MapReduce的连接操作可以用于以下场景:
-
用户的人口统计信息的聚合操作(例如:青少年和中年人的习惯差异)。
-
当用户超过一定时间没有使用网站后,发邮件提醒他们。(这个一定时间的阈值是用户自己预定义的)
-
分析用户的浏览习惯。让系统可以基于这个分析提示用户有哪些网站特性还没有使用到。进而形成一个反馈循环。
所有这些场景都要求将多个数据集连接起来。
最常用的两个连接类型是内连接(inner join)和外连接(outer join)。如下图所示,内连接比较两个关系中所有的元组,判断是否满足连接条件,然后生成一个满足连接条件的结果集。与内连接相反的是,外连接并不需要两个关系的元组都满足连接条件。在连接条件不满足的时候,外连接可以将其中一方的数据保留在结果集中。
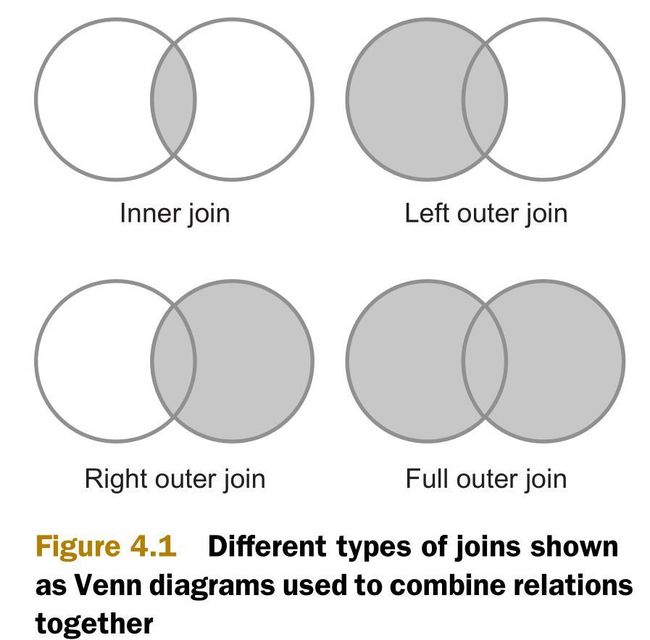
为了实现内连接和外连接,MapReduce中有三种连接策略,如下所示。这三种连接策略有的在map阶段,有的在reduce阶段。它们都针对MapReduce的排序-合并(sort-merge)的架构进行了优化。
-
重分区连接(Repartition join)—— reduce端连接。使用场景:连接两个或多个大型数据集。
-
复制连接(Replication join)—— map端连接。使用场景:待连接的数据集中有一个数据集足够小到可以完全放在缓存中。
-
半连接(Semi-join)—— 另一个map端连接。使用场景:待连接的数据集中有一个数据集非常大,但同时这个数据集可以被过滤成小到可以放在缓存中。
在介绍完这些连接策略之后,还会介绍另一个策略:决策树。可以根据实际情况选择最优策略。
4.1.1 重分区连接(Repartition join)
重分区连接是reduce端连接。它利用MapReduce的排序-合并机制来分组数据。它只使用一个单独的MapReduce任务,并支持多路连接(N-way join)。多路指的是多个数据集。
Map阶段负责从多个数据集中读取数据,决定每个数据的连接值,将连接值作为输出键(output key)。输出值(output value)则包含将在reduce阶段被合并的值。
Reduce阶段,一个reduce接收map函数传来的每一个输出键的所有输出值,并将数据分为多个分区。在此之后,reduce对所有的分区进行笛卡尔积(Cartersian product)连接运算,并生成全部的结果集。
以上MapReduce过程如图4.2所示:
| 注:过滤(filtering)和投影(projection) 在MapReduce重分区连接中,最好能够减少map阶段传输到reduce阶段的数据量。因为通过网络在这两个阶段中排序和传输数据会产生很高的成本。如果不能避免reduce端的工作,那么一个最佳实践就是尽可能在map阶段多过滤数据和投影。过滤指的是将map极端的输入数据中不需要的部分丢弃。投影是关系代数的概念。投影用于减少发送给reduce的字段。例如:在分析用户数据的时候,如果只关注用户的年龄,那么在map任务中应该只投影(或输出)年龄字段,不考虑用户的其他的字段。 |
技术19:优化重分区连接
《Hadoop in Action》给出了一个例子,说明如何使用Hadoop的社区包(contrib package)org.apache.hadoop.contrib.utils.join实现重分区连接。这个贡献包打包了所有的处理细节,仅仅需要实现一个非常简单的方法。
然而,这个社区包对重分区的实现方法的空间效率低下。它需要将待连接的所有输出值都读取到内存中,然后进行多路连接(multiway join)。实际上,如果仅仅将小数据集读取到内存中,然后用小数据集遍历大数据集来进行连接,这样将更加高效。
问题
需要在MapReduce中进行重分区连接,但是不希望在reduce阶段将所有的数据都放到缓存中。
解决方案
这个技术运用了优化后的重分区框架。它仅仅将一个待连接的数据集放在缓存中,减少了reduce需要放在缓存中的数据。
讨论
附录D中介绍了优化后的重分区框架的实现。这个实现是根据org.apache.hadoop.contrib.utils.join社区包进行建模。这个优化后的框架仅仅缓存两个数据集中比较小的那一个,以减少内存消耗。图4.3是优化后的重分区连接的流程图:
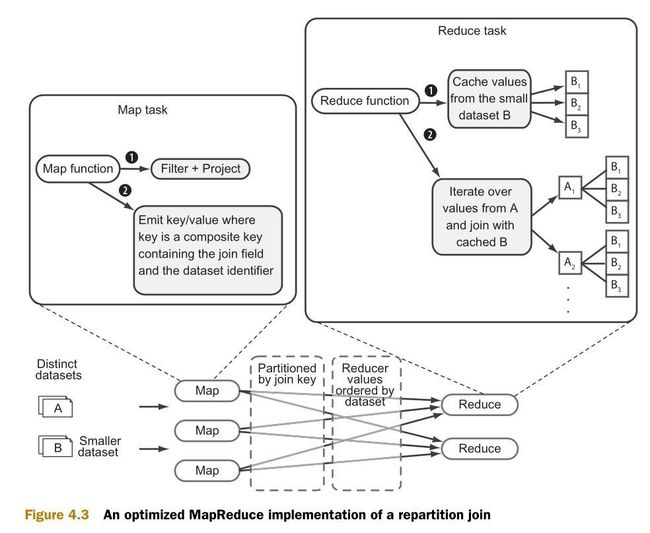
图4.4是实现的类图。类图中包含两个部分,一个通用框架和一些类的实现样例。
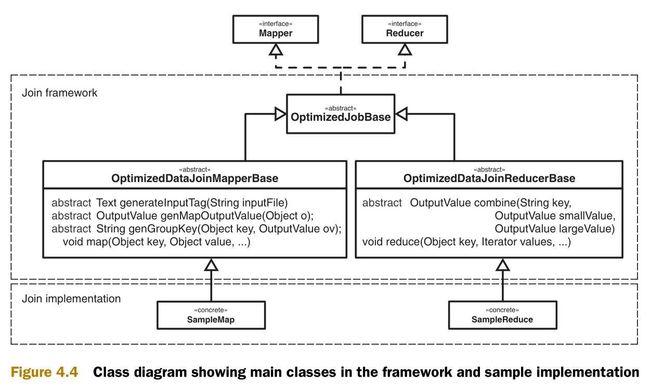
使用这个连接框架需要实现抽象类OptimizedDataJoinMapperBase和OptimizedDataJoinReducerBase。
例如,需要连接用户详情数据和用户活动日志。第一步,判断两个数据集中那一个比较小。对于一般的网站来说,用户详情数据会比较小,用户活动日志会比较大。
在如下示例中,用户数据中有用户姓名,年龄和所在州
- $ cat test-data/ch4/users.txt
- anne 22 NY
- joe 39 CO
- alison 35 NY
