Java笔试面试题整理第七波
1、super的作用
public class A {
String name = "lly";
protected void getName(){
System.out.println("父类getName->"+ name);
}
}
public class B extends A {
String nameB = "llyB";
@Override
protected void getName() {
System.out.println("子类getName->"+nameB);
super.getName();
}
public static void main(String[] args) {
B b = new B();
b.getName();
}
}
public class B extends A {
String name = "llyB";
@Override
protected void getName() {
name = super.name;
System.out.println("子类getName->"+name);
}
public static void main(String[] args) {
B b = new B();
b.getName();
}
}
2、关于构造方法
public class A {
public A(String s){ }
}
public class B extends A { //编译错误,JVM默认给B加了一个无参构造方法,而在这个方法中默认调用了super(),但是父类中并不存在该构造方法
String name = "llyB";
}
public class B extends A { //同样编译错误,相同的道理,虽然我们在子类中自己定义了一个构造方法,但是在这个构造方法中还是默认调用了super(),但是父类中并不存在该构造方法
String name = "llyB";
public B(String s){}
}
public class B extends A { //正确编译
String name = "llyB";
public B(String s){
super(s);
}
}
3、transient关键字用法
public class UserBean implements Serializable{
private static final long serialVersionUID = 856780694939330811L;
private String userName;
private transient String password; //此字段不需要被序列化
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
public class Test {
public static void main(String[] args) {
UserBean bean = new UserBean();
bean.setUserName("lly");
bean.setPassword("123");
System.out.println("序列化前--->userName:"+bean.getUserName()+",password:"+bean.getPassword());
//下面序列化到本地
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream("e:/userbean.txt"));
oos.writeObject(bean);//将对象序列化缓存到本地
oos.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
if(oos != null){
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//下面从本地反序列化缓存出来
try {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("e:/userbean.txt"));
bean = (UserBean) ois.readObject();
ois.close();
System.out.println("反序列化后获取出的数据--->userName:"+bean.getUserName()+",password:"+bean.getPassword());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
4、下面哪些类可以被继承
5、for和foreach遍历的比较
List<Integer> list = new ArrayList<Integer>();
Integer[] list = new Integer[10000000];
for(int i = 0; i < 10000000; i++){//先生成1000万随机数
list[i] = Math.round(100000);//随机数只是咋100000以内
}
long size = list.length;
long start = System.currentTimeMillis();
int a;
for(int i = 0; i < size; i++){
a =list[i];
}
long end = System.currentTimeMillis();
System.out.println("耗时--->"+(end-start));
经过多次运行,发现平均耗时7ms左右。将上面的for循环改成foreach形式,如下:
for(Integer i : list){
a = i;
}
List<Integer> list = new ArrayList<Integer>();
for(int i = 0; i < 10000000; i++){
list.add(Math.round(100000));
}
long size = list.size();
long start = System.currentTimeMillis();
int a;
for(int i = 0; i < size; i++){
a =list.get(i);
}
long end = System.currentTimeMillis();
System.out.println("耗时--->"+(end-start));
多次运行后,平均运行时间为21ms左右,将上面的for循环改成foreach形式,如下:
for(Integer i : list){
a = i;
}
6、Java IO与NIO
阻塞:当某个事件或者任务在执行过程中,它发出一个请求操作,但是由于该请求操作需要的条件不满足,那么就会一直在那等待,直至条件满足;
