关于TCP传输速率的测量方法
人们非常关心下载速度,对于使用非包月宽带以及使用付费CDN的用户而言,这是典型的拿钱买时间的行为,我支付的费用越高,希望的下载速度越快,所使用的累积带宽越大。关于各种测速方法也是汗牛充栋了,本文介绍一下TCP传输的测速。
网设备的pps线速都是超高的,如果你想优化那些设备的转发表,路由查找等逻辑,那是没找对地方,如今都是线卡硬件快速转发,交换网络处理都是纳秒级的,如果想优化路由转发等,那就去华为做光猫的部门谋份职位吧,那里会让你大展才华(绝非广告!)。再次重申,中间网络设备的处理时延主要是指排队时延。
知道了上述的因素,那么我们如果想测量一条TCP连接的数据传输速率,该怎么办呢?
理论非常简单但却很苍白!总数据量除以时间。然而问题是,我在哪个层面上去测量速率,我需要什么样的精度。如果说我想知道我的主机的处理速率,那么时间就是指本机的处理时延,数据量就是在该时延内通过的数据量,更一般的,如果我想知道一个文件从一个WEB服务器上下载下来的速率,我就需要用总文件大小除以下载完成需要的时间,这部分时间包括上述三种时延的总和。
这就涉及到了打点采样的问题了,本质上是两个问题,第一,在哪里开始打点采样,在哪里结束打点采样,第二,如何采样。
问题是当前速率真的就是用固定采样间隔的数据量除以时间间隔这么简单吗?非也!事实上,大部分的下载工具以及浏览器使用的都是移动指数平均算法,据我所知,早期的IE没有使用该算法,而是使用瞬时采样值直接除以时间这种,你会看到用早期的IE下载文件,剩余时间的抖动特别大,一会儿是几分钟,一会儿就是几小时。
公式我就不写了,挺麻烦的,一提到数学公式,懂的人不答理你,不懂的人说你装,也挺头大。
一般而言,像HTTP协议这样的,响应头里都会有文件的大小字节数,应用程序收到这么多字节就结束打点采样,就能统计到下载这么多数据所使用的时间。这完全是像HTTP协议这样的应用层协议的功劳,它告诉了我足够的信息。
在内核协议栈里面统计这些就难了!因为内核看到的只有一条TCP流,除非收到FIN,否则不知道什么时候会结束,也不会在一开始就知道后续数据的传输量...
TCP协议栈层面的瞬时速度是指导TCP发送策略本身用的,我们知道TCP是一个把全世界都卷进来的反馈系统(把它看作全世界范围的受蝴蝶效应影响的混沌系统也行),它需要网络的反馈来指导它未来的行为。之前我曾经不厌其烦的说ACK时钟如何影响TCP对拥塞的感应等等,诚然那些并没有错,但是在本文中,我们上升一个层面,来看一下ACK所确认的数据量和RTT的共同作用。这个作用所反应的就是TCP传输速率。我们需要一个速率可以代表一个趋势,然后用这个趋势去指导TCP拥塞窗口的调整,这就需要平滑掉该速率的噪点,于是又一次我们遇到了移动指数平均!
