K均值聚类算法(K-Means)
K均值聚类算法(K-Means)
标签: Python 机器学习
主要参考资料:
- Peter HARRINGTON.机器学习实战[M].李锐,李鹏,曲亚东,王斌译.北京:人民邮电出版社, 2013.
1.K均值算法简介
K均值聚类算法首先是聚类算法。
聚类是一种无监督的学习,将相似的对象归到同一个簇中。聚类与分类的最大不同在于分类的目标事先已知,而聚类则不知道。
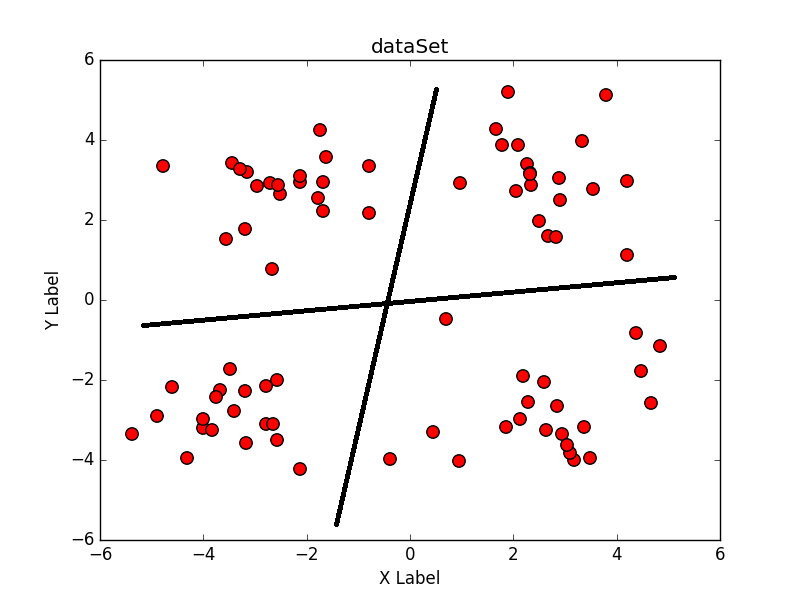
K均值聚类算法是发现给定数据集k个簇的算法。如下图所示,如果设定的聚类簇数是4,那么理想的K均值算法可以按照两条黑线将所有数据分为4类:
2.K均值算法实现
K均值算法需要输入待聚类的数据和欲聚类的簇数k,主要的聚类过程有3步:
- 随机生成k个初始点作为质心
- 将数据集中的数据按照距离质心的远近分到各个簇中
- 将各个簇中的数据求平均值,作为新的质心,重复上一步,直到所有的簇不再改变
举一个例子,现在有若干可见光需要分成2类,先随机在其波长范围内选择2个波长作为质心,然后若干个可见光根据距离质心的远近分成两个簇,随后在每个簇内分别求波长的平均值作为质心。不断的迭代上面的过程:若干可见光根据距离质心的远近分成两个簇,随后在每个簇内分别求波长的平均值作为质心,直到所有可见光的类别不再改变。如果可见光均匀,K均值聚类理想,一般情况下会将光谱中绿色左边的聚为一类,绿色右边聚为一类。
2.1载入数据
from numpy import *
def loadDataSet(fileName):
dataSet = []
f = open(fileName)
for line in f.readlines():
curLine = line.strip().split('\t')
fltLine = map(float, curLine)
dataSet.append(fltLine)
return mat(dataSet)2.2求向量距离
K均值聚类中需要计算数据和质心的距离,常见的距离有欧氏距离(Euclidean distance)和曼哈顿距离(Manhattan distance),本处采用欧式距离。
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2)))2.3随机生成k个点作为初始质心
这里需要说明的是初始质心的坐标有一个随机生成的范围,即必须在最大值和最小值之间,详见代码注释。
def randCent(dataSet, k):
n = shape(dataSet)[1] #n是列数
centroids = mat(zeros((k, n)))
for j in range(n):
minJ = min(dataSet[:, j]) #找到第j列最小值
rangeJ = float(max(dataSet[:, j]) - minJ) #求第j列最大值与最小值的差
centroids[:, j] = minJ + rangeJ * random.rand(k, 1) #生成k行1列的在(0, 1)之间的随机数矩阵
return centroids2.4K均值聚类算法实现
矩阵clusterAssment为m行2列,该矩阵和dataSet的行数相同,行行对应,第一列表示与对应行距离最近的质心下标,第二列表示欧式距离的平方。
矩阵centroids为k行2列,表示k个质心的坐标。
def KMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0] #数据集的行
clusterAssment = mat(zeros((m, 2)))
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m): #遍历数据集中的每一行数据
minDist = inf;minIndex = -1
for j in range(k): #寻找最近质心
distJI = distMeas(centroids[j, :], dataSet[i, :])
if distJI < minDist: #更新最小距离和质心下标
minDist = distJI; minIndex = j
if clusterAssment[i, 0] != minIndex:
clusterChanged = True
clusterAssment[i, :] = minIndex, minDist**2 #记录最小距离质心下标,最小距离的平方
print centroids
for cent in range(k): #更新质心位置
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]] #获得距离同一个质心最近的所有点的下标,即同一簇的坐标
centroids[cent,:] = mean(ptsInClust, axis=0) #求同一簇的坐标平均值,axis=0表示按列求均值
return centroids, clusterAssment2.5数据可视化
将所有数据使用matplotlib画出来,方便观察。
import matplotlib.pyplot as plt
def showCluster(dataSet, k, clusterAssment, centroids):
