中文分词---2011-10-25 22:42 Lucene分词实现(二次开发流程)
转自:http://hi.baidu.com/zhumulangma/item/fcb2851542a2b924f7625c32
1.1 分词流程
在Lucene3.0中,对分词主要依靠Analyzer类解析实现。Analyzer内部主要通过TokenStream类实现。Tonkenizer类、TokenFilter类是TokenStream的两个子类。Tokenizer处理单个字符组成的字符流,读取Reader对象中的数据,处理后转换成词汇单元。TokneFilter完成文本过滤器的功能,但在使用过程中必须注意不同的过滤器的使用的顺序。
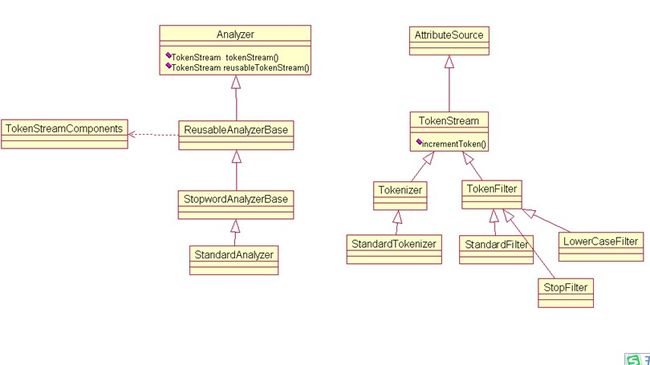
1.2 分词扩展具体流程
1.2.1 Analyzer类分析
(1)所有的分词器都需要继承于Analyzer抽象类,它定义了tokenStream抽象方法。
public abstract class Analyzer {
public abstract TokenStream tokenStream(String fieldName, Reader reader);
public TokenStream reusableTokenStream(String fieldName, Reader reader){}
}
该抽象类规定了Analyzer需要实现的一些方法。
(2)public abstract TokenStream tokenStream(String fieldName, Reader reader);
该方法需要自定义的分词器去实现,并返回TokenStream,即将对象以Reader的方式输入分词为fieldName字段。
TokenStream:分词流,即将对象分词后所得的Token在内存中以流的方式存在,也说是说如果在取得Token必须从TokenStream中获取,而分词对象可以是文档文本,也可以是查询文本。
参数说明:
fieldName——字段名,也就是你建索引的时候对应的字段名,比如:Field f = new Field("title","hello",Field.Store.YES, Field.Index.TOKENIZED);这句中的"title";
reader——java.io.Reader对象;
(3)public TokenStream reusableTokenStream(String fieldName, Reader reader)。设置为可复用TokenStream,将同一线程中前面时间的TokenStream设置为可复用。那些无必要同一时刻使用多个TokenStream的调用者使用这个方法,可以提升性能。
(4)接着,在tokenStream()方法实现中使用Tonkenizer和TokenFilter,例如StandardAnalyzer类中的tokenStream实现:
TokenStream result = new StandardTokenizer(reader);//表示用StandardTokenizer对这个要分词的reader进行处理,然后返回一个TokenStream对象
result = new StandardFilter(result);//表示对生成的TokenStream对象进行标准过滤(Filter)
result = new LowerCaseFilter(result);//表示对上面由"StandardFilter"过滤后的TokenStream对象再进行次过滤,转化为小写
result = new StopFilter(result, stopSet);//接下来再进行次过滤,去掉停止词
5return result;//得到最终结果
由此可以看出,主要的分词环节是Tokenizer类执行,而Filter负责数据的预处理和分词后处理且数量不限。
1.2.2 TokenStream类分析
TokenStream是一个抽象类,枚举词序列,要么是从一个文档的域得来,要么是从一个查询文本中得到。主要任务有:
(1)获取下一Token;
(2)重设流(可选);
(3)关闭流,释放资源;
public Token next();//取得词序列中的下一个词
public Token next(final Token reusableToken);//输入可复用的Token,作为初始参数,可以返回一个新的Token
public void reset();
public void close();
在Lucene3以后,next方法改为了incrementToken,并增加了end方法。
public abstract boolean incrementToken() throws IOException;
public void end() throws IOException;
1.2.3 Tokenizer类分析
Tokenizer类是继承于TokenStream的一个抽象类,是一个输入为Reader的TokenStream。
其职责是:
(1)接收输入流并根据输入流进行词切分。
因此,该类是定制分词器的核心之一。
publicabstractclass Tokenizer extends TokenStream {
protected Reader input;//增加了输入流Reader
protected Tokenizer() {}
