聚类算法之K-均值聚类
先看一张图(来自集体智慧编程)
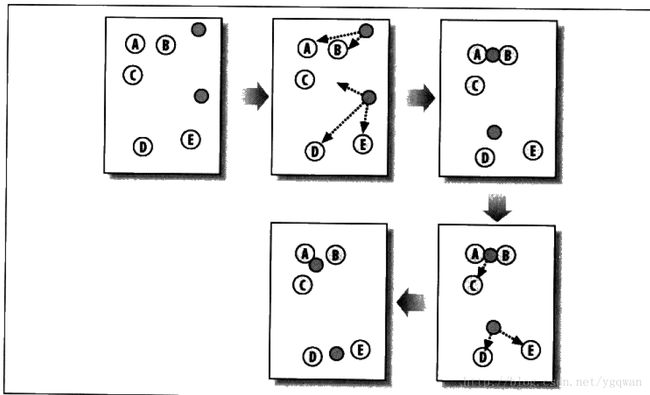
这个算法思路很简单, 就是最开始的时候随便定 k 个点, 然后遍历每一个原图的点, 使得每一个点都归属与那k个点中的一个, 然后更新那k个点的位置(一般是中点)
这个算法是解决当数据太多的时候层次聚类的算法太慢而设计的, 别的优点我就不知道了, 这个算法还可以调节k的大小, 比较方便, 属于人为干预性的, 而层次聚类就是属于自动型的
代码中用到了上一篇文章所提供的数据
import os
import sys
import chardet
from math import sqrt
from PIL import Image, ImageDraw
import random
#coding:utf-8
def readFile(fileName):
lines = [line for line in file(fileName)]
colNames = lines[0].strip().split('\t')[1:]
rowNames = []
data = []
for line in lines[1:]:
p = line.strip().split('\t')
rowNames.append(p[0])
data.append([float(x) for x in p[1:]])
return rowNames, colNames, data
def pearsonBeta(v1, v2):
sum1 = sum(v1)
sum2 = sum(v2)
sum1Sq = sum([pow(v, 2) for v in v1])
sum2Sq = sum([pow(v, 2) for v in v2])
pSum = sum([v1[i] * v2[i] for i in range(len(v1))])
nums = pSum - (sum1 * sum2 / len(v1))
den = sqrt((sum1Sq - pow(sum1, 2) / len(v1)) * (sum2Sq - pow(sum2, 2) / len(v2)))
if(den == 0):
return 0
return 1.0 - nums/den
#距离函数
def pearson(v1, v2):
sum1 = sum(v1)
sum2 = sum(v2)
eSum1 = sum1 / len(v1)
eSum2 = sum2 / len(v2)
pSum = sum([(v1[i] - eSum1) * (v2[i] - eSum2) for i in range(len(v1))])
pTmp1 = sqrt(sum([pow(v1[i] -eSum1, 2) for i in range(len(v1))]))
pTmp2 = sqrt(sum([pow(v2[i] -eSum2, 2) for i in range(len(v2))]))
pSqrtSum = pTmp1 * pTmp2
if pSqrtSum == 0:
return 0
return 1 - pSum / pSqrtSum
class bicluster:
def __init__(self, vec, left = None, right = None, distance = 0.0, id = None):
self.vec = vec
self.left = left
self.right = right
self.distance = distance
self.id = id
def vis(self):
print self.vec
#层次聚类
def hCluster(rows, distanceFunc = pearson):
distances = {}
currentClustId = -1
clust = [bicluster(rows[i], id = i) for i in range(len(rows))]
while len(clust) > 1:
lowestPair = (0, 1)
closest = distanceFunc(clust[0].vec, clust[1].vec)
for i in range(len(clust)):
for j in range(i + 1, len(clust)):
if(clust[i].id, clust[j].id) not in distances:
distances[(clust[i].id, clust[j].id)] = distanceFunc(clust[i].vec, clust[j].vec)
d = distances[(clust[i].id, clust[j].id)] #直接写成i,j了, 真是找了我半天
if d < closest:
closest = d
lowestPair = (i, j)
mergevec = [(clust[lowestPair[0]].vec[i] + clust[lowestPair[1]].vec[i]) / 2.0 for i in range(len(clust[lowestPair[0]].vec))]
newCluster = bicluster(mergevec, clust[lowestPair[0]], clust[lowestPair[1]], closest, currentClustId)
currentClustId -= 1
del clust[lowestPair[1]] #must first del 1, then 0
del clust[lowestPair[0]]
clust.append(newCluster)
return clust[0]
#k-均值聚类
def kcluster(rows, distanceFunc = pearson, k = 5):
ranges = [(min(row[i] for row in rows), max(row[i] for row in rows)) for i in range(len(rows[0]))]
