字符与字节、字符与编码、字符类型char和wchar_t
最近在编写SMS短信的编码程序,对于字符与编码老是混淆不清,经过查阅一番资料和阅读一些博客,学到了很多知识,其中包括:字符与字节的区别,字符与编码,字符
类型等等。
一,字符与字节
很多刚接触编程的人会和我刚开始的理解差不多,认为一个字符就是一个字节(8)位,其实并不是这样的。字符只是一个代号而已,我打个比方吧,变色龙在不同的地方会显示不一样的颜色,在绿草中是绿色,在沙漠中着成了金黄色,为什么会这样,我也不知道,字符在这里就相当于变色龙,在不同的环境中占的位数肯定也不一样,对于不同的操作系统、不同编译器以及不同的编码方式下可能会呈现出很多种结果,比如在我的32位XP系统VC++软件的Unicode环境中,一个字符是两个字节(16位),而在32位XP系统VC++软件的ANSI环境中,又变成了8位的了。同样的情况,int类型可能为16位也可能为32位。
那么怎样知道我的环境下的字符是几个字节的呢?下面一个小程序可以检测:
#include <iostream.h>
int main()
{
char c = 'A';
unsigned short uc = L'A';
cout<<sizeof(c)<<endl<<sizeof(uc)<<endl;
return 0;
}
二、字符与编码
1、概念:
字符(Character)是文字与符号的总称,包括文字、图形符号、数学符号等。 一组抽象字符的集合就是字符集(Charset)。 字符集常常和一种具体的语言文字对应起来,该文字中的所有字符或者大部分常用字符就构成了该文字的字符集,比如英文字符集。 一组有共同特征的字符也可以组成字符集,比如繁体汉字字符集、日文汉字字符集。 字符集的子集也是字符集。
计算机要处理各种字符,就需要将字符和二进制内码对应起来,这种对应关系就是字符编码(Encoding)。 制定编码首先要确定字符集,并将字符集内的字符排序,然后和二进制数字对应起来。根据字符集内字符的多少,会确定用几个字节来编码。 每种编码都限定了一个明确的字符集合,叫做被编码过的字符集(Coded Character Set),这是字符集的另外一个含义。通常所说的字符集大多是这个含义。
2、字符集种类:ASCII字符集,UCS字符集,GBK18030字符集等等。
3、编码种类:UTF-8、UTF-16、UTF-32
4、和编码有关的词汇:ISO、ANSI、IEC、ASCII、UCS、UTF、Unicode、GB2312、GBK、MBCS、DBCS等等。
5、看到上面这么多的术语,是不是很晕?我在查看资料的时候,也晕头转向,可是经过细致的分析之后,需要知道:哪些是编码机构?哪些是编码方式?哪些是字符集?
具体怎么编码我这里不想讲解,各种方式都可以查到(百度百科,维基百科,MSDN等),我只想从类别上面来区分他们。
1)分类
ISO、ANSI、IEC这三个是定标准的机构,就像IEEE(电气和电子工程协会)一样,它们定下了各种标准;
MBCS(支持多字节字符集)、DBCS(双字节字符集)、UCS(通用字符集)是编码字符集的称谓,
ASCII(美国)、Unicode(统一码,万国码)、GB2312(中国大陆、新加坡)、GBK(同GB2312)是字符集,不同国家的字符集的叫法都不一样;
UTF包括UTF-8、UTF-16、UTF-32,它们是Unicode字符集的编码方案,它们规定了一个字符有几个字节;
2)发展顺序以及包含关系
字符集的 发展顺序:ASCII->Unicode->GBK也就是说最先有了美国的,再有了世界的,再有了各个国家的;
”中国的“字符集的发展顺序:GB-2312->GBK->GB18030;
字符集称谓的顺序:ASCII->MBCS->UCS->DBCS;
3)按照定义,ASCII 字符集是所有多字节字符集的子集。 在许多多字节字符集中,0x00 到 0x7F 范围内的每个字符都与 ASCII 字符集中具有相同值的字符相同。
这里是我收集的一些有关字符编码的资料:
http://www.unicode.org/charts/unihan.html 根据Unicode编码查其对应字符的字形、Utf8、汉字区位码等
http://www.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/GB/GB2312.TXT Unicode与Gb2312的对照表
http://www.sun.com/developers/gadc/technicalpublications/articles/mabiao.txt Unicode与Gbk对照表
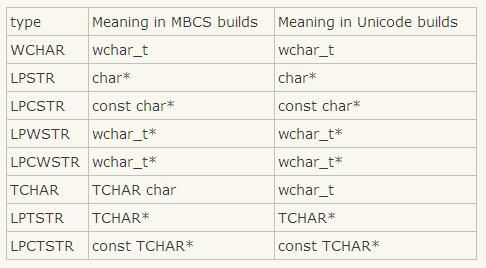
三、字符类型
1、char类型与wchat_t类型
相同点:二者都是C环境下字符的表达方式
不同点:
1)位数:char类型为8位,wchar_t为16位;
2)定义:VC++中的定义#typedef unsigned short wchar_t , 所以wchar_t是短整型,是Unicode字符的数据类型,但是它通常被当做字符的扩充表达方式;
3)称谓:char类型叫标准字符,wchar_t叫宽字符(注意:宽字符不一定是Unicode。Unicode是宽字符集的一种。然而通常我们把宽字符和Unicode作为同义语,因为一般它们都是16位的。);
4)存储:一个char字符占一个存储空间,一个wchar_t占两个存储空间,而且wchar_t的存储要注意的一点是: 因为Intel微处理器从最小的字节开始储存多字节数值,所以’A‘(x0041)实际上是以0x41、0x00的顺序保存在记忆体中,如果检查Unicode文字的电脑储存应注意这一点;
5)处理函数:char类型----strlen、printf等等,wchar_t类型---wcslen、wcsprintf等等;
详细的区别请参考一下:http://blog.csdn.net/dongyonghui_1017/article/details/4280205
http://www.cnblogs.com/fire-phoenix/archive/2010/09/04/1818248.html
http://www.cppblog.com/janvy/archive/2009/06/15/87713.aspx