我们先看一下瞬时速度怎么测量。

这个证明是很容易的:

证明了上面的等式后,我们同时也就有了计算瞬时速率的方法:
1.任意取一点设为T1,获取当时发送出去但是尚未得到确认的数据量以及相关序列号
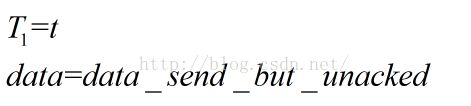
2.在收到ACK的时候,记为T2,计算此ACK确认的数据量,用第一步的数据量减去本次确认的数据量
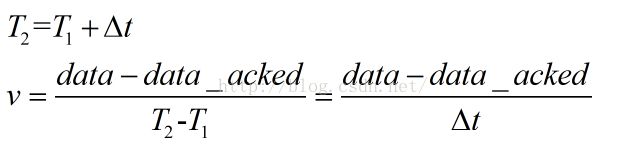
3.每次收到ACK时迭代上述过程,做移动指数平均
话说瞬时速度是指导连接内行为的,这个瞬时值的变化趋势可以在连接内被学习到,同时反作用于后续的速率调整,它反应了当前的网络状态以及该TCP连接对网络状态的反应,然而平均速率反应的是一种长期行为,比如我们可以通过对平均速率的分析了解链路的普遍状况等。这个平均值对于长期的机器学习行为更有统计上的意义。
和应用层的平均速度测量一样,它比瞬时值的测量要更简单,但是我们要换一种思路,因为没有人事先告诉你有多少数据要下载。在TCP中,这个我们可以事后统计到,用FIN时的序列号减去连接初始时的序列号,就是发送的字节数。总的来讲,测试平均速度就是计算两个量,一个是数据总量,一个是时间总量,然而二者相除:
首先,计算分子的加和是简单的,无非就是FIN的时候将序列号减去SYN-ACK时的初始序列号,难点在于分母的时间片加和。其实也不难,如果仅仅是理论分析,我想已经可以结束了,然而我们必须实现它的时候,难点就在于你对协议栈代码的理解深度了,如果熟悉代码,那也是三下五除二的事,但是不要走偏,不要让他人影响你的判断,很简单的事情很多人一讨论就无解了。我先给出答案:
1).应用层数据进入TCP发送队列的时候判断
如果此时队列长度为0,开始新一轮打点计时,否则什么都不做。
2).ACK到来清除TCP发送队列的时候判断
如果该ACK清空了发送队列,结束上一轮的计时,统计时间差,累加时间差。
然后我们看一下代码如何实现,非常简单的不超过20行的代码,除却DEBUG信息,更少!代码如下:
测试
[root@localhost ~]# curl http://1.1.1.2/big10 >/dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9765k 100 9765k 0 0 1210k 0 0:00:08 0:00:08 --:--:-- 1210k
WEB服务器上dmesg信息:
saddr:1.1.1.2 sport:80 dport:60463 tot_byte:0x989783 time:8 061474566 [8 062002622], 2 2
可以看出,客户端统计的信息,服务端的连接时长,传输时长三者都是相同的,然而用浏览器下载这个big10试一下,我同样给出WEB服务器的dmesg输出:
saddr:192.168.44.100 sport:80 dport:61023 tot_byte:0x9897bc time:8 110491001 [15 156020871], 4 4
为什么连接时间和数据传输时间会差这么多?我想这部分就是所谓的浏览器的动作所消耗的时间吧。为了确认一下,我修改了ab.c,在write_request函数之前加了个sleep(5)
得到的结果跟浏览器访问的结果一样。为了用一种更加优雅的方式确认,我还特意请教了前公司的同事(WEB高手,高性能服务器专家,PHP高手,感兴趣的可以联系我),他告诉我一个很好用的测试方法:
[root@localhost ~]# curl http://1.1.1.2/{big10,sleep.php,big10} >/dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9765k 100 9765k 0 0 1214k 0 0:00:08 0:00:08 --:--:-- 1213k
0 0 0 0 0 0 0 0 --:--:-- 0:00:05 --:--:-- 0
100 9765k 100 9765k 0 0 1215k 0 0:00:08 0:00:08 --:--:-- 1213k
命令中的sleep.php如下:
