hadoop学习-Netflix电影推荐系统
1、推荐系统概述
电子商务网站是推荐系统应用的重要领域之一,当当网的图书推荐,大众点评的美食推荐,QQ好友推荐等等,推荐无处不在。
从企业角度,推荐系统的应用可以增加销售额等等,对于用户而言,系统仿佛知道我们的喜好并给出推荐也是非常美妙的事情。
推荐算法分类:
按数据使用划分:
- 协同过滤算法:UserCF, ItemCF, ModelCF
- 基于内容的推荐: 用户内容属性和物品内容属性
- 社会化过滤:基于用户的社会网络关系
按模型划分:
- 最近邻模型:基于距离的协同过滤算法
- Latent Factor Mode(SVD):基于矩阵分解的模型
- Graph:图模型,社会网络图模型
本文采用协同过滤算法来实现电影推荐。下面介绍下基于用户的协同过滤算法UserCF和基于物品的协同过滤算法ItemCF原理。
基于用户的协同过滤算法UserCF
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
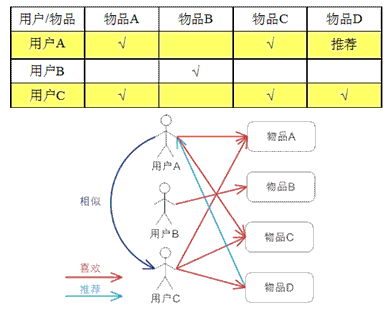
更多关于算法实现可参考Mahout In Action这本书
基于物品的协同过滤算法ItemCF
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
用例说明:

更多关于算法实现可参考Mahout In Action这本书
目前商用较多采用该算法。
2、数据源
切入正题,本文采用的数据源是Netflix公司的电影评分数据。Netflix是一家以在线电影租赁为生的公司。他们根据网友对电影的打分来判断用户有可能喜欢什么电影,并结合会员看过的电影以及口味偏好设置做出判断,混搭出各种电影风格的需求。
Netflix数据下载:
完整数据集:http://www.lifecrunch.biz/wp-content/uploads/2011/04/nf_prize_dataset.tar.gz
3、算法模型 MapReduce实现
先看下数据格式;
1,101,5.0 1,102,3.0 1,103,2.5 2,101,2.0 2,102,2.5 2,103,5.0 2,104,2.0 3,101,2.0 3,104,4.0 3,105,4.5 3,107,5.0 4,101,5.0 4,103,3.0 4,104,4.5 4,106,4.0 5,101,4.0 5,102,3.0 5,103,2.0 5,104,4.0 5,105,3.5 5,106,4.0每行3个字段,依次是用户ID,电影ID,用户对电影的评分(0-5分,每0.5为一个评分点!)
算法实现过程:
- 建立物品的同现矩阵
- 建立用户对物品的评分矩阵
- 矩阵计算推荐结果
1)建立物品的同现矩阵
按照用户选择,在每个用户选择的物品中,将两两同时出现的物品次数记录下来。
[101] [102] [103] [104] [105] [106] [107] [101] 5 3 4 4 2 2 1 [102] 3 3 3 2 1 1 0 [103] 4 3 4 3 1 2 0 [104] 4 2 3 4 2 2 1 [105] 2 1 1 2 2 1 1 [106] 2 1 2 2 1 2 0 [107] 1 0 0 1 1 0 1该矩阵表示 ID为101 102的电影 同时被一个用户评分的次数为3。该矩阵是一个对称矩阵。
2)建立用户对物品的评分矩阵
按用户分组,找到每个用户所选的物品及评分
3 [101] 2.0 [102] 0.0 [103] 0.0 [104] 4.0 [105] 4.5 [106] 0.0 [107] 5.0表示ID为3的用户的评分数据
3)将以上2个矩阵相乘
[101] [102] [103] [104] [105] [106] [107] 3 R [101] 5 3 4 4 2 2 1 2.0 40.0 [102] 3 3 3 2 1 1 0 0.0 18.5 [103] 4 3 4 3 1 2 0 0.0 24.5 [104] 4 2 3 4 2 2 1 × 4.0 = 40.0 [105] 2 1 1 2 2 1 1 4.5 26.0 [106] 2 1 2 2 1 2 0 0.0 16.5 [107] 1 0 0 1 1 0 1 5.0 16.5R列分数最高的就是推荐结果;
这里为什么是2个矩阵相乘,结果的分数越高就是推荐结果呢。
简单分析如下:
当前ID为3的用户对ID为107的电影评分较高,可以理解为该用户喜欢这种类型的电影。
因此如果有一部电影和ID为107电影同时出现的次数越高,则可以理解为该电影和107电影比较类似,那么我们就可以将其推荐给用户3,也许他会喜欢。
这里同时出现的次数指的是很多用户都看过这2部电影,也就是我们说的这2部电影比较类似。
上面的矩阵中,我们可以看到104电影和107电影同时出现的次数为1,假设次数为10 ,那么R矩阵的结果会是:
R 40.0 18.5 24.5 <span style="color:#ff0000;">85.0</span> 26.0 16.5 16.5最大值变成85.0,那么我们可以推荐104电影给用户3观看。
以上是该算法的简单分析,详细原理介绍可以看Mahout In Action这本书
4、源代码实现
Recommend.java
- import java.util.HashMap;
- import java.util.Map;
- public class Recommend {
- public static void main(String[] args) throws Exception {
- Map<String, String> path = new HashMap<String, String>();
- path.put("data", args[0]);
- path.put("Step1Input", args[1]);
- path.put("Step1Output", path.get("Step1Input") + "/step1");
- path.put("Step2Input", path.get("Step1Output"));
- path.put("Step2Output", path.get("Step1Input") + "/step2");
- path.put("Step3Input1", path.get("Step1Output"));
- path.put("Step3Output1", path.get("Step1Input") + "/step3_1");
- path.put("Step3Input2", path.get("Step2Output"));
- path.put("Step3Output2", path.get("Step1Input") + "/step3_2");
- path.put("Step5Input1", path.get("Step3Output1"));
- path.put("Step5Input2", path.get("Step3Output2"));
- path.put("Step5Output", path.get("Step1Input") + "/step5");
- path.put("Step6Input", path.get("Step5Output"));
- path.put("Step6Output", path.get("Step1Input") + "/step6");
- Step1.step1Run(path);
- Step2.step2Run(path);
- Step3.step3Run1(path);
- Step3.step3Run2(path);
- Step4_1.run(path);
- Step4_2.run(path);
- System.exit(0);
- }
- }
Step1.java
- import java.io.IOException;
- import java.util.Iterator;
- import java.util.Map;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.io.IntWritable;