- mike 69 VA
- marie 27 OR
- jim 21 OR
- bob 71 CA
- mary 53 NY
- dave 36 VA
- dude 50 CA
用户活动日志中有用户姓名,进行的动作,来源IP。这个文件一般都要比用户数据要大得多。
- $ cat test-data/ch4/user-logs.txt
- jim logout 93.24.237.12
- mike new_tweet 87.124.79.252
- bob new_tweet 58.133.120.100
- mike logout 55.237.104.36
- jim new_tweet 93.24.237.12
- marie view_user 122.158.130.90
首先,必须实现抽象类OptimizedDataJoinMapperBase。这个将在map端被调用。这个类将创建map的输出键和输出值。同时,它还将提示整个框架,当前处理的文件是不是比较小的那个。
- public class SampleMap extends OptimizedDataJoinMapperBase {
-
- private boolean smaller;
-
- @Override
- protected Text generateInputTag(String inputFile) {
- // tag the row with input file name (data source)
- smaller = inputFile.contains("users.txt");
- return new Text(inputFile);
- }
-
- @Override
- protected String genGroupKey(Object key, OutputValue output) {
- return key.toString();
- }
-
- @Override
- protected boolean isInputSmaller(String inputFile) {
- return smaller;
- }
-
- @Override
- protected OutputValue genMapOutputValue(Object o) {
- return new TextTaggedOutputValue((Text) o);
- }
- }
下一步,你需要实现抽象类 OptimizedDataJoinReducerBase。它将在reduce端被调用。在这个类中,将从map端传入不同数据集的输出键和输出值,然后返回reduce端的输出数组。
- public class SampleReduce extends OptimizedDataJoinReducerBase {
-
- private TextTaggedOutputValue output = new TextTaggedOutputValue();
- private Text textOutput = new Text();
-
- @Override
- protected OutputValue combine(String key,
- OutputValue smallValue,
- OutputValue largeValue) {
- if(smallValue == null || largeValue == null) {
- return null;
- }
- Object[] values = {
- smallValue.getData(), largeValue.getData()
- };
- textOutput.set(StringUtils.join(values, "\t"));
- output.setData(textOutput);
- return output;
- }
最后,任务的主代码(driver code)需要指明InputFormat类,并设置次排序(Secondary sort)。
- job.setInputFormat(KeyValueTextInputFormat.class);
-
- job.setMapOutputKeyClass(CompositeKey.class);
- job.setMapOutputValueClass(TextTaggedOutputValue.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
-
- job.setPartitionerClass(CompositeKeyPartitioner.class);
- job.setOutputKeyComparatorClass(CompositeKeyComparator.class);
- job.setOutputValueGroupingComparator(CompositeKeyOnlyComparator.class);
现在连接的准备工作就做完了,可以开始运行连接:
