汉字转拼音小程序——Python版
首先说明,我不是计算机专业的!我是学油藏工程的(石油工程专业方向之一),大学毕业后一直从事石油开发地质专业的工作。石油领域内前期的地震资料处理,中期的开发地质研究,以及后期的油藏数值模拟和动态分析都需要处理大量的数据,当然石油工程中再后期,就是采油工程和储运工程等方面了,这些不需要处理大量数据。钻井工程贯穿于整个油田开发过程,无论是什么阶段,都需要钻井,当然钻井的数据分析量相对也小一些。这里我要说明的是,我做的工作主要针对的是石油开发地质(油藏建模领域)。
就在这个周末,有个朋友做油藏建模工作(油藏建模其实就是利用各种数据,把地下模型通过计算机软件反映出来,帮助分析地下油藏分布情况),在建模的过程中,他所使用的建模软件是不认识中文字符的(目前主流的油藏建模软件都是国外的),所以就面临一个整理数据的问题,数据量很大,有两千多个文件。(这里说的是井的资料,在东部油田,井很多,一个区块有上千口井很正常,每口井都会有测井资料,其实就是一个很大的文本文件)
拿一个文件举例,文件名为“西1-8-1.las”,这是油田上经常用的一种标准格式,我们称为las文件(扩展名为las,音:辣斯),用普通的文本编辑器可以打开,如下图:

数据处理的要求很简单,就是把文件按的名字和文件内的汉字,转换为拼音并只保留首字母,而且是大写的。
也就是说,处理后文件名应为“X1-8-1.las”,文件的内容应该如下图:
其实每个文件需要修改的地方就这么一点点,可是由于文件数目太多,所以我利用Python,写了一个自动转换的工具。当然由于大部分人都是在Windows系统上操作,所以我在调用系统命令的时候,完全采用的是DOs命令方式。
首先,针对一个文件,写了一个文件,名称为convert.py
内容如下:
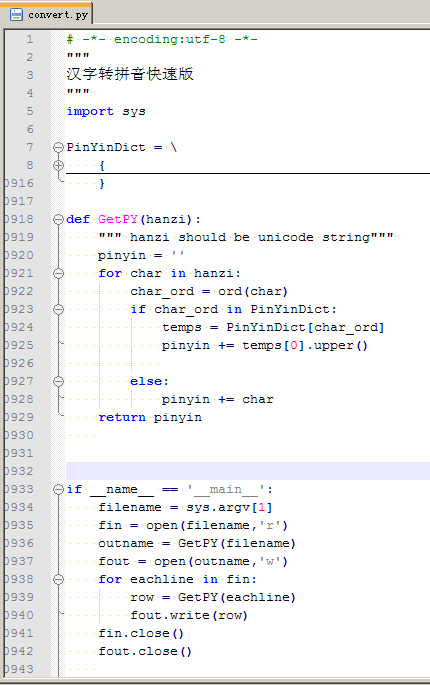
这个文件中,从第7行开始到第20916行(常用汉字2W多个,生僻字在这里不太管用了),就是一个Python的字典,其实就是一个哈希表,键值是Unicode码,键值对应的内容就是汉字的拼音,如下:
…………………………
文件中的其余部分就是读取参数(参数是las文件名),然后在文件中按照每行读取,然后每读取一行,就在一行中寻找汉字,并替换为拼音的第一个字母并大写。
这个文件搞定后,就开始写另一个脚本,名为search.py,这个脚本是专门用于搜索当前文件夹中给定扩展名的文件,如下:

这个文件就是读取扩展名,然后把搜索到的文件名放入一个名为tempfile的文件中。
最后就是写一个自动生成批处理文件的脚本,如下:
运行后,会自动生成run.bat文件,然后双击run.bat就能进行批处理了。
前提条件:机子上安装了Python3.1版本,且安装路径为默认路径(在Windows上,Python都安装在系统盘根目录下,默认为C:/Python31)
我们来看个例子,我们用两个文件举例。假如我们要修改2个las文件,那么首先我把这个2个las文件放置到一个文件夹中(文件夹名称为英文字母,无空格):

第一步,将三个脚本文件复制到这个文件夹:
首先双击search.py,要求输入搜索文件的扩展名,输入las,运行后会出现一个tempfile文件,用文本编辑器打开,可以看到就是一个文件列表,如下:
其次,双击run.py,这个时候就会生成一个run.bat的批处理文件:

批处理文件的内容很简单,如下:

最后,双击运行这个run.bat就可以了,会自动生成我们想要的文件:

生成的文件名字得到了我们想要的结果,打开文件,内部也是我们想要的结果,如图:
有的朋友可能担心有些汉字的音同字不同,这样就会产生相同的结果了,其实这个问题可以不必担心,油田在钻井过程中,为每口井命名都是有一定规律的,不会出现这种情况。
这里主要为了阐述,Python3.0以后的版本全部是Unicode字符,所以对中文的处理还是比较方便的。