Py-faster-rcnn实现自己的数据train和demo
在我的上两个博客中已经对py-faster-rcnn配置运行demo.py和py-faster-rcnn配置运行faster_rcnn_end2end—VGG_CNN_M_1024做出了相应说明,在本博客中我将对py-faster-rcnn实现自己的数据train和demo做出具体操作说明,希望可以解决大家在训练自己数据时出现的问题。如果有训练demo不成功的朋友可以和我联系,邮箱[email protected]
注意:如果对py-faster-rcnn配置运行demo.py和py-faster-rcnn配置运行faster_rcnn_end2end—VGG_CNN_M_1024不熟悉的朋友可以参考我的博客:http://blog.csdn.net/samylee/article/details/51086153和http://blog.csdn.net/samylee/article/details/51099508
好了,我们来玩玩这个py-faster-rcnn实现自己的数据train和demo
第一部分:制作自己的数据集
实验中我用的数据集是471张行人图片(由于部分原因,数据集不能公开,望大家见谅),标出其中的行人位置作为数据标签,所以我只检测了一类,原来的voc是检测20类的,这里我们为了做实验的方便,所以选择一类训练,加上背景为两类。
1、所需文件
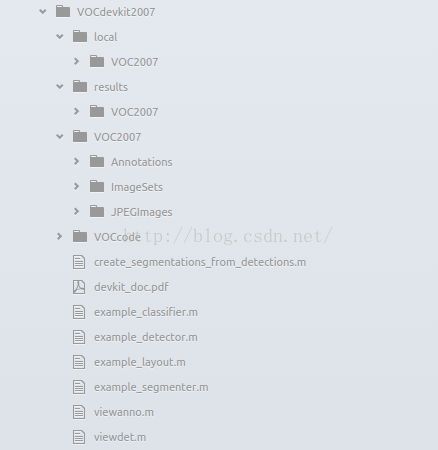
保留data/VOCdevkit2007/VOC2007/Annotations和ImageSets和JPEGImages文件夹名称,删除其中所有的文件(保留文件夹),并删除SegmenttationClass和SegmentationObject文件夹(用不到)。其中Annotations保存标签txt转换的xml文件,ImageSets保存train.txt、trainval.txt、test.txt、val.txt四个文件分别储存在layout、main和Segmentation文件夹中,最后JPEGImages保存所训练的数据。完整格式图片如下图所示:
2、Annotations中xml文件的制作
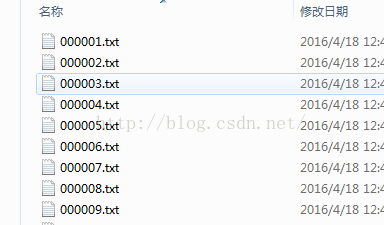
(1)标签txt可以使用matlab或python程序制作,这里不再赘述,文件格式:
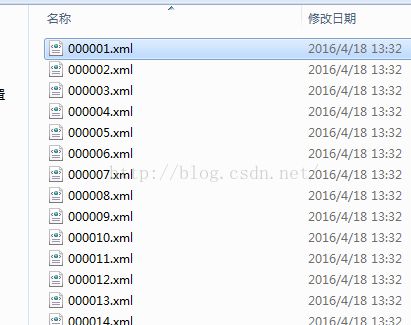
(2)xml文件生成所需matlab运行文件在此提供链接代码(链接:http://pan.baidu.com/s/1o85scXG 密码:mo3r),生成格式如下:

3、ImageSets中的trainval文件制作可以参考我的链接(链接:http://pan.baidu.com/s/1midBOjY 密码:jelr),具体制作代码这里不再提供,大家可以用matlab或Python编写。
第二部分、修改调用文件
1、 prototxt配置文件
models/pascal_voc/ZF/faster_rcnn_alt_opt文件夹下的5个文件,分别为stage1_rpn_train.pt、stage1_fast_rcnn_train.pt、stage2_rpn_train.pt、stage2_fast_rcnn_train.pt和fast_rcnn_test.pt,修改格式如下:
(1)stage1_fast_rcnn_train.pt和stage2_fast_rcnn_train.pt修改参数num_class:2(识别1类+背景1类),cls_score中num_output:2,bbox_pred中num_output:8。(只有这3个)
(2)stage1_rpn_train.pt和stage2_rpn_train.pt修改参数num_class:2(识别1类+背景1类)
(3)fast_rcnn_test.pt修改参数:cls_score中num_output:2,bbox_pred中num_output:8(只有这2个)
2、 修改lib/datasets/pascal_voc.py
self._classes = ('__background__', # always index 0
'people')(只有这一类)
3、修改lib/datasets/imdb.py
数据整理,在一行代码为 boxes[:, 2] = widths[i] - oldx1 - 1下加入代码:for b in range(len(boxes)):
if boxes[b][2]< boxes[b][0]:
boxes[b][0] = 0
4、修改完pascal_voc.py和imdb.py后进入lib/datasets目录下删除原来的pascal_voc.pyc和imdb.pyc文件,重新生成这两个文件,因为这两个文件是python编译后的文件,系统会直接调用。
终端进入lib/datasets文件目录输入:
python(此处应出现python的版本)
>>>importpy_compile
>>>py_compile.compile(r'imdb.py')
>>>py_compile.compile(r'pascal_voc.py')
第三部分、训练自己的数据
终端进入py-faster-rcnn下输入:
./experiments/scripts/faster_rcnn_alt_opt.sh0 ZF pascal_voc
第四部分:demo自己刚刚生成的ZF_models
1、训练完成之后,将output/faster_rcnn_alt_opt/voc_2007_trainval中的最终模型ZF_faster_rcnn_final.caffemodel拷贝到data/faster_rcnn_models(删除以前生成类似的model)中。
2、修改/tools/demo.py为:
(1) CLASSES =('__background__',
'people')(只有这两类)
(2) NETS ={'vgg16': ('VGG16',
'VGG16_faster_rcnn_final.caffemodel'),
'zf': ('ZF',
'ZF_faster_rcnn_final.caffemodel')}
(3)在训练集图片中找一张出来放入py-faster-rcnn/data/demo文件夹中,命名为000001.jpg。
im_names = ['000001.jpg'](只需这一类图片的一张,其他删除或注销)
for im_name in im_names:
print '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~'
print 'Demo for data/demo/{}'.format(im_name)
demo(net, im_name)
3、运行demo,即在py-faster-rcnn文件夹下终端输入:
./tools/demo.py --net zf
我的试验结果如图所示(由于数据量很小,所以识别率不是很好,不过作为实验数据,应该可以满足要求,如果大家有兴趣还可以修改vgg等网络做进一步训练演示):