- $ hadoop fs -put test-data/ch4/users.txt users.txt
- $ hadoop fs -put test-data/ch4/user-logs.txt user-logs.txt
- $ bin/run.sh com.manning.hip.ch4.joins.improved.SampleMain users.txt,user-logs.txt output
- $ hadoop fs -cat output/part*
- bob 71 CA new_tweet 58.133.120.100
- jim 21 OR logout 93.24.237.12
- jim 21 OR new_tweet 93.24.237.12
- jim 21 OR login 198.184.237.49
- marie 27 OR login 58.133.120.100
- marie 27 OR view_user 122.158.130.90
- mike 69 VA new_tweet 87.124.79.252
- mike 69 VA logout 55.237.104.36
如果和连接的源文件相对比,可以看到因为实现了一个内连接,输出中不包括用户anne,alison等不存在于日志文件中的记录。
小结:
这个连接的实现通过只缓存比较小的数据集来提高来Hadoop社区包的效率。但是,当数据从map阶段传输到reduce阶段的时候,仍然产生了很高的网络成本。
此外,Hadoop社区包支持多路连接,这里的实现只支持二路连接。
如果要更多地减少reduce端连接的内存足迹(memory footprint),一个简单的机制是在map函数中更多地进行投影操作。投影减少了map阶段的输出中的字段。例如:在分析用户数据的时候,如果只关注用户的年龄,那么在map任务中应该只投影(或输出)年龄字段,不考虑用户的其他的字段。这样就减少了map和reduce之间的网络负担,也减少了reduce在连接时的内存消耗。
和原始的社区包一样,这里的重分区的实现也支持过滤和投影。通过允许genMapOutputValue方法返回空值,就可以支持过滤。通过在genMapOutputValue方法中定义输出值的内容,就可以支持投影。
如果你既想输出所有的数据到reduce,又想避免排序的损耗,就需要考虑另外两种连接策略,复制连接和半连接。
附录D 优化后的MapReduce连接框架
在这个附录,我们将讨论在第4张中使用的两个连接框架。第一个是重连接框架。它减少了org.apache.hadoop.contrib.utils.join包的实现的Hadoop连接的内存足迹。第二个是复制连接框架。它可以将较小的数据集放在缓存中。
D.1 优化后的重分区框架
Hadoop社区连接包需要将每个键的所有值都读取到内存中。如何才能在reduce端的连接减少内存开销呢?本文提供的优化中,只需要缓存较小的数据集,然后在连接中遍历较大数据集中的数据。这个方法中还包括针对map的输出数据的次排序,那么reducer先接收到较小的数据集,然后接收到较大的数据集。图D.1是这个过程的流程图。
图D.2是实现的类图。类图中包含两个部分,一个通用框架和一些类的实现样例。

连接框架
我们以和Hadoop社区连接包的近似的风格编写连接的代码。目标是创建可以处理任意数据集的通用重分区机制。为简洁起见,我们重点说明主要部分。
首先是OptimizedDataJoinMapperBase类。这个类的作用是辨认出较小的数据集,并生成输出键和输出值。Configure方法在mapper创建时被调用。Configure方法的作用之一是标识每一个数据集,让reducer可以区分数据的源数据集。另一个作用是辨认当前的输入数据是否是较小的数据集。
- protected abstract Text generateInputTag(String inputFile);
-
- protected abstract boolean isInputSmaller(String inputFile);
-
- public void configure(JobConf job) {
-
- this.inputFile = job.get("map.input.file");
- this.inputTag = generateInputTag(this.inputFile);
-
- if(isInputSmaller(this.inputFile)) {
- smaller = new BooleanWritable(true);
- outputKey.setOrder(0);
- } else {
- smaller = new BooleanWritable(false);
- outputKey.setOrder(1);
- }
- }
Map方法首先调用自定义的方法 (generateTaggedMapOutput) 来生成OutputValue对象。这个对象包含了在连接中需要使用的值(也可能包含了最终输出的值),和一个标识较大或较小数据集的布尔值。如果map方法可以调用自定义的方法 (generateGroupKey) 来得到可以在连接中使用的键,那么这个键就作为map的输出键。
