted.map(lambda (t, p): squared_error(t, p)).mean()
mae = true_vs_predicted.map(lambda (t, p): abs_error(t, p)).mean()
rmsle = np.sqrt(true_vs_predicted.map(lambda (t, p): squared_log_error(t, p)).mean())
print 'Linear Model - Mean Squared Error: %2.4f' % mse
print 'Linear Model - Mean Absolute Error: %2.4f' % mae
print 'Linear Model - Root Mean Squared Log Error: %2.4f' % rmsle
输出结果:
Linear Model - Mean Squared Error: 30679.4539
Linear Model - Mean Absolute Error: 130.6429
Linear Model - Root Mean Squared Log Error: 1.4653
3.5.2 决策树
决策树的误差函数为true_vs_predicted_dt,相关代码如下:
mse_dt = true_vs_predicted_dt.map(lambda (t, p): squared_error(t, p)).mean()
mae_dt = true_vs_predicted_dt.map(lambda (t, p): abs_error(t, p)).mean()
rmsle_dt = np.sqrt(true_vs_predicted_dt.map(lambda (t, p): squared_log_error(t, p)).mean())
print 'Decision Tree - Mean Squared Error: %2.4f' % mse_dt
print 'Decision Tree - Mean Absolute Error: %2.4f' % mae_dt
print 'Decision Tree - Root Mean Squared Log Error: %2.4f' %rmsle_dt
输出结果:
Decision Tree - Mean Squared Error: 11560.7978
Decision Tree - Mean Absolute Error: 71.0969
Decision Tree - Root Mean Squared Log Error: 0.6259
4 改进模型性能和参数调优
在上一篇博文中,我们已经知道特征变换和选择对模型性能有巨大的影响。本文讨论另一种变换方式:对目标变量进行变换。
许多机器学习模型都会假设输入数据和目标变量的分布,比如线性模型的假设为正态分布。但是实际情况中线性回归的这种假设不成立的,比如例子中自行车被租的次数永远不可能为负。这就说明了正态分布的假设不合适。为了更好地理解目标变量的分布,最好的方法是画出目标变量的分布直方图。
%matplotlib inline
import matplotlib
from matplotlib.pyplot import hist
import numpy as np
import matplotlib.pyplot as plt
targets = records.map(lambda r: float(r[-1])).collect()
hist(targets, bins=40, color='lightblue', normed=True)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(12, 6)
plt.show()
从上图可以看出,目标变量的分布完全不符合正态分布。
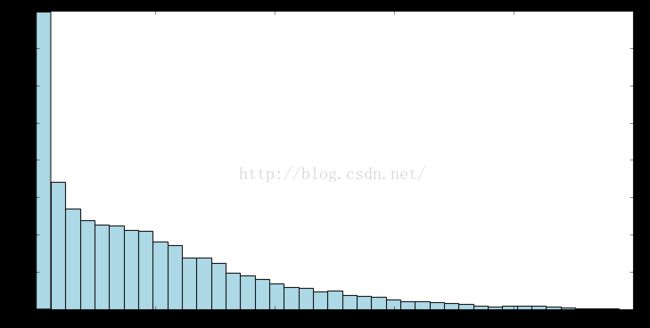
解决该问题的一种方法是对目标变量进行变换,比如用目标值的对数代替原始值,通常称为对数变换(这种变换也可以用到特征值上)。下面绘制对目标变量进行对数变换后的分布直方图。
log_targets = records.map(lambda r : np.log(float(r[-1]))).collect()
plt.hist(log_targets, bins = 40, color ='lightblue', normed =True)
fig = plt.gcf()
fig.set_size_inches(12,6)
plt.show()
输出结果:
另一种常用的变换是平方根变换。该变换适用于目标变量不为负数且值域很大的情形。下面绘制对目标变量进行平方根变换后的分布直方图。
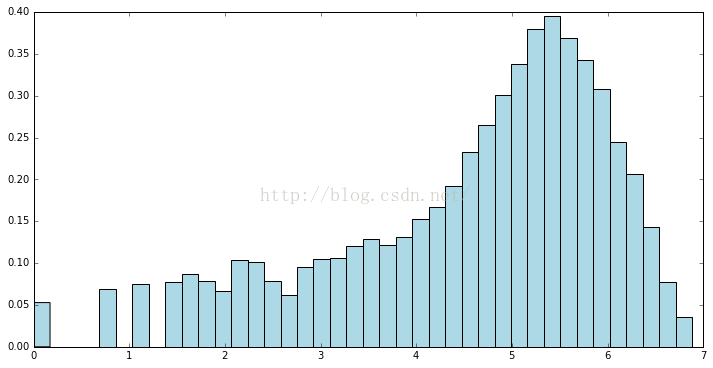
sqrt_targets = records.map(lambda r: np.sqrt(float(r[-1]))).collect()
plt.hist(sqrt_targets, bins=40, color='lightblue', normed=True)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(12, 6)
输出结果:
从对数变换和平方根变换后结果来看,变换后的数值比原始数值更均匀。虽然这两个分布也不是正态分布,但是已经比原始数据更加接近正态分布了。