非阻塞:当某个事件或者任务在执行过程中,它发出一个请求操作,如果该请求操作需要的条件不满足,会立即返回一个标志信息告知条件不满足,不会一直在那等待。
这就是阻塞和非阻塞的区别。也就是说阻塞和非阻塞的区别关键在于当发出请求一个操作时,如果条件不满足,是会一直等待还是返回一个标志信息。
阻塞IO和非阻塞IO:
当用户线程发起一个IO请求操作(本文以读请求操作为例),内核会去查看要读取的数据是否就绪,对于阻塞IO来说,如果数据没有就绪,则会一直在那等待,直到数据就绪;
对于非阻塞IO来说,如果数据没有就绪,则会返回一个标志信息告知用户线程当前要读的数据没有就绪。当数据就绪之后,便将数据拷贝到用户线程,这样才完成了一个完整的IO读请求操作。
也就是说一个完整的IO读请求操作包括两个阶段:
1)查看数据是否就绪;
2)进行数据拷贝(内核将数据拷贝到用户线程)。
那么阻塞(blocking IO)和非阻塞(non-blocking IO)的区别就在于第一个阶段,如果数据没有就绪,在查看数据是否就绪的过程中是一直等待,还是直接返回一个标志信息。
Java中传统的IO都是阻塞IO,比如通过socket来读数据,调用read()方法之后,如果数据没有就绪,当前线程就会一直阻塞在read方法调用那里,直到有数据才返回;而如果是非阻塞IO的话,当数据没有就绪,read()方法应该返回一个标志信息,告知当前线程数据没有就绪,而不是一直在那里等待。
同步IO和异步IO:从字面的意思可以看出:同步IO即 如果一个线程请求进行IO操作,在IO操作完成之前,该线程会被阻塞;
而异步IO为 如果一个线程请求进行IO操作,IO操作不会导致请求线程被阻塞。
事实上,同步IO和异步IO模型是针对用户线程和内核的交互来说的:
对于同步IO:当用户发出IO请求操作之后,如果数据没有就绪,需要通过用户线程或者内核不断地去轮询数据是否就绪,当数据就绪时,再将数据从内核拷贝到用户线程;
而异步IO:只有IO请求操作的发出是由用户线程来进行的,IO操作的两个阶段都是由内核自动完成,然后发送通知告知用户线程IO操作已经完成。也就是说在异步IO中,不会对用户线程产生任何阻塞。
这是同步IO和异步IO关键区别所在,同步IO和异步IO的关键区别反映在数据拷贝阶段是由用户线程完成还是内核完成。所以说异步IO必须要有操作系统的底层支持。(即同步IO是用户线程不断的轮询、有数据之后进行拷贝,而异步IO是内核完成这两个步骤,与用户线程无关。)
阻塞IO和非阻塞IO是反映在当用户请求IO操作时,如果数据没有就绪,是用户线程一直等待数据就绪,还是会收到一个标志信息这一点上面的。也就是说,阻塞IO和非阻塞IO是反映在IO操作的第一个阶段,在查看数据是否就绪时是如何处理的。
注意同步IO和异步IO与阻塞IO和非阻塞IO是不同的两组概念,同步IO和异步IO考虑的是由哪个线程(用户线程or内核线程)来完成IO的处理,而阻塞IO和非阻塞IO,针对的是IO操作中的第一个阶段的处理方式,是一直等待还是直接返回状态信息。- FileChannel --从文件读或者向文件写入数据
- SocketChanel --以TCP来向网络连接的两端读写数据
- ServerSocketChannel --服务器端通过ServerSocketChanel能够监听客户端发起的TCP连接,并为每个TCP连接创建一个新的SocketChannel来进行数据读写
- DatagramChannel --以UDP协议来向网络连接的两端读写数据

public static String readFromStream(InputStream is) throws IOException{
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = 0;
while((len = is.read(buffer))!=-1){
baos.write(buffer, 0, len);
}
is.close();
String result = baos.toString();
baos.close();
return result;
}
FileInputStream in = new FileInputStream("e:\\lly.txt");
FileChannel fileChannel = in.getChannel();
//创建一个ByteBuffer缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
//从通道读入数据到缓冲区
fileChannel.read(buffer);
//重设此缓冲区,将限制设置为当前位置,然后将当前位置设置为0
buffer.flip();
while(buffer.hasRemaining()){
byte b = buffer.get();//从缓冲区中取数据到内存中
System.out.print(((char)b));
}
in.close();
//模拟数据
byte[] data = { 83, 111, 109, 101, 32,
98, 121, 116, 101, 115, 46};
FileOutputStream out = new FileOutputStream("e:\\lly.txt");
FileChannel fileChannel = out.getChannel();
//创建一个ByteBuffer缓冲区
ByteBuffer buffer = ByteBuffer.allocate(20);
//先将数据写入到Buffer中
for(int i = 0; i < data.length; i++){
buffer.put(data[i]);
}
//重设此缓冲区,将限制设置为当前位置,然后将当前位置设置为0
buffer.flip();
//把buffer中的数据送入到通道中
fileChannel.write(buffer);
out.close();
在第一篇中,我们介绍了NIO中的两个核心对象:缓冲区和通道,在谈到缓冲区时,我们说缓冲区对象本质上是一个数组,但它其实是一个特殊的数组,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况,如果我们使用get()方法从缓冲区获取数据或者使用put()方法把数据写入缓冲区,都会引起缓冲区状态的变化。本文为NIO使用及原理分析的第二篇,将会分析NIO中的Buffer对象。
在缓冲区中,最重要的属性有下面三个,它们一起合作完成对缓冲区内部状态的变化跟踪:
position:指定了下一个将要被写入或者读取的元素索引,它的值由get()/put()方法自动更新,在新创建一个Buffer对象时,position被初始化为0。
limit:指定还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。