- protected abstract OptimizedTaggedMapOutput generateTaggedMapOutput(Object value);
-
- protected abstract String generateGroupKey(Object key, OptimizedTaggedMapOutput aRecord);
-
- public void map(Object key, Object value, OutputCollector output, Reporter reporter)
- throws IOException {
-
- OptimizedTaggedMapOutput aRecord = generateTaggedMapOutput(value);
-
- if (aRecord == null) {
- return;
- }
-
- aRecord.setSmaller(smaller);
- String groupKey = generateGroupKey(aRecord);
-
- if (groupKey == null) {
- return;
- }
-
- outputKey.setKey(groupKey);
- output.collect(outputKey, aRecord);
- }
图D.3 说明了map输出的组合键(composite 可以)和组合值。次排序将会根据连接键(join key)进行分区,并用整个组合键来进行排序。组合键包括一个标识源数据集(较大或较小)的整形值,因此可以根据这个整形值来保证较小源数据集的值先于较大源数据的值被reduce接收。
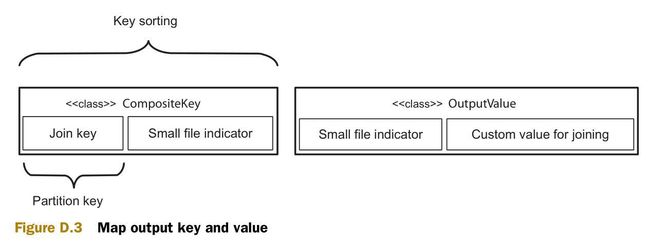
下一步是深入reduce。此前已经可以保证较小源数据集的值将会先于较大源数据集的值被接收。这里就可以将所有的较小源数据集的值放到缓存中。在开始接收较大源数据集的值的时候,就开始和缓存中的值做连接操作。
- public void reduce(Object key, Iterator values, OutputCollector output, Reporter reporter)
- throws IOException {
-
- CompositeKey k = (CompositeKey) key;
- List<OptimizedTaggedMapOutput> smaller = new ArrayList<OptimizedTaggedMapOutput>();
-
- while (values.hasNext()) {
- Object value = values.next();
- OptimizedTaggedMapOutput cloned =((OptimizedTaggedMapOutput) value).clone(job);
-
- if (cloned.isSmaller().get()) {
- smaller.add(cloned);
- } else {
- joinAndCollect(k, smaller, cloned, output, reporter);
- }
- }
- }
方法joinAndCollect包含了两个数据集的值,并输出它们。
- protected abstract OptimizedTaggedMapOutput combine(
- String key,
- OptimizedTaggedMapOutput value1,
- OptimizedTaggedMapOutput value2);
-
- private void joinAndCollect(CompositeKey key,
- List<OptimizedTaggedMapOutput> smaller,
- OptimizedTaggedMapOutput value,
- OutputCollector output,
- Reporter reporter)
- throws IOException {
-
- if (smaller.size() < 1) {
- OptimizedTaggedMapOutput combined = combine(key.getKey(), null, value);
- collect(key, combined, output, reporter);
- } else {
- for (OptimizedTaggedMapOutput small : smaller) {
- OptimizedTaggedMapOutput combined = combine(key.getKey(), small, value);
- collect(key, combined, output, reporter);
- }
- }
- }
这些就是这个框架的主要内容。
原文链接:http://www.cnblogs.com/datacloud/p/3578509.html