4.1 目标变量变换对模型的影响
接下来测试目标变量在变换之后对模型的性能影响。
data_log = data.map(lambda lp:LabeledPoint(np.log(lp.label),lp.features))
model_log =LinearRegressionWithSGD.train(data_log, iterations=10, step=0.1)
true_vs_predicted_log = data_log.map(lambda p:(np.exp(p.label),np.exp(model_log.predict(p.features))))
#计算模型的MSE,MAE,RMSLE
mse_log = true_vs_predicted_log.map(lambda(t, p): squared_error(t,p)).mean()
mae_log = true_vs_predicted_log.map(lambda(t, p): abs_error(t, p)).mean()
rmsle_log = np.sqrt(true_vs_predicted_log.map(lambda(t, p): squared_log_error(t, p)).mean())
print'Linear Model —— Mean Squared Error:%2.4f'% mse_log
print'Linear Model —— Mean Absolue Error:%2.4f'% mae_log
print'Linear Model —— Root Mean Squared Log Error:%2.4f'% rmsle_log
print'Linear Model —— Non log-transformed predictions:\n'+ str(true_vs_predicted.take(3))
print'Linear Model —— Log-transformed predictions:\n'+ str(true_vs_predicted_log.take(3))
输出结果:
Linear Model —— Mean Squared Error:50685.5559
Linear Model —— Mean Absolue Error:155.2955
Linear Model —— Root Mean Squared Log Error:1.5411
Linear Model —— Non log-transformed predictions:
[(16.0, 117.89250386724845), (40.0, 116.2249612319211), (32.0, 116.02369145779235)]
Linear Model —— Log-transformed predictions:
[(15.999999999999998, 28.080291845456223), (40.0, 26.959480191001774), (32.0, 26.654725629458007)]
将上述结果与原始数据集训练的模型性能进行对比,可以发现,三个评价指标MSE,MAE,RMSLE都没有得到提升,书上说RMSLE的性能得到了提升,也许是spark版本所设置的默认参数不一样导致的。
下面对决策树模型做同样的分析,其代码如下:
data_dt_log = data_dt.map(lambda lp:LabeledPoint(np.log(lp.label), lp.features))
dt_model_log = DecisionTree.trainRegressor(data_dt_log,{})
preds_log = dt_model_log.predict(data_dt_log.map(lambda p:p.features))
actual_log = data_dt_log.map(lambda p: p.label)
true_vs_predicted_dt_log = actual_log.zip(preds_log).map(lambda(t,p):(np.exp(t), np.exp(p)))
#计算模型的MSE,MAE,RMSLE
mse_log_dt = true_vs_predicted_dt_log.map(lambda(t, p): squared_error(t, p)).mean()
mae_log_dt = true_vs_predicted_dt_log.map(lambda(t, p): abs_error(t,p)).mean()
rmsle_log_dt = np.sqrt(true_vs_predicted_dt_log.map(lambda(t, p):
squared_log_error(t, p)).mean())
print'Decision Tree —— Mean Squared Error:%2.4f'% mse_log_dt
print'Decision Tree —— Mean Absolue Error:%2.4f'% mae_log_dt
print'Decision Tree —— Root Mean Squared Log Error:%2.4f'% rmsle_log_dt
print'Decision Tree —— Non log-transformed predictions:\n'+ str(true_vs_predicted_dt.take(3))