capacity:指定了可以存储在缓冲区中的最大数据容量,实际上,它指定了底层数组的大小,或者至少是指定了准许我们使用的底层数组的容量。
以上四个属性值之间有一些相对大小的关系:0 <= position <= limit <= capacity。如果我们创建一个新的容量大小为10的ByteBuffer对象,在初始化的时候,position设置为0,limit和 capacity被设置为10,在以后使用ByteBuffer对象过程中,capacity的值不会再发生变化,而其它两个个将会随着使用而变化。四个属性值分别如图所示:

现在我们可以从通道中读取一些数据到缓冲区中,注意从通道读取数据,相当于往缓冲区中写入数据。如果读取4个自己的数据,则此时position的值为4,即下一个将要被写入的字节索引为4,而limit仍然是10,如下图所示:
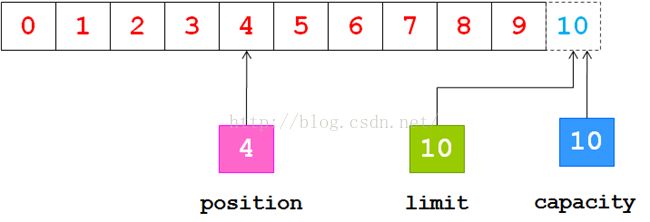
下一步把读取的数据写入到输出通道中,相当于从缓冲区中读取数据,在此之前,必须调用flip()方法,该方法将会完成两件事情:
1. 把limit设置为当前的position值
2. 把position设置为0
由于position被设置为0,所以可以保证在下一步输出时读取到的是缓冲区中的第一个字节,而limit被设置为当前的position,可以保证读取的数据正好是之前写入到缓冲区中的数据,如下图所示:
现在调用get()方法从缓冲区中读取数据写入到输出通道,这会导致position的增加而limit保持不变,但position不会超过limit的值,所以在读取我们之前写入到缓冲区中的4个自己之后,position和limit的值都为4,如下图所示:
在从缓冲区中读取数据完毕后,limit的值仍然保持在我们调用flip()方法时的值,调用clear()方法能够把所有的状态变化设置为初始化时的值,如下图所示:

- package cn.nio;
- import java.io.IOException;
- import java.net.InetSocketAddress;
- import java.nio.ByteBuffer;
- import java.nio.channels.SelectionKey;
- import java.nio.channels.Selector;
- import java.nio.channels.ServerSocketChannel;
- import java.nio.channels.SocketChannel;
- import java.util.Iterator;
- /**
- * NIO服务端
- * @author 小路
- */
- public class NIOServer {
- //通道管理器
- private Selector selector;
- /**
- * 获得一个ServerSocket通道,并对该通道做一些初始化的工作
- * @param port 绑定的端口号
- * @throws IOException
- */
- public void initServer(int port) throws IOException {
- // 获得一个ServerSocket通道
- ServerSocketChannel serverChannel = ServerSocketChannel.open();
- // 设置通道为非阻塞
- serverChannel.configureBlocking(false);
- // 将该通道对应的ServerSocket绑定到port端口
- serverChannel.socket().bind(new InetSocketAddress(port));
- // 获得一个通道管理器
- this.selector = Selector.open();
- //将通道管理器和该通道绑定,并为该通道注册SelectionKey.OP_ACCEPT事件,注册该事件后,
- //当该事件到达时,selector.select()会返回,如果该事件没到达selector.select()会一直阻塞。
- serverChannel.register(selector, SelectionKey.OP_ACCEPT);
- }
- /**
- * 采用轮询的方式监听selector上是否有需要处理的事件,如果有,则进行处理
- * @throws IOException
- */
- @SuppressWarnings("unchecked")
- public void listen() throws IOException {
- System.out.println("服务端启动成功!");
- // 轮询访问selector
- while (true) {
- //当注册的事件到达时,方法返回;否则,该方法会一直阻塞
- selector.select();
- // 获得selector中选中的项的迭代器,选中的项为注册的事件
- Iterator ite = this.selector.selectedKeys().iterator();
- while (ite.hasNext()) {
- SelectionKey key = (SelectionKey) ite.next();
- // 删除已选的key,以防重复处理
- ite.remove();
- // 客户端请求连接事件
- if (key.isAcceptable()) {
- ServerSocketChannel server = (ServerSocketChannel) key
- .channel();
- // 获得和客户端连接的通道
- SocketChannel channel = server.accept();
- // 设置成非阻塞
- channel.configureBlocking(false);
- //在这里可以给客户端发送信息哦
- channel.write(ByteBuffer.wrap(new String("向客户端发送了一条信息").getBytes()));
- //在和客户端连接成功之后,为了可以接收到客户端的信息,需要给通道设置读的权限。
- channel.register(this.selector, SelectionKey.OP_READ);
- // 获得了可读的事件
- } else if (key.isReadable()) {
- read(key);
- }
- }
- }
- }
- /**
- * 处理读取客户端发来的信息 的事件
- * @param key
- * @throws IOException
- */
