awk学习_仅不输出某指定字段
awk学习_仅不输出某指定字段
系统中的配置数值大部分存于csv文件中,常常有需求将csv中含有某关键字的文件名和所在的行号和内容搜索出来,以便进一步加工。
比如想找出包含关键字“弟子”的相关csv,可以使用:
grep -rHni '弟子' --color=always ./csv | awk '{print $0}'
结果:
结果中每行由三部分组成:文件名、行号、行内容,用“:”隔开。
因为每行都输出了文件名,显得杂乱无章,通过修改命令可以将文件名单独提取,行号和内容作为另一行,当文件名相同时省略输出文件名:
grep -rHni '弟子' --color=always ./csv | awk -F ':' 'BEGIN{print $1;n=$1;}{if($1==n) print $2,$3; else print $1;print $2,$3;n=$1;}'
结果:
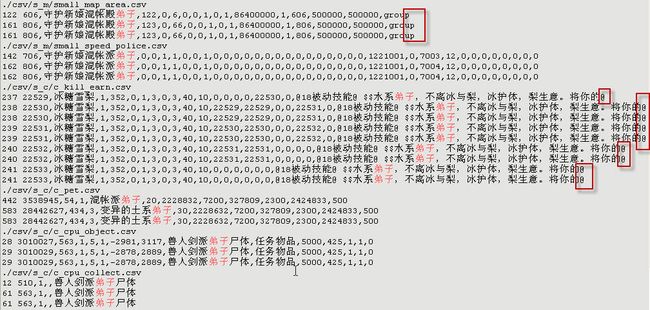
对比两次结果可知,有些csv文件中字段的内容包含”:”,导致以“:”为分隔符时并不是每一行恰好有三个字段,这些“:”导致某些csv文件的行有4个字段以上,因此当上述命令输出时并不能完整输出行内容。
我想,awk这么强大的工具应该有这样的参数:仅不输出某指定的字段。
后来错略浏览了一遍man awk,发现并没有现成的参数或命令,然后利用其内置函数index和substr尝试写一个:
第n个字段:
字段位置
$1,$2, … $n … $NF
字符位置
1 index($0,$n)…(index($0,$n)+length($n)-1) length($0)
那么仅不输出第n个字段$n的输出,可等价为:
先输出第一个字段到第n个字段的前一个字符(即第n-1个字符与第n个字段中间的分隔符),然后再输出第n+1个字段到$0的末尾。
第n个字段的前一个字符位置为index($0,$n)-1;
第n+1个字段的首字符位置为(index(src,dstf)+length(dstf)+1)。
grep -rHni '弟子' --color=always ./csv/ | awk -F ':' '
function prt_a(src,dstf)
{
printf substr(src,1,index(src,dstf)-1)
}
function prt_z(src,dstf)
{
print substr(src,(index(src,dstf)+length(dstf)+1))
}
BEGIN{print $1;n=$1;}{if($1==n) prt_z($0,$1);else print $1;prt_z($0,$1);n=$1;}'
结果:

因为我的需求是仅不输出第一字段,因此规避了一个问题:
假设我的需求是仅不输出第n(2<=n<=NF)个字段,那么当我在函数中调用index(src,dstf)时就变成了index($0,$n),那么当$0中,$n之前的字段中有字符串恰好等于$4字符串,那么我想要的index值就不再是$n字段的第一个字符的位置了。
另外,使用index时应特别注意这种情况。
换一种思路:按字段输出
grep -rHni '弟子' --color=always ./csv/ | awk -F ':' '
function prt_not(n)
{
for(i=2;i<=NF-1;i++)
{
if(i!=n)
printf $i FS
else
printf ""
}
if(n==NF)
printf "\n"
else
print $NF
}
BEGIN{print $1;m=$1;}{if($1==m) prt_not(1);else print $1;prt_not(1);m=$1;}'
结果:
纠正一下,上图输出的结果中除第一行外,其他行均输出了两遍,代码有问题,现纠正为:
grep -rHni '弟子' --color=always ./csv/ | awk -F ':' '
function prt_not(n)
{
for(i=2;i<=NF-1;i++)
{
if(i!=n)
printf $i FS
else
printf ""
}
if(n==NF)
printf "\n"
else
print $NF
}
BEGIN{print $1;m=$1;}{if($1==m) prt_not(1);else {print $1;prt_not(1);m=$1;}}'
“{”,"}"括号是本次修改代码新增的部分;
该方法可实现awk的仅不输出某指定字段的需求。