print'Decision Tree —— Log-transformed predictions:\n'+str(true_vs_predicted_dt_log.take(3))
输出结果:
Decision Tree —— Mean Squared Error:14781.5760
Decision Tree —— Mean Absolue Error:76.4131
Decision Tree —— Root Mean Squared Log Error:0.6406
Decision Tree —— Non log-transformed predictions:
[(16.0, 54.913223140495866), (40.0, 54.913223140495866), (32.0, 53.171052631578945)]
Decision Tree —— Log-transformed predictions:
[(15.999999999999998, 37.530779787154508), (40.0, 37.530779787154508), (32.0, 7.2797070993907287)]
4.2 模型参数调优
到目前为止,本文讨论了同一个数据集上对MLlib中的回归模型进行训练和评估的基本概率。接下来,我们使用交叉验证方法来评估不同参数对模型性能的影响。
首先,我们将原始数据按比率划分为train,test数据集,原书当中pyspark版本还没有randomSplit这个函数,所以用如下的方式处理:
data_with_idx = data.zipWithIndex().map(lambda(k,v):(v,k))
test = data_with_idx.sample(False,0.2,42)
train = data_with_idx.subtractByKey(test)
但是我使用的版本pyspark1.6.1已经有了函数randomSplit,这里直接使用randomSplit:
train_test_data_split = data.randomSplit([0.8,0.2],123)
train = train_test_data_split[0]
test = train_test_data_split[1]
print '测试集的样本数:',test.count()
print '训练集的样本数:',train.count()
输出结果:
测试集的样本数: 3524
训练集的样本数: 13855
同理,dt的数据也做相同的处理
train_test_data_dt_split = data_dt.randomSplit([0.8,0.2],123)
train_dt = train_test_data_dt_split[0]
test_dt = train_test_data_dt_split[1]
参数设置对线性模型的影响
前面已经得到了训练集和测试集,下面研究不同参数设置对模型性能的影响,首先需要为线性模型设置一个评估方法,同时创建一个辅助函数,实现在不同参数设置下评估训练集和测试集上的性能。
本文依然使用Kaggle竞赛中的RMSLE作为评价指标。这样可以和在竞赛排行榜的成绩进行比较。
评估函数定义如下:
def evaluate(train, test, iterations, step, regParam, regType, intercept):
model =LinearRegressionWithSGD.train(train, iterations, step, regParam=regParam,
regType=regType,intercept=intercept)
testLabel_vs_testPrediction = test.map(lambda point:(point.label, model.predict(point.features)))
rmsle = np.sqrt(testLabel_vs_testPrediction.map(lambda(t,p):squared_log_error(t,p)).mean())
return rmsle
迭代次数对模型的影响:
params = [1, 5, 10, 20, 50, 100]
metrics = [evaluate(train, test, param, 0.01, 0.0, 'l2', False) for param in params]
print params
print metrics
输出结果:
[1, 5, 10, 20, 50, 100]
[2.9352350771042066, 2.0758830668686867, 1.7989931147537059, 1.5883231443924686, 1.4176140084119577, 1.3657070067736425]
绘制迭代次数与RMSLE的关系图:
plt.plot(params, metrics)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(12, 6)
plt.xscale('log')
plt.show()
输出结果:
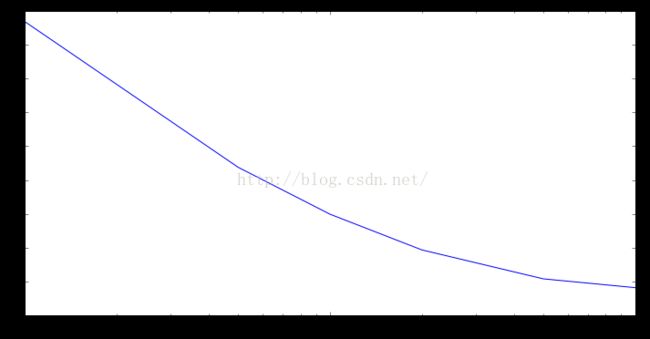
评估step对模型的影响:
params=[0.01,0.025,0.05,0.1,0.5,1.0]