saddr:1.1.1.2 sport:80 dport:53362 tot_byte:0x1312fb2 time:16 067200380 [21 069762118], 5 5
可以看出连接时间正好比传输时间多了5s,这是一个可控的测试。事后我想让他再帮我写一个更猛的PHP,他就不理我了...估计是觉得太简单了吧,真是术业有专攻,隔行如隔山。
虽然我比较喜欢数学,物理等理论性的东西,但我更喜欢show me the code,而不是document。你不懂,我不懂,他也不懂,大家在一起一唠嗑,大家就都懂了,这是鬼话。明确的说吧,以上写的东西都是大家讨论时被否掉的,但是事后冷静一想,不对呀,测试表明一切OK啊,到底谁错了,我不想让想法付之东流,就写了这篇...我不反对头脑风暴,但是更加认同专家型的头脑风暴,不然的话,大家都是满怀着激动的心,事事处处想挑战别人,见缝插针,我想这不是恶意,而是氛围所导致。
本无意参与的人只是提一点小意见,结果就引发了所有人开始狂喷啊狂喷,毫无意义,毫无结果,理智在消退,胜利才是关键,只要有人提出一个方案,就会有人否定,什么都不对,什么都不妥,但是事实其实并没有这么恶劣。各国的领导人在记者招待会的表现我想大家都看到过,最佳的方式就是闭口不言,不然会被愤怒者扔鞋。在某种意义上,“挑战”是一个贬义词,它会扰乱你的思考,混淆你的视听,让你为了应对挑战举手投足而错乱,然后散会后,80%的人在整理好自己的思路后会发现自己并没有错。
最后我想说几点关于规避挑战的问题,如果有人对你所述的细节不理解,那么就会有人追问,如果你面对他时没有气场,那你无疑会被引入他的思路,然后你就彻底乱了,大家都有过这样的经历,我试举出几例:
1.面试的时候
如果你再某方面你不是专家,就不要胡扯,不然被问起来会非常尴尬。面试官就在你面前,可能他也不懂,但是就是气场比你强,你怎么办呢?
2.对待项目先斩后奏的时候
我切身的体会,几年前我觉得领导的方法不对,我按着自己的想法做事,幸运的是,我成功了。但是成功的秘诀就是快速拿出你的1.0版本,而不是去跟他讨论方案。皇帝让将军开会讨论如何擒敌,将军逃避会议,并且不辞而别杳无音信,最好的办法就是,带敌将的头回来,一切都好说。
3.被老婆查手机的时候
也是我切身的体会。被查手机的时候,即便什么都没有发生,我依然觉得很慌张,这种神情被老婆看到,不断的挑战就开始了,其实我什么都没有做,但是回答起来还是略微的语无伦次,这是为什么?难道我错了吗?没有!关键在气场!气场不足,没错也变有错了,对方会说,没有问题你干嘛紧张!
4.跟别人借钱的时候
这个话题不多说,借一次钱你就明白了。
最后的最后,现在是2016/06/25 07:53,我从凌晨3点多开始写这个,到了现在,中间有一些演算的过程,还拉了一脬屎。我为什这么早起来,其实我本来想5点半起床的,无奈昨晚女儿狂蹿我三脚,一脚在肚子,一脚在太阳穴,一脚在肋骨...我无法忍受,只能半夜爬起来写点东西了...爆炸!
TCP速率概述
首先,TCP速率受到多方面时延的影响,其中包括:1.本机以及对端机器的处理时延
这部分指的是发送端和接收端主机由于操作系统调度,中断,网卡数据包调度等处理引入的时延,基本属于操作系统的范畴,如果一个TCP数据包可以发送(窗口足够容纳),但是由于此时CPU被操作系统切换到了另外一个进程造成了延迟,或者说该数据包确实已经被发送了,但是由于网卡性能很低,需要将数据包的内容逐字节的拷贝,这也会引入额外的延迟,这部分时间就应该算到主机处理时延中。2.中间网络设备的处理时延
这是中间设备的“主机处理时延”,与端主机的处理时延类似,所不同的是,这部分时延大多数是排队时延,相比较排队时延,路由器或者交换机的处理时延可以忽略,当前骨干网设备的pps线速都是超高的,如果你想优化那些设备的转发表,路由查找等逻辑,那是没找对地方,如今都是线卡硬件快速转发,交换网络处理都是纳秒级的,如果想优化路由转发等,那就去华为做光猫的部门谋份职位吧,那里会让你大展才华(绝非广告!)。再次重申,中间网络设备的处理时延主要是指排队时延。
3.中间网络的传输时延
这部分就不多说了,我们知道,光速很快,但也是有个值的,也就是说,光从一个地方到达另一个地方也是需要时间的,因此数据在载波中通过介质从一个主机到达另一个主机或者中间节点也是需要时间的,这部分时间就是网络传输时间,它主要受到串扰,折射率,光色散等物理因素的影响。知道了上述的因素,那么我们如果想测量一条TCP连接的数据传输速率,该怎么办呢?