- public void read(SelectionKey key) throws IOException{
- // 服务器可读取消息:得到事件发生的Socket通道
- SocketChannel channel = (SocketChannel) key.channel();
- // 创建读取的缓冲区
- ByteBuffer buffer = ByteBuffer.allocate(10);
- channel.read(buffer);
- byte[] data = buffer.array();
- String msg = new String(data).trim();
- System.out.println("服务端收到信息:"+msg);
- ByteBuffer outBuffer = ByteBuffer.wrap(msg.getBytes());
- channel.write(outBuffer);// 将消息回送给客户端
- }
- /**
- * 启动服务端测试
- * @throws IOException
- */
- public static void main(String[] args) throws IOException {
- NIOServer server = new NIOServer();
- server.initServer(8000);
- server.listen();
- }
- }
- package cn.nio;
- import java.io.IOException;
- import java.net.InetSocketAddress;
- import java.nio.ByteBuffer;
- import java.nio.channels.SelectionKey;
- import java.nio.channels.Selector;
- import java.nio.channels.SocketChannel;
- import java.util.Iterator;
- /**
- * NIO客户端
- * @author 小路
- */
- public class NIOClient {
- //通道管理器
- private Selector selector;
- /**
- * 获得一个Socket通道,并对该通道做一些初始化的工作
- * @param ip 连接的服务器的ip
- * @param port 连接的服务器的端口号
- * @throws IOException
- */
- public void initClient(String ip,int port) throws IOException {
- // 获得一个Socket通道
- SocketChannel channel = SocketChannel.open();
- // 设置通道为非阻塞
- channel.configureBlocking(false);
- // 获得一个通道管理器
- this.selector = Selector.open();
- // 客户端连接服务器,其实方法执行并没有实现连接,需要在listen()方法中调
- //用channel.finishConnect();才能完成连接
- channel.connect(new InetSocketAddress(ip,port));
- //将通道管理器和该通道绑定,并为该通道注册SelectionKey.OP_CONNECT事件。
- channel.register(selector, SelectionKey.OP_CONNECT);
- }
- /**
- * 采用轮询的方式监听selector上是否有需要处理的事件,如果有,则进行处理
- * @throws IOException
- */
- @SuppressWarnings("unchecked")
- public void listen() throws IOException {
- // 轮询访问selector
- while (true) {
- selector.select();
- // 获得selector中选中的项的迭代器
- Iterator ite = this.selector.selectedKeys().iterator();
- while (ite.hasNext()) {
- SelectionKey key = (SelectionKey) ite.next();
- // 删除已选的key,以防重复处理
- ite.remove();
- // 连接事件发生
- if (key.isConnectable()) {
- SocketChannel channel = (SocketChannel) key
- .channel();
- // 如果正在连接,则完成连接
- if(channel.isConnectionPending()){
- channel.finishConnect();
- }
- // 设置成非阻塞
- channel.configureBlocking(false);
- //在这里可以给服务端发送信息哦
- channel.write(ByteBuffer.wrap(new String("向服务端发送了一条信息").getBytes()));
- //在和服务端连接成功之后,为了可以接收到服务端的信息,需要给通道设置读的权限。
- channel.register(this.selector, SelectionKey.OP_READ);
- // 获得了可读的事件
- } else if (key.isReadable()) {
- read(key);
- }
- }
- }
- }
- /**
- * 处理读取服务端发来的信息 的事件
- * @param key
- * @throws IOException
- */
- public void read(SelectionKey key) throws IOException{
- //和服务端的read方法一样
- }
- /**
- * 启动客户端测试
- * @throws IOException
- */
- public static void main(String[] args) throws IOException {
- NIOClient client = new NIOClient();
- client.initClient("localhost",8000);
- client.listen();
- }
- }
Java NIO:NIO概述
Java NIO使用及原理分析 (一)
Java NIO使用及原理分析(二)
Java NIO系列教程(一) Java NIO 概述
Java NIO原理 图文分析及代码实现
】