metrics =[evaluate(train, test,10,param,0.0,'l2',False)for param in params]
for i in range(len(params)):
print'the rmsle:%f when step :%f'%(metrics[i],params[i])
#绘制步长与RMSLE的关系图:
plt.plot(params, metrics)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(12, 6)
plt.xscale('log')
plt.xlabel('step')
plt.ylabel('RMSLE')
plt.show()
输出结果:
the rmsle:1.798993 when step :0.010000
the rmsle:1.417115 when step :0.025000
the rmsle:1.365007 when step :0.050000
the rmsle:1.430426 when step :0.100000
the rmsle:1.397443 when step :0.500000
the rmsle:nan when step :1.000000

从上述结果可以看出为什么不使用默认步长(默认1.0)来训练线性模型,因为其得到的RMSLE结果为nan。这说明SGD模型收敛到了最差的局部最优解。这种情况在步长较大的时候容易出现,原因是算法收敛太快导致不能得到最优解。另外,小的步长与相对较小的迭代次数(比如上面的10次)对应的训练模型性能一般较差,而较小的步长与较大的迭代次数通常可以收敛到较好的结果。
不同正则化系数对模型的影响
我们知道随着正则化的提高,训练集的预测性能会下降,因为模型不能很好的拟合数据。但是我们希望设置合适的正则化参数,能够在测试集上达到最好的性能,最终得到一个泛化能力最优的模型。
先看L2正则化系数对模型的影响
params=[0.0,0.01,0.1,1.0,5.0,10.0,20.0]
metrics =[evaluate(train, test,10,0.1, param,'l2',False) for param in params]
for i in range(len(params)):
print'the rmsle:%f when regParam :%f'%(metrics[i],params[i])
#绘制L2正则化系数与RMSLE的关系图:
plt.plot(params, metrics)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(12, 8)
plt.xscale('log')
plt.xlabel('regParam')
plt.ylabel('RMSLE')
plt.show()
输出结果:
the rmsle:1.430426 when regParam :0.000000
the rmsle:1.429840 when regParam :0.010000
the rmsle:1.424681 when regParam :0.100000
the rmsle:1.383985 when regParam :1.000000
the rmsle:1.382139 when regParam :5.000000
the rmsle:1.537901 when regParam :10.000000
the rmsle:1.854222 when regParam :20.000000

再看L1正则化系数对模型的影响
params=[0.0,0.01,0.1,1.0,10.0,100.0,1000.0]
metrics =[evaluate(train, test,10,0.1, param,'l1',False) for param in params]
for i in range(len(params)):
print'the rmsle:%f when regParam :%f'%(metrics[i],params[i])
#绘制L2正则化系数与RMSLE的关系图:
plt.plot(params, metrics)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(12, 8)
plt.xscale('log')
plt.xlabel('regParam')
plt.ylabel('RMSLE')
plt.show()
输出结果:
the rmsle:1.430426 when regParam :0.000000
the rmsle:1.430394 when regParam :0.010000
the rmsle:1.430109 when regParam :0.100000
the rmsle:1.427487 when regParam :1.000000
the rmsle:1.403976 when regParam :10.000000
the rmsle:1.773484 when regParam :100.000000
the rmsle:4.818171 when regParam :1000.000000
从上图可以看到,当使用一个较大的正则化参数时,RMSLE性能急剧下降。
想必大家都知道,使用L1正则化可以得到稀疏的权重向量,我们看看刚刚得到的L1正则化模型是否真是如此呢?