理论非常简单但却很苍白!总数据量除以时间。然而问题是,我在哪个层面上去测量速率,我需要什么样的精度。如果说我想知道我的主机的处理速率,那么时间就是指本机的处理时延,数据量就是在该时延内通过的数据量,更一般的,如果我想知道一个文件从一个WEB服务器上下载下来的速率,我就需要用总文件大小除以下载完成需要的时间,这部分时间包括上述三种时延的总和。
这就涉及到了打点采样的问题了,本质上是两个问题,第一,在哪里开始打点采样,在哪里结束打点采样,第二,如何采样。
应用层下载测速
1.瞬时速度的移动指数平均
打开浏览器,下载一个文件,各种下载工具或者浏览器自带的下载器上会显示一个下载速度以及剩余时间,这些值是怎么得到的呢?非常简单,下载工具或者浏览器本身也是一个应用程序,它可以在内部进行数据采样,比如固定间隔打点,然后统计这段间隔收到的数据量,二者相除得到速率,至于是剩余时间,一般通过协议获取,比如HTTP协议的响应中一般会有该信息,然后用剩余大小除以当前速率就是剩余时间。就是这么简单!问题是当前速率真的就是用固定采样间隔的数据量除以时间间隔这么简单吗?非也!事实上,大部分的下载工具以及浏览器使用的都是移动指数平均算法,据我所知,早期的IE没有使用该算法,而是使用瞬时采样值直接除以时间这种,你会看到用早期的IE下载文件,剩余时间的抖动特别大,一会儿是几分钟,一会儿就是几小时。
公式我就不写了,挺麻烦的,一提到数学公式,懂的人不答理你,不懂的人说你装,也挺头大。
2.平均速度的精确测量
上面说的是瞬时速度的测量方法,如果想统计一次下载的平均速度呢?事实上更简单,这个统计由于是下载完成后做的,因此此时我已经有了足够的信息去计算这个平均速度,下载文件的总大小我是有的,总时间我可以通过HTTP协议统计出来,二者相除就是最终答案。一般而言,像HTTP协议这样的,响应头里都会有文件的大小字节数,应用程序收到这么多字节就结束打点采样,就能统计到下载这么多数据所使用的时间。这完全是像HTTP协议这样的应用层协议的功劳,它告诉了我足够的信息。
在内核协议栈里面统计这些就难了!因为内核看到的只有一条TCP流,除非收到FIN,否则不知道什么时候会结束,也不会在一开始就知道后续数据的传输量...
协议栈传输测速
前段时间遇到一个需求,说是能不能在网卡层面统计到达某一个端口的流量,我说不能...我没有撒谎,即便能做到,我也不想做。1.瞬时速度的移动指数平均
下载工具的瞬时速度是让人看的,人们更关注通过这个瞬时速度计算出来的剩余时间,让人们有个预期,好安排在一部电影下载完成之前是不是有时间去楼下便利店买几罐啤酒。TCP要这个速度有什么用呢?TCP协议栈层面的瞬时速度是指导TCP发送策略本身用的,我们知道TCP是一个把全世界都卷进来的反馈系统(把它看作全世界范围的受蝴蝶效应影响的混沌系统也行),它需要网络的反馈来指导它未来的行为。之前我曾经不厌其烦的说ACK时钟如何影响TCP对拥塞的感应等等,诚然那些并没有错,但是在本文中,我们上升一个层面,来看一下ACK所确认的数据量和RTT的共同作用。这个作用所反应的就是TCP传输速率。我们需要一个速率可以代表一个趋势,然后用这个趋势去指导TCP拥塞窗口的调整,这就需要平滑掉该速率的噪点,于是又一次我们遇到了移动指数平均!
