函数式编程
http://coolshell.cn/articles/10822.html
详细内容请移步到上述的链接
这里只是补充
http://www.pythoner.com/46.html
1.map()
格式:map( func, seq1[, seq2...] )
Python函数式编程中的map()函数是将func作用于seq中的每一个元素,并用一个列表给出返回值。如果func为None,作用同zip()。
当seq只有一个时,将func函数作用于这个seq的每个元素上,得到一个新的seq。下图说明了只有一个seq的时候map()函数是如何工作的(本文图片来源:《Core Python Programming (2nd edition)》)。

可以看出,seq中的每个元素都经过了func函数的作用,得到了func(seq[n])组成的列表。
下面举一个例子进行说明。假设我们想要得到一个列表中数字%3的余数,那么可以写成下面的代码。
# 使用map print map( lambda x: x%3, range(6) ) # [0, 1, 2, 0, 1, 2] #使用列表解析 print [x%3 for x in range(6)] # [0, 1, 2, 0, 1, 2]
这里又和上次的filter()一样,使用了列表解析的方法代替map执行。那么,什么时候是列表解析无法代替map的呢?
原来,当seq多于一个时,map可以并行地对每个seq执行如下图所示的过程:
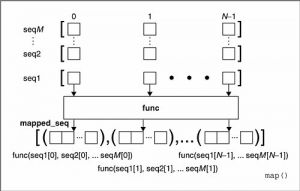
也就是说每个seq的同一位置的元素在执行过一个多元的func函数之后,得到一个返回值,这些返回值放在一个结果列表中。
下面的例子是求两个列表对应元素的积,可以想象,这是一种可能会经常出现的状况,而如果不是用map的话,就要使用一个for循环,依次对每个位置执行该函数。
print map( lambda x, y: x * y, [1, 2, 3], [4, 5, 6] ) # [4, 10, 18]
上面是返回值是一个值的情况,实际上也可以是一个元组。下面的代码不止实现了乘法,也实现了加法,并把积与和放在一个元组中。
print map( lambda x, y: ( x * y, x + y), [1, 2, 3], [4, 5, 6] ) # [(4, 5), (10, 7), (18, 9)]
还有就是上面说的func是None的情况,它的目的是将多个列表相同位置的元素归并到一个元组,在现在已经有了专用的函数zip()了。
print map( None, [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)]
print zip( [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)]
需要注意的是,不同长度的多个seq是无法执行map函数的,会出现类型错误。
2.reduce()
格式:reduce( func, seq[, init] )
reduce函数即为化简,它是这样一个过程:每次迭代,将上一次的迭代结果(第一次时为init的元素,如没有init则为seq的第一个元素)与下一个元素一同执行一个二元的func函数。在reduce函数中,init是可选的,如果使用,则作为第一次迭代的第一个元素使用。
简单来说,可以用这样一个形象化的式子来说明:
reduce( func, [1, 2,3] ) = func( func(1, 2), 3)
下面是reduce函数的工作过程图:
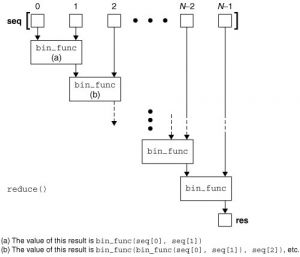
举个例子来说,阶乘是一个常见的数学方法,Python中并没有给出一个阶乘的内建函数,我们可以使用reduce实现一个阶乘的代码。
n = 5
print reduce(lambda x, y: x * y, range(1, n + 1)) # 120
那么,如果我们希望得到2倍阶乘的值呢?这就可以用到init这个可选参数了。
m = 2
n = 5
print reduce( lambda x, y: x * y, range( 1, n + 1 ), m ) # 240
reduce如果在序列之后还有参数,比如序列是[f1,f2,f3],其之后还有一个参数g,就可以看做序列是[g,f1,f2,f3]
下面是coolshell的一个例子
def even_filter(nums):
return filter(lambda x: x%2==0, nums)
def multiply_by_three(nums):
return map(lambda x: x*3, nums)
def convert_to_string(nums):
return map(lambda x: 'The Number: %s' % x, nums)
nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
pipeline = convert_to_string(
multiply_by_three(
even_filter(nums)
)
)
for num in pipeline:
print num
但是他们的代码需要嵌套使用函数,这个有点不爽,如果我们能像下面这个样子就好了(第二种方式)。
pipeline_func(nums, [even_filter,
multiply_by_three,
convert_to_string])
那么,pipeline_func 实现如下:
def
pipeline_func(data, fns):
return
reduce
(
lambda
a, x: x(a),
fns,
data)
本来reduce处理的序列是
[even_filter,
multiply_by_three,
convert_to_string]
[data,even_filter,
multiply_by_three,
convert_to_string]
偏函数是从Python2.5引入的一个概念,通过functools模块被用户调用。
偏函数是将所要承载的函数作为partial()函数的第一个参数,原函数的各个参数依次作为partial()函数后续的参数,除非使用关键字参数。
通过语言描述可能无法理解偏函数是怎么使用的,那么就举一个常见的例子来说明。在这个例子里,我们实现了一个取余函数,对于整数100,取得对于不同数m的100%m的余数。
from functools import partial def mod( n, m ): return n % m mod_by_100 = partial( mod, 100 ) print mod( 100, 7 ) # 2 print mod_by_100( 7 ) # 2
注意,这里的参数100对应的是n
print mod1()
由于之前看到的例子一般选择加法或乘法来讲解,无法体会偏函数参数的位置问题,容易给人造成partial的第二个参数也是原函数的第二个参数的假象,所以我在这里选择mod来讲解。
而对于有关键字参数的情况下,就可以不按照原函数的参数位置和个数了。下面再看一个例子,讲的是如何进行不同的进制转换。
from functools import partial bin2dec = partial( int, base=2 ) print bin2dec( '0b10001' ) # 17 print bin2dec( '10001' ) # 17 hex2dec = partial( int, base=16 ) print hex2dec( '0x67' ) # 103 print hex2dec( '67' ) # 103
函数式编程的思想是这样的,一个函数可能需要两个以上的参数,通过partial函数将这个函数的部分参数赋值,这样就包装生成了一个新的函数,对于这个新函数,只需要再传入剩下的值,就可以得到结果了
def inc(x):
def incx(y):
print 'x=%d' %x
print 'y=%d' %y
return x+y
return incx;
inc2 = inc(2)
print inc2(5)
注意inc2是一个函数,就是对incx的封装,incx需要两个参数,x,y。但是inc2中x已经有值了为2,所以inc2(5)就是再传入y的值