fig = plt.figure()
plt.title("K-means")
ax = fig.add_subplot(111)
data = []
for cent in range(k): #提取出每个簇的数据
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]] #获得属于cent簇的数据
data.append(ptsInClust)
for cent, c, marker in zip( range(k), ['r', 'g', 'b', 'y'], ['^', 'o', '*', 's'] ): #画出数据点散点图
ax.scatter(data[cent][:, 0], data[cent][:, 1], s=80, c=c, marker=marker)
ax.scatter(centroids[:, 0], centroids[:, 1], s=1000, c='black', marker='+', alpha=1) #画出质心点
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
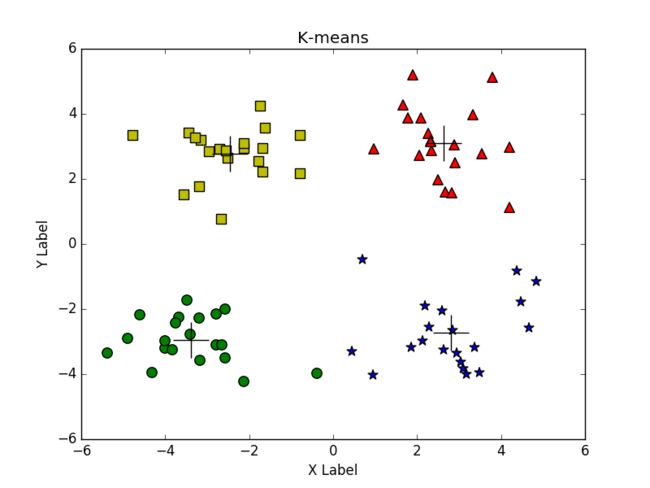
plt.show()使用K均值算法对测试数据进行聚类,一般情况下效果不错,各个簇区别明显,如图所示:
但是有时候效果就不好了,因为K均值聚类收敛的是局部最小值,而不是全局最小值,如图所示:
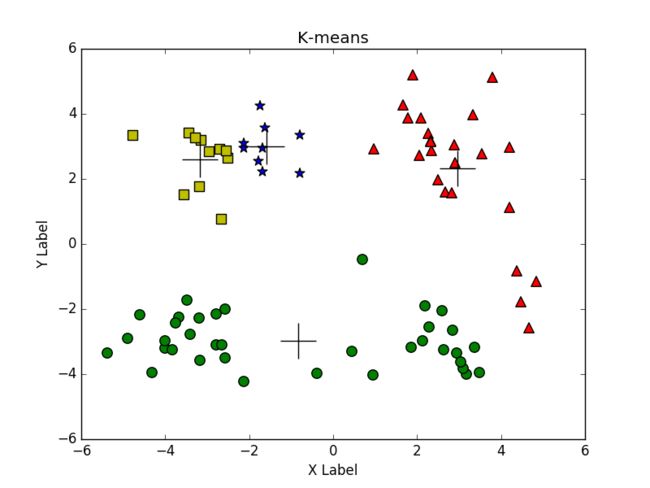
下面的两类几乎分到了一起,左上的一类又被分成了两类,如何解决这个问题呢?二分K均值算法。
3.二分K均值聚类算法
二分K均值算法是K均值算法的改进版。该算法首先将所有的点作为一个簇,然后将该簇一分为二,之后选择其中的一个簇继续划分。选择哪一个簇进行划分取决于对其划分是否可以最大程度的降低误差平方和。重复上述基于误差平方和的划分过程,直到簇数目和指定的k值相等。
def biKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0] #求所有数据的平均值,创建一个初始簇质心
centList =[centroid0]
for j in range(m): #计算初始误差平方和
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
while (len(centList) < k): #只要聚类的个数小于等于k
lowestSSE = inf
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] #获得属于cent簇的数据
centroidMat, splitClustAss = KMeans(ptsInCurrCluster, 2, distMeas) #对一个簇中的数据进行kMeans
sseSplit = sum(splitClustAss[:,1]) #计算本次划分误差平方和
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) #计算不属于cent簇的误差平方和
print "sseSplit, and notSplit: ",sseSplit,sseNotSplit
if (sseSplit + sseNotSplit) < lowestSSE: #如果有效降低了误差平方和,则记录
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #将划分簇的编号转为新加簇的编号
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit #更新原始的该簇质心编号
print 'the bestCentToSplit is: ',bestCentToSplit
print 'the len of bestClustAss is: ', len(bestClustAss)
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]#将一个质心更新为两个质心
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss #更新数据的编号以及误差平方和
return mat(centList), clusterAssment一些说明:
- 每次迭代中都要对每一个簇进行划分,在其中选择最大程度降低误差平方和簇进行聚类
- 当使用KMeans()函数且指定的聚类数目为2时,会得到编号为0和1的两个簇,将编号为0的簇编号改为输入簇的编号,编号为1的簇编号改为所有簇的数目len(centList),即在原先簇上追加一个簇
4.总结
- 聚类是一种无监督的学习方法
- K均值算法需要用户指定创建的簇数k
- K均值算法在大数据集上收敛较慢
- K均值算法有可能达到局部最小值,为了达到更好的距离效果,可以使用二分K均值聚类
- 源码在我的GitHub中,
MachineLearningAction仓库里面有常见的机器学习算法处理常见数据集的各种实例,希望能够得到你的STAR