我们先看一下瞬时速度怎么测量。
可以使用和用户态的方法一样的算法,固定间隔内统计收到的数据量,但是在协议栈,我们有更好的算法,这是因为我们可以借助于ACK。我们通过下图来描述算法:
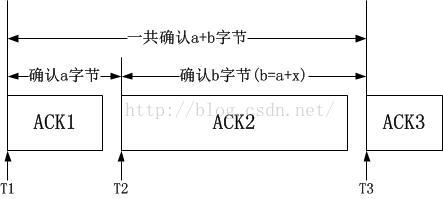
这个证明是很容易的:
证明了上面的等式后,我们同时也就有了计算瞬时速率的方法:
1.任意取一点设为T1,获取当时发送出去但是尚未得到确认的数据量以及相关序列号
2.在收到ACK的时候,记为T2,计算此ACK确认的数据量,用第一步的数据量减去本次确认的数据量
3.每次收到ACK时迭代上述过程,做移动指数平均
好了,我们通过ACK时钟流简单的搞定了瞬时速率值的计算。用这个可以指导很多事情,但不属于本文的范围。
2.平均速率的精确测量
上一节我们搞定了瞬时速度,但是由于做了移动指数平均平滑了噪点,所以我们丢失了部分信息,如果说我们需要一个精确的平均速度该怎么办呢?话说瞬时速度是指导连接内行为的,这个瞬时值的变化趋势可以在连接内被学习到,同时反作用于后续的速率调整,它反应了当前的网络状态以及该TCP连接对网络状态的反应,然而平均速率反应的是一种长期行为,比如我们可以通过对平均速率的分析了解链路的普遍状况等。这个平均值对于长期的机器学习行为更有统计上的意义。
和应用层的平均速度测量一样,它比瞬时值的测量要更简单,但是我们要换一种思路,因为没有人事先告诉你有多少数据要下载。在TCP中,这个我们可以事后统计到,用FIN时的序列号减去连接初始时的序列号,就是发送的字节数。总的来讲,测试平均速度就是计算两个量,一个是数据总量,一个是时间总量,然而二者相除:
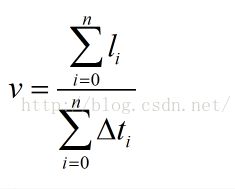
首先,计算分子的加和是简单的,无非就是FIN的时候将序列号减去SYN-ACK时的初始序列号,难点在于分母的时间片加和。其实也不难,如果仅仅是理论分析,我想已经可以结束了,然而我们必须实现它的时候,难点就在于你对协议栈代码的理解深度了,如果熟悉代码,那也是三下五除二的事,但是不要走偏,不要让他人影响你的判断,很简单的事情很多人一讨论就无解了。我先给出答案:
1).应用层数据进入TCP发送队列的时候判断
如果此时队列长度为0,开始新一轮打点计时,否则什么都不做。
2).ACK到来清除TCP发送队列的时候判断
如果该ACK清空了发送队列,结束上一轮的计时,统计时间差,累加时间差。
然后我们看一下代码如何实现,非常简单的不超过20行的代码,除却DEBUG信息,更少!代码如下:
TCP客户端scocket创建的时候,初始化字段
我在tcp_sock结构体中添加了几个字段,就不贴代码了,直接给出函数吧。struct sock *tcp_v4_syn_recv_sock(struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst)
{
...
inet_csk(newsk)->icsk_ext_hdr_len = 0;
#if 1
// 初始化时间片差字段
newtp->vstamp = ktime_set(0, 0);
// 初始化时间累加和字段
newtp->pvstamp = ktime_set(0, 0);
// 记录第一个序列号
newtp->first_seq = newtp->snd_nxt;
#ifdef REAL_TIME_DEBUG
// 为了比较纯传输时间和连接时间的差异,引入一个字段记录连接时间开始
newtp->first = 1;
// 以下两个字段为了确认“入队/清空”的守恒
newtp->pri1 = 0;
newtp->pri2 = 0;
#endif
#endif
...