protected Tokenizer(Reader input) {
this.input = input;
}
publicvoid close() throws IOException {
input.close();
}
/**设置input到一个新的Reader*/
publicvoid reset(Reader input) throws IOException {
this.input = input;
}
}
在Tokenizer类中,核心的方法是next方法,以CharTokenizer为例。
publicfinal Token next(final Token reusableToken) throws IOException {
assert reusableToken != null;
reusableToken.clear();
int length = 0;
int start = bufferIndex;//起始位置
char[] buffer = reusableToken.termBuffer();
while (true) {
if (bufferIndex >= dataLen) {//如果缓冲取大于数据长度,再读取到缓冲区
offset += dataLen;
dataLen = input.read(ioBuffer);
if (dataLen == -1) {
if (length > 0)
break;
else
returnnull;
}
= 0;
}
finalchar c = ioBuffer[bufferIndex++];//无论如何都取一个字符
if (isTokenChar(c)) {// if it's a token char
if (length == 0) // start of token
start = offset + bufferIndex - 1;
elseif (length == buffer.length)
buffer = reusableToken.resizeTermBuffer(1+length);
buffer[length++] = normalize(c); // buffer it, normalized
if (length == MAX_WORD_LEN) // buffer overflow!
break;
} elseif (length > 0) // at non-Letter w/ chars
break; // return 'em
}
reusableToken.setTermLength(length);
reusableToken.setStartOffset(start);
reusableToken.setEndOffset(start+length);
return reusableToken;
}
1.2.4 TokenFilter类分析TokenFilter类继承于TokenStream,其输入是另一个TokenStream,主要职责是对TokenStream进行过滤,例如去掉一些索引词、替代同义索引词等操作。
1.2.5 Token类分析
(1)Token属性
lucene里定义了几种基本属性:
1)TermAttribute:表示token的字符串信息。比如"I'm";
2)TypeAttribute:表示token词典类别信息,默认为“Word”,比如I'm就属于<APOSTROPHE>,有撇号的类型;
3)OffsetAttribute:表示token的首字母和尾字母在原文本中的位置。比如I'm的位置信息就是(0,3),需要注意的是startOffset与endOffset的差值并不一定就是termText.length(),因为可能term已经用stemmer或者其他过滤器处理过;
4)PositionIncrementAttribute:这个有点特殊,它表示tokenStream中的当前token与前一个token在实际的原文本中相隔的词语数量,用于短语查询。比如: 在tokenStream中[2:a]的前一个token是[1:I'm ],它们在原文本中相隔的词语数是1,则token="a"的PositionIncrementAttribute值为1;
5)PayloadAttribute,payload即负载量意思,是每个term出现一次则存储一次的元数据,它存储于特定term的posting list内部。
6)FlagsAttribute,用于在Tokenizer链之前传递标记(因为前面一个操作可能会影响后面的操作)。
那么这个属性有什么用呢,用处很大的。加入我们想搜索一个短语student apples(假如有这个短语)。很显然,用户是要搜索出student apples紧挨着出现的文档。这个时候我们找到了某一篇文档(比如上面例子的字符串)都含有student apples。但是由于apples的PositionIncrementAttribute值是5,说明肯定没有紧挨着。
(2)核心方法
前面几个属性都作为其成员变量。
l set、get方法
l hashCode方法
(为什么要HASH?便于另一种方式去映射,常用的HASH算法有哪些?)
其典型的hash代码是code = code * 31 + startOffset,
l copyTo方法
复制到另一个AttributeImpl中。
l reflectWith方法
属性反射,从Token对象中解析得出属性。