- public class Step1 {
- public static class MapClass
- extends Mapper<Object, Text, IntWritable, Text > {
- public void map(Object key, Text value,
- Context context ) throws IOException,
- InterruptedException {
- String[] list = value.toString().split(",");
- context.write(new IntWritable(Integer.parseInt(list[0])),new Text(list[1] + ":" +list[2]));
- }
- }
- public static class Reduce extends Reducer<IntWritable, Text, IntWritable, Text> {
- private Text value = new Text();
- public void reduce(IntWritable key, Iterable<Text> values,
- Context context) throws IOException,InterruptedException {
- StringBuilder sb = new StringBuilder();
- for (Text val : values) {
- sb.append( "," + val.toString());
- }
- value.set(sb.toString().replaceFirst(",", ""));
- context.write(key, new Text(value));
- }
- }
- public static void step1Run(Map<String, String> path) throws Exception {
- Configuration conf = new Configuration();
- String input = path.get("data");
- String output = path.get("Step1Output");
- Job job = new Job(conf, "step1Run");
- job.setJarByClass(Step1.class);
- job.setMapperClass(MapClass.class);
- job.setCombinerClass(Reduce.class);
- job.setReducerClass(Reduce.class);
- job.setOutputKeyClass(IntWritable.class);
- job.setOutputValueClass(Text.class);
- FileInputFormat.setInputPaths(job, new Path(input));
- FileOutputFormat.setOutputPath(job, new Path(output));
- job.waitForCompletion(true);
- }
- }
Step2.java
- import java.io.IOException;
- import java.util.Iterator;
- import java.util.Map;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.io.IntWritable;
- public class Step1 {
- public static class MapClass
- extends Mapper<Object, Text, IntWritable, Text > {
- public void map(Object key, Text value,
- Context context ) throws IOException,
- InterruptedException {
- String[] list = value.toString().split(",");
- context.write(new IntWritable(Integer.parseInt(list[0])),new Text(list[1] + ":" +list[2]));
- }
- }
- public static class Reduce extends Reducer<IntWritable, Text, IntWritable, Text> {
- private Text value = new Text();
- public void reduce(IntWritable key, Iterable<Text> values,
- Context context) throws IOException,InterruptedException {
- StringBuilder sb = new StringBuilder();
- for (Text val : values) {
- sb.append( "," + val.toString());
- }
- value.set(sb.toString().replaceFirst(",", ""));
- context.write(key, new Text(value));
- }
- }
- public static void step1Run(Map<String, String> path) throws Exception {
- Configuration conf = new Configuration();
- String input = path.get("data");
- String output = path.get("Step1Output");
- Job job = new Job(conf, "step1Run");
- job.setJarByClass(Step1.class);
- job.setMapperClass(MapClass.class);
- job.setCombinerClass(Reduce.class);
- job.setReducerClass(Reduce.class);
- job.setOutputKeyClass(IntWritable.class);
- job.setOutputValueClass(Text.class);
- FileInputFormat.setInputPaths(job, new Path(input));
- FileOutputFormat.setOutputPath(job, new Path(output));
- job.waitForCompletion(true);
- }
- }
Step3.java
- import java.io.IOException;
- import java.util.Iterator;
- import java.util.Map;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.io.IntWritable;
- public class Step3 {
- public static class Map1
- extends Mapper<Object, Text, IntWritable, Text> {
- private IntWritable k = new IntWritable();
- private Text v = new Text();
- public void map(Object key, Text value,
- Context context ) throws IOException,
- InterruptedException {
- String[] list = value.toString().split("\\\t|,");
- for(int i = 1;i<list.length ; i++)
- {
- String[] vector = list[i].split(":");