model_l1 = LinearRegressionWithSGD.train(train,10,0.1,regParam=1.0, regType='l1', intercept=False)
model_l2 = LinearRegressionWithSGD.train(train,10,0.1,regParam=1.0, regType='l2', intercept=False)
model_l1_10 = LinearRegressionWithSGD.train(train,10,0.1,regParam=10.0, regType='l1', intercept=False)
model_l2_10 = LinearRegressionWithSGD.train(train,10,0.1,regParam=10.0, regType='l2', intercept=False)
model_l1_100 = LinearRegressionWithSGD.train(train,10,0.1,regParam=100.0, regType='l1', intercept=False)
model_l2_100 = LinearRegressionWithSGD.train(train,10,0.1,regParam=100.0, regType='l2', intercept=False)
print'L1 (1.0) number of zero weights:'+ str(sum(model_l1.weights.array == 0))
print'L2 (1.0) number of zero weights:'+ str(sum(model_l2.weights.array == 0))
print'L1 (10.0) number of zeros weights:'+ str(sum(model_l1_10.weights.array == 0))
print'L2 (10.0) number of zeros weights:'+ str(sum(model_l2_10.weights.array == 0))
print'L1 (100.0) number of zeros weights:'+ str(sum(model_l1_100.weights.array == 0))
print'L2 (100.0) number of zeros weights:'+ str(sum(model_l2_100.weights.array == 0))
输出结果:
L1 (1.0) number of zero weights:4
L2 (1.0) number of zero weights:4
L1 (10.0) number of zeros weights:33
L2 (10.0) number of zeros weights:4
L1 (100.0) number of zeros weights:58
L2 (100.0) number of zeros weights:4
从上面的结果可以看到,与我们预料的基本一致。随着L1正则化参数越来越大,模型的权重向量中0的个数越来越多。
截距对模型的影响
params=[False, True]
metrics =[evaluate(train, test, 10, 0.1, 1.0,'l2', param) for param in params]
for i in range(len(params)):
print'the rmsle:%f when intercept:%f'%(metrics[i],params[i])
#绘制L2正则化系数与RMSLE的关系图:
plt.bar(params, metrics, color='r')
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(12, 8)
plt.xlabel('intercept')
plt.ylabel('RMSLE')
plt.show()
输出结果:
the rmsle:1.383985 when intercept:0.000000
the rmsle:1.412280 when intercept:1.000000

同理,我们来对决策树来做一个相同的探讨:
def evaluate_dt(train, test, maxDepth, maxBins):
model =DecisionTree.trainRegressor(train,{},impurity='variance', maxDepth=maxDepth, maxBins=maxBins)