}
在数据进入发送队列的时候计时
TCP数据统一通过skb_entail进入发送队列static void skb_entail(struct sock *sk, struct sk_buff *skb)
{
...
tcb->flags = TCPCB_FLAG_ACK;
tcb->sacked = 0;
#if 1
// 如果发送队列为空,则开始新一轮计时
if (tcp_write_queue_head(sk) == NULL) {
tp->vstamp = ktime_get_real();
#ifdef REAL_TIME_DEBUG
tp->pri1 ++;
// 如果是首次发送数据,则记录时间
if (tp->first == 1) {
tp->bstamp = tp->vstamp;
tp->first = 0;
#endif
}
}
#endif
...
}
在收到ACK的时候,检测发送队列是否已经清空
TCP数据的ACK统一通过tcp_clean_rtx_queue进行清理static int tcp_clean_rtx_queue(struct sock *sk, int prior_fackets,
u32 prior_snd_una)
{
...
while ((skb = tcp_write_queue_head(sk)) && skb != tcp_send_head(sk)) {
}
#if 1
// 如果队列已经清空,统计从第一个数据包入队到队列清空之间的时间差,并累加到计数器上。
if (tcp_write_queue_head(sk) == NULL && tp->vstamp.tv64 != 0) {
ktime_t delta = net_timedelta(tp->vstamp);
tp->pvstamp = ktime_add(tp->pvstamp, delta);
tp->vstamp = ktime_set(0, 0);
#ifdef REAL_TIME_DEBUG
tp->pri2++;
#endif
}
#endif
...
}
4.在TCP关闭连接的时候,输出结果
我觉得目前这个东西没有什么用,所以只是简单printk出来看看即可,所以就不穿皮鞋了:void tcp_v4_destroy_sock(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
#if 1
struct inet_sock *inet = inet_sk(sk);
u32 delta_seq = tp->snd_nxt - tp->first_seq - 1;
// tsval是纯数据传输的用时
struct timespec tsval = ktime_to_timespec(tp->pvstamp);
// ttot则是TCP连接中从数据传输开始到连接结束的总用时
struct timespec ttot = ktime_to_timespec(ktime_sub(ktime_get_real(), tp->bstamp));
#ifdef REAL_TIME_DEBUG
printk("saddr:%pI4 sport:%u dport:%u tot_byte:%#x time:%lu %09lu [%lu %09lu], %u %u\n",
&inet->saddr,
ntohs(inet->sport),
ntohs(inet->dport),
delta_seq,
(unsigned long)tsval.tv_sec,
(unsigned long)tsval.tv_nsec,
(unsigned long)ttot.tv_sec,
(unsigned long)ttot.tv_nsec,
tp->pri1,
tp->pri2);
#endif
#endif
}
好了,我们来看一下测试效果。
测试
如果你用curl,ab,wget去自己搭建的WEB服务器上下载一个文件:
客户端:[root@localhost ~]# curl http://1.1.1.2/big10 >/dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9765k 100 9765k 0 0 1210k 0 0:00:08 0:00:08 --:--:-- 1210k
WEB服务器上dmesg信息:
saddr:1.1.1.2 sport:80 dport:60463 tot_byte:0x989783 time:8 061474566 [8 062002622], 2 2