- int nItemID = Integer.parseInt(vector[0]);
- k.set(nItemID);
- v.set(list[0] + ":" + vector[1]);
- context.write(k,v);
- }
- }
- }
- public static class Map2
- extends Mapper<Object, Text, Text, IntWritable > {
- private IntWritable v = new IntWritable();
- private Text k = new Text();
- public void map(Object key, Text value,
- Context context ) throws IOException,
- InterruptedException {
- String[] list = value.toString().split("\\\t|,");
- k.set(list[0]);
- v.set(Integer.parseInt(list[1]));
- context.write(k,v);
- }
- }
- public static void step3Run1(Map<String, String> path) throws Exception {
- Configuration conf = new Configuration();
- String input = path.get("Step3Input1");
- String output = path.get("Step3Output1");
- Job job = new Job(conf, "step3Run1");
- job.setJarByClass(Step3.class);
- job.setMapperClass(Map1.class);
- job.setOutputKeyClass(IntWritable.class);
- job.setOutputValueClass(Text.class);
- FileInputFormat.setInputPaths(job, new Path(input));
- FileOutputFormat.setOutputPath(job, new Path(output));
- job.waitForCompletion(true);
- }
- public static void step3Run2(Map<String, String> path) throws Exception {
- Configuration conf = new Configuration();
- //String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
- //if(otherArgs.length != 2){
- // System.err.println("Usage: KPI <in> <out>");
- // System.exit(2);
- //}
- String input = path.get("Step3Input2");
- String output = path.get("Step3Output2");
- Job job = new Job(conf, "step3Run2");
- job.setJarByClass(Step3.class);
- job.setMapperClass(Map2.class);
- //job.setCombinerClass(Reduce.class);
- //job.setReducerClass(Reduce.class);
- //job.setInputFormat(KeyValueTextInputFormat.class);
- //job.setOutputFormat(TextOutputFormat.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.setInputPaths(job, new Path(input));
- FileOutputFormat.setOutputPath(job, new Path(output));
- job.waitForCompletion(true);
- }
- }
- import java.io.IOException;
- import java.util.HashMap;
- import java.util.Iterator;
- import java.util.Map;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapred.JobConf;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
- public class Step4_1 {
- public static class Step4_1_Mapper extends
- Mapper<Object, Text, Text, Text> {
- private String flag;// A同现矩阵 or B评分矩阵
- protected void setup(Context context) throws IOException, InterruptedException {
- FileSplit split = (FileSplit) context.getInputSplit();
- flag = split.getPath().getParent().getName();// 判断读的数据集
- // System.out.println(flag);
- }
- public void map(Object key, Text values, Context context) throws IOException, InterruptedException {
- String[] tokens = values.toString().split("\\\t|,");
- if (flag.equals("step3_2")) {// 同现矩阵
- String[] v1 = tokens[0].split(":");
- String itemID1 = v1[0];
- String itemID2 = v1[1];
- String num = tokens[1];
- Text k = new Text(itemID1);
- Text v = new Text("A:" + itemID2 + "," + num);
- context.write(k, v);
- } else if (flag.equals("step3_1")) {// 评分矩阵
- String[] v2 = tokens[1].split(":");
- String itemID = tokens[0];
- String userID = v2[0];
- String pref = v2[1];
- Text k = new Text(itemID);
- Text v = new Text("B:" + userID + "," + pref);
- context.write(k, v);
- }
- }
- }
- public static class Step4_1_Reducer extends Reducer<Text, Text, Text, Text> {
- public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
- Map<String, String> mapA = new HashMap<String, String>();
- Map<String, String> mapB = new HashMap<String, String>();
- for (Text line : values) {
- String val = line.toString();
- if (val.startsWith("A:")) {