predictions = model.predict(test.map(lambda point: point.features))
actual = test.map(lambda point: point.label)
actual_vs_predictions = actual.zip(predictions)
rmsle = np.sqrt(actual_vs_predictions.map(lambda(t, p): squared_log_error(t,p)).mean())
return rmsle
树的不同最大深度对性能影响:
我们通常希望用更复杂(更深)的决策树提升模型的性能。而较小的树深度类似正则化形式,如线性模型的L2正则化和L1正则化,存在一个最优的树深度能在测试集上获得最优的性能。
params=[1,2,3,4,5,10,20]
metrics =[evaluate_dt(train_dt, test_dt, param,32) for param in params]
for i in range(len(params)):
print'the rmsle:%f when maxDepth :%d'%(metrics[i],params[i])
#绘制树的最大深度与RMSLE的关系图:
plt.plot(params, metrics)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(12, 8)
plt.xlabel('maxDepth')
plt.ylabel('RMSLE')
plt.show()
输出结果:
the rmsle:0.986397 when maxDepth :1
the rmsle:0.897647 when maxDepth :2
the rmsle:0.794272 when maxDepth :3
the rmsle:0.724606 when maxDepth :4
the rmsle:0.618654 when maxDepth :5
the rmsle:0.402800 when maxDepth :10
the rmsle:0.433434 when maxDepth :20
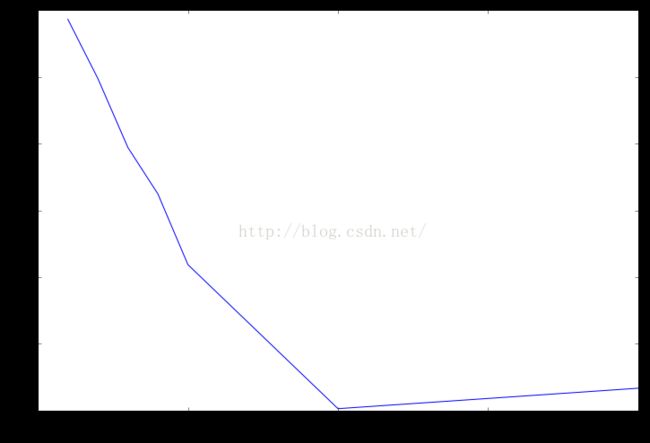
最大划分数(每个节点分支时最大bin数)对模型的影响
最后,我们来看看划分数对决策树性能的影响。和树的深度一样,更多的划分数会使模型变得更加复杂,并且有助于提升特征维度较大的模型性能。划分数到一定程度之后,对性能的提升帮助不大。实际上, 由于过拟合的原因会导致测试集的性能变差。
params=[2,4,8,16,32,64,100]
metrics =[evaluate_dt(train_dt, test_dt,5, param) for param in params]
for i in range(len(params)):
print'the rmsle:%f when maxBins :%d'%(metrics[i],params[i])
#绘制树的最大划分数与RMSLE的关系图:
plt.plot(params, metrics)
fig = matplotlib.pyplot.gcf()
fig.set_size_inches(12, 8)
plt.xlabel('maxDepth')
plt.ylabel('RMSLE')
plt.show()
输出结果:
the rmsle:1.236055 when maxBins :2
the rmsle:0.796798 when maxBins :4
the rmsle:0.740663 when maxBins :8
the rmsle:0.716042 when maxBins :16
the rmsle:0.618654 when maxBins :32
the rmsle:0.618750 when maxBins :64
the rmsle:0.618750 when maxBins :100
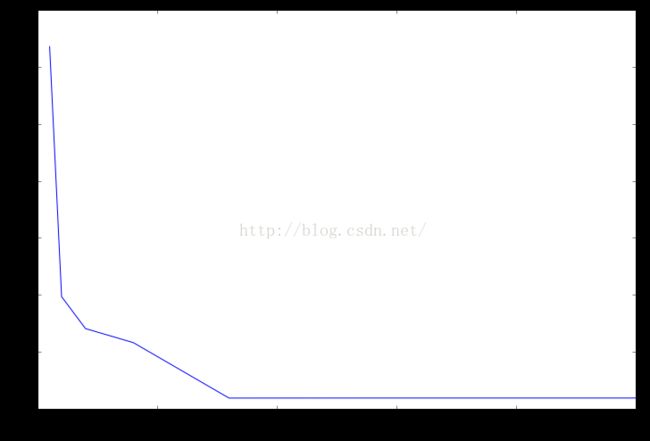
从上述结果可以看出,最大划分数会影响模型的性能,但是当最大划分数达到30之后,模型性能基本上没有获得提升。最优的最大划分数是在30到35之间。
5 小结
本文讨论了使用MLlib中的线性模型和决策树模型进行回归分析。我们研究了回归问题中类型特征的抽取和对目标变量做变换的影响。最后,我们实现了不同的性能评估指标,并且设计了交叉验证实验,研究线性模型和决策树模型的不同参数对测试集性能的影响。
下一篇博文,将讨论机器学习中的新方法:无监督学中的聚类模型。