可以看出,客户端统计的信息,服务端的连接时长,传输时长三者都是相同的,然而用浏览器下载这个big10试一下,我同样给出WEB服务器的dmesg输出:
saddr:192.168.44.100 sport:80 dport:61023 tot_byte:0x9897bc time:8 110491001 [15 156020871], 4 4
为什么连接时间和数据传输时间会差这么多?我想这部分就是所谓的浏览器的动作所消耗的时间吧。为了确认一下,我修改了ab.c,在write_request函数之前加了个sleep(5)
得到的结果跟浏览器访问的结果一样。为了用一种更加优雅的方式确认,我还特意请教了前公司的同事(WEB高手,高性能服务器专家,PHP高手,感兴趣的可以联系我),他告诉我一个很好用的测试方法:
[root@localhost ~]# curl http://1.1.1.2/{big10,sleep.php,big10} >/dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9765k 100 9765k 0 0 1214k 0 0:00:08 0:00:08 --:--:-- 1213k
0 0 0 0 0 0 0 0 --:--:-- 0:00:05 --:--:-- 0
100 9765k 100 9765k 0 0 1215k 0 0:00:08 0:00:08 --:--:-- 1213k
命令中的sleep.php如下:
<?php sleep(5); ?>服务端dmesg输出如下:
saddr:1.1.1.2 sport:80 dport:53362 tot_byte:0x1312fb2 time:16 067200380 [21 069762118], 5 5
可以看出连接时间正好比传输时间多了5s,这是一个可控的测试。事后我想让他再帮我写一个更猛的PHP,他就不理我了...估计是觉得太简单了吧,真是术业有专攻,隔行如隔山。
写在最后
够了,现在已经基本完成了本文,后面谁看到想用就用吧。很多事情需要你自己去思考,而不是大家一起讨论,讨论的前提是你已经有了哪怕是0.1版本,如果没有,讨论就是扯淡!虽然我比较喜欢数学,物理等理论性的东西,但我更喜欢show me the code,而不是document。你不懂,我不懂,他也不懂,大家在一起一唠嗑,大家就都懂了,这是鬼话。明确的说吧,以上写的东西都是大家讨论时被否掉的,但是事后冷静一想,不对呀,测试表明一切OK啊,到底谁错了,我不想让想法付之东流,就写了这篇...我不反对头脑风暴,但是更加认同专家型的头脑风暴,不然的话,大家都是满怀着激动的心,事事处处想挑战别人,见缝插针,我想这不是恶意,而是氛围所导致。
本无意参与的人只是提一点小意见,结果就引发了所有人开始狂喷啊狂喷,毫无意义,毫无结果,理智在消退,胜利才是关键,只要有人提出一个方案,就会有人否定,什么都不对,什么都不妥,但是事实其实并没有这么恶劣。各国的领导人在记者招待会的表现我想大家都看到过,最佳的方式就是闭口不言,不然会被愤怒者扔鞋。在某种意义上,“挑战”是一个贬义词,它会扰乱你的思考,混淆你的视听,让你为了应对挑战举手投足而错乱,然后散会后,80%的人在整理好自己的思路后会发现自己并没有错。
最后我想说几点关于规避挑战的问题,如果有人对你所述的细节不理解,那么就会有人追问,如果你面对他时没有气场,那你无疑会被引入他的思路,然后你就彻底乱了,大家都有过这样的经历,我试举出几例:
1.面试的时候
如果你再某方面你不是专家,就不要胡扯,不然被问起来会非常尴尬。面试官就在你面前,可能他也不懂,但是就是气场比你强,你怎么办呢?
2.对待项目先斩后奏的时候
我切身的体会,几年前我觉得领导的方法不对,我按着自己的想法做事,幸运的是,我成功了。但是成功的秘诀就是快速拿出你的1.0版本,而不是去跟他讨论方案。皇帝让将军开会讨论如何擒敌,将军逃避会议,并且不辞而别杳无音信,最好的办法就是,带敌将的头回来,一切都好说。
3.被老婆查手机的时候
也是我切身的体会。被查手机的时候,即便什么都没有发生,我依然觉得很慌张,这种神情被老婆看到,不断的挑战就开始了,其实我什么都没有做,但是回答起来还是略微的语无伦次,这是为什么?难道我错了吗?没有!关键在气场!气场不足,没错也变有错了,对方会说,没有问题你干嘛紧张!
4.跟别人借钱的时候
这个话题不多说,借一次钱你就明白了。
最后的最后,现在是2016/06/25 07:53,我从凌晨3点多开始写这个,到了现在,中间有一些演算的过程,还拉了一脬屎。我为什这么早起来,其实我本来想5点半起床的,无奈昨晚女儿狂蹿我三脚,一脚在肚子,一脚在太阳穴,一脚在肋骨...我无法忍受,只能半夜爬起来写点东西了...爆炸!