针对例会中出现的split块的位置问题的解决方案
本文作者:王婷婷
针对例会中出现的问题,本人提出的解决方案如下:
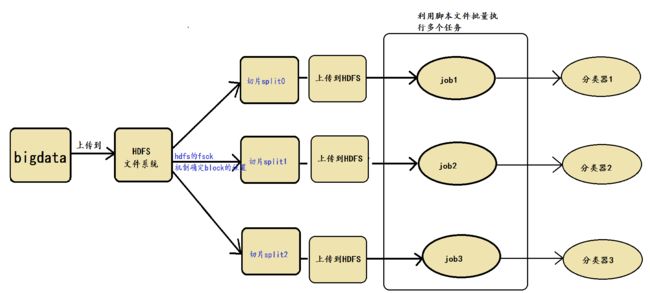
涉及到的具体技术实现细节包括hdfs fsck机制与脚本批量执行机制,先分别介绍。
1、hdfs fsck机制
在HDFS中,提供了fsck命令,用于检查HDFS上文件和目录的健康状态、获取文件的block块信息和位置信息等。
集群情况:
[root@hadoop11 local]# jps
28234 NameNode
28419 SecondaryNameNode
34256 Jps
[root@hadoop22 ~]# jps
9741 ResourceManager
38972 Jps
[root@hadoop33 finalized]# jps
24581 DataNode
12653 NodeManager
27061 Jps
[root@hadoop44 finalized]# jps
9988 NodeManager
46310 DataNode
48784 Jps
[root@hadoop55 finalized]# jps
11563 NodeManager
904 Jps
46774 DataNode
[root@hadoop66 finalized]# jps
4349 DataNode
10560 NodeManager
6833 JpsHDFS文件系统中文件存储情况:
[root@hadoop11 local]# hadoop fs -ls /
Found 1 items
-rw-r--r-- 3 root supergroup 319687975 2016-07-10 16:28 /hepmass.txt
[root@hadoop11 local]# hadoop fs -du -s -h /hepmass.txt
304.9 M /hepmass.txt上面的情况介绍完之后,将具体介绍hdfs fsck命令:
[root@hadoop11 local]# hdfs fsck
Usage: DFSck <path> [-list-corruptfileblocks | [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]]
<path> start checking from this path
-move move corrupted files to /lost+found -delete delete corrupted files -files print out files being checked -openforwrite print out files opened for write -includeSnapshots include snapshot data if the given path indicates a snapshottable directory or there are snapshottable directories under it -list-corruptfileblocks print out list of missing blocks and files they belong to -blocks print out block report -locations print out locations for every block -racks print out network topology for data-node locations具体命令介绍:
-move: 移动损坏的文件到/lost+found目录下
-delete: 删除损坏的文件
-openforwrite: 输出检测中的正在被写的文件
-list-corruptfileblocks: 输出损坏的块及其所属的文件
-files: 输出正在被检测的文件
-blocks: 输出block的详细报告 (需要和-files参数一起使用)
-locations: 输出block的位置信息 (需要和-files参数一起使用)
-racks: 输出文件块位置所在的机架信息(需要和-files参数一起使用)
例如要查看HDFS中某个文件的block块的具体分布,可以这样写:
hadoop fsck /your_file_path -files -blocks -locations -racks
示例:
[root@hadoop11 local]# hdfs fsck /hepmass.txt -files -blocks -locations
Connecting to namenode via http://hadoop11:50070
FSCK started by root (auth:SIMPLE) from /10.187.84.50 for path /hepmass.txt at Sun Jul 10 19:13:03 CST 2016
/hepmass.txt 319687975 bytes, 3 block(s): OK
0. BP-1987893578-10.187.84.50-1467446212499:blk_1073748824_8000 len=134217728 repl=3 [10.187.84.52:50010, 10.187.84.53:50010, 10.187.84.55:50010]
1. BP-1987893578-10.187.84.50-1467446212499:blk_1073748825_8001 len=134217728 repl=3 [10.187.84.53:50010, 10.187.84.55:50010, 10.187.84.52:50010]
2. BP-1987893578-10.187.84.50-1467446212499:blk_1073748826_8002 len=51252519 repl=3 [10.187.84.54:50010, 10.187.84.52:50010, 10.187.84.53:50010]
其中前面的0. 1. 2.代表该文件的block索引顺序;
BP-1987893578-10.187.84.50-1467446212499:blk_1073748824_8000表示block id;
len=134217728(128M)表示该文件块大小;
repl=3 表示该block块的副本数;
Status: HEALTHY
Total size: 319687975 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 3 (avg. block size 106562658 B)
Minimally replicated blocks: 3 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 4
Number of racks: 1
FSCK ended at Sun Jul 10 19:13:03 CST 2016 in 0 milliseconds
The filesystem under path '/hepmass.txt' is HEALTHY我们随后在各个NodeManager节点上进行数据核对:
[root@hadoop33 finalized]# pwd
/usr/local/hadoop/tmp/dfs/data/current/BP-1987893578-10.187.84.50-1467446212499/current/finalized
[root@hadoop33 finalized]# du -sh *
128M blk_1073748824
1.1M blk_1073748824_8000.meta
128M blk_1073748825
1.1M blk_1073748825_8001.meta
49M blk_1073748826
392K blk_1073748826_8002.meta
[root@hadoop44 finalized]# du -sh *
128M blk_1073748824
1.1M blk_1073748824_8000.meta
128M blk_1073748825
1.1M blk_1073748825_8001.meta
49M blk_1073748826
392K blk_1073748826_8002.meta
[root@hadoop55 finalized]# du -sh *
49M blk_1073748826
392K blk_1073748826_8002.meta
[root@hadoop66 finalized]# du -sh *
128M blk_1073748824
1.1M blk_1073748824_8000.meta
128M blk_1073748825
1.1M blk_1073748825_8001.meta经过验证:fsck命令输出的结果是正确的。
2、批脚本执行机制
利用完hdfs fsck机制之后,我们相当于间接确定了block块的位置,接下来我们将对应的block数据上传到hdfs中。
[root@hadoop33 finalized]# du -sh *
128M blk_1073748824
1.1M blk_1073748824_8000.meta
128M blk_1073748825
1.1M blk_1073748825_8001.meta
49M blk_1073748826
392K blk_1073748826_8002.meta
[root@hadoop33 finalized]# hadoop fs -put blk_1073748824 /
[root@hadoop33 finalized]# hadoop fs -put blk_1073748825 /
[root@hadoop33 finalized]# hadoop fs -put blk_1073748826 /编写脚本文件:
[root@hadoop11 local]# more app1.sh
#!/bin/sh
#执行三个wordcount任务
hadoop jar /usr/local/WordCount.jar /blk_1073748824 /dirpart1/
hadoop jar /usr/local/WordCount.jar /blk_1073748825 /dirpart2/
hadoop jar /usr/local/WordCount.jar /blk_1073748826 /dirpart3/
#查看其中的一个结果:
hadoop fs -cat /dirpart3/part-r-00000