- String[] kv = val.substring(2).split("\\\t|,");
- mapA.put(kv[0], kv[1]);
- } else if (val.startsWith("B:")) {
- String[] kv = val.substring(2).split("\\\t|,");
- mapB.put(kv[0], kv[1]);
- }
- }
- double result = 0;
- Iterator iter = mapA.keySet().iterator();
- while (iter.hasNext()) {
- String mapk = (String) iter.next();// itemID
- int num = Integer.parseInt(mapA.get(mapk));
- Iterator iterb = mapB.keySet().iterator();
- while (iterb.hasNext()) {
- String mapkb = (String) iterb.next();// userID
- double pref = Double.parseDouble(mapB.get(mapkb));
- result = num * pref;// 矩阵乘法相乘计算
- Text k = new Text(mapkb);
- Text v = new Text(mapk + "," + result);
- context.write(k, v);
- }
- }
- }
- }
- public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
- Configuration conf = new Configuration();
- String input1 = path.get("Step5Input1");
- String input2 = path.get("Step5Input2");
- String output = path.get("Step5Output");
- Job job = new Job(conf,"Step4_1");
- job.setJarByClass(Step4_1.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- job.setMapperClass(Step4_1_Mapper.class);
- job.setReducerClass(Step4_1_Reducer.class);
- job.setInputFormatClass(TextInputFormat.class);
- job.setOutputFormatClass(TextOutputFormat.class);
- FileInputFormat.setInputPaths(job, new Path(input1), new Path(input2));
- FileOutputFormat.setOutputPath(job, new Path(output));
- job.waitForCompletion(true);
- }
- }
- import java.io.IOException;
- import java.util.HashMap;
- import java.util.Iterator;
- import java.util.Map;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapred.JobConf;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
- public class Step4_2 {
- public static class Step4_2_Mapper extends
- Mapper<Object, Text, Text, Text> {
- public void map(Object key, Text values, Context context) throws IOException, InterruptedException {
- String[] tokens = values.toString().split("\\\t|,");
- Text k = new Text(tokens[0]);
- Text v = new Text(tokens[1]+","+tokens[2]);
- context.write(k, v);
- }
- }
- public static class Step4_2_Reducer extends Reducer<Text, Text, Text, Text> {
- public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
- Map<String, Double> map = new HashMap<String, Double>();
- for (Text line : values) {
- String[] tokens = line.toString().split("\\\t|,");
- String itemID = tokens[0];
- Double score = Double.parseDouble(tokens[1]);
- if (map.containsKey(itemID)) {
- map.put(itemID, map.get(itemID) + score);// 矩阵乘法求和计算
- } else {
- map.put(itemID, score);
- }
- }
- Iterator<String> iter = map.keySet().iterator();
- while (iter.hasNext()) {
- String itemID = iter.next();
- double score = map.get(itemID);
- Text v = new Text(itemID + "," + score);
- context.write(key, v);
- }
- }
- }
- public static void run(Map<String, String> path) throws IOException, InterruptedException, ClassNotFoundException {
- Configuration conf = new Configuration();
- String input = path.get("Step6Input");
- String output = path.get("Step6Output");
- Job job = new Job(conf,"Step4_2");
- job.setJarByClass(Step4_2.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- job.setMapperClass(Step4_2_Mapper.class);
- job.setReducerClass(Step4_2_Reducer.class);
- job.setInputFormatClass(TextInputFormat.class);
- job.setOutputFormatClass(TextOutputFormat.class);
- FileInputFormat.setInputPaths(job, new Path(input));
- FileOutputFormat.setOutputPath(job, new Path(output));
- job.waitForCompletion(true);
- }
- }
以上代码还有很多需要完善的地方,下次再重新整理。
附上github地址: https://github.com/y521263/Hadoop_in_Action
参考资料:
http://blog.fens.me/hadoop-mapreduce-recommend/