clusters = [[random.random() * (ranges[i][1] - ranges[i][0]) + ranges[i][0] for i in range(len(rows[0]))] for j in range(k)]
bestMatches = None
for t in range(100):
print "iter is: %d" %(t)
lastMatches = [[] for i in range(k)]
for i in range(len(rows)):
row = rows[i]
lastMatch = 0
for j in range(k):
d = distanceFunc(clusters[j], row)
if d < distanceFunc(rows[lastMatch], row):
lastMatch = j
lastMatches[lastMatch].append(i)
if lastMatches == bestMatches:
break;
bestMatches = lastMatches
#move center
for i in range(k):
if len(bestMatches[i]) > 0:
newRow = []
for j in range(len(rows[0])):
sum = 0
for v in range(len(bestMatches[i])):
sum += rows[v][j]
newRow.append(sum)
for j in range(len(newRow)):
newRow[j] = newRow[j] / len(bestMatches[i])
clusters[i] = newRow
return bestMatches
#以缩进方式打印层次聚类的树
def printClust(clust, labels = None, n = 0):
for i in range(n):print ' ',
if clust.id < 0:
print '-'
else:
if labels == None:
print clust.id
else:
print labels[clust.id]
if clust.left != None:
printClust(clust.left, labels = labels, n = n + 1)
if clust.right != None:
printClust(clust.right, labels = labels, n = n + 1)
def getHeight(clust):
if clust.left == None and clust.right == None:
return 1
return getHeight(clust.left) + getHeight(clust.right)
def getDepth(clust):
if clust.left == None and clust.right == None:
return 1
return max(getDepth(clust.left), getDepth(clust.right)) + clust.distance
def drawnode(draw, clust, x, y, scaling, labels):
if clust.id < 0:
h1 = getHeight(clust.left) * 20
h2 = getHeight(clust.right) * 20
top = y - (h1 + h2) / 2
bottom = y + (h1 + h2) / 2
li = clust.distance * scaling
draw.line((x, top + h1/2, x, bottom - h2/2), fill = (255, 0, 0))
draw.line((x, top + h1/2, x + li, top + h1/2), fill = (255, 0, 0))
draw.line((x ,bottom - h2/2, x + li, bottom - h2/2), fill = (255, 0, 0))
drawnode(draw, clust.left, x + li, top + h1/2, scaling, labels)
drawnode(draw, clust.right, x + li, bottom - h2/2, scaling, labels)
else:
draw.text((x + 5, y - 7), labels[clust.id], (0, 0, 0))
#以属性结构打印层次聚类的关系
def drawdendrogram(clust, labels, jpeg = "clusters.jpg"):
h = getHeight(clust) * 20
w = 1200
depth = getDepth(clust)
scaling = float(w - 150) / depth
img = Image.new("RGB", (w, h), (255, 255, 255))
draw = ImageDraw.Draw(img)
draw.line((0, h/2, 10, h/2), fill = (255, 0, 0))
drawnode(draw, clust, 10, (h/2), scaling, labels)
img.save(jpeg, "JPEG")
(rowNames, colNames, data) = readFile("F:\\py\\dataFetch\\julei\\data\\blogdata.txt")
print kcluster(data)
#cluster = hCluster(data, distanceFunc = pearsonBeta)
#drawdendrogram(cluster, rowNames)