论文读书笔记-topic correlation and individual influenceanalysis in online forums
标题:topic correlation and individual influenceanalysis in online forums翻译成中文就是在线论坛中话题关联和个体影响分析。
1-简介
通过观察发现,新出现的话题和之前存在的话题存在相似特征。为了解释和理解文本中话题的关联性,可以来寻找话题之间的语义相似性和社会联系(参与者联系)。当出现以下情况时,我们假定这两个主题是有关联的:
相同的关键词
参与者联系(某个帖子参与者和另一个帖子参与者存在联系),又可细分为:发帖者相同;帖子2的发帖者回应了帖子1,;有共同的回复者
2-话题检测
语义相似性估计,首先把话题分割为关键词;其次计算话题直接的相似性。最终一个文本被表示成关键词组成的特征向量,然后可以使用TF-IDF方法计算关键词权重,再通过余弦定理计算两个话题的相似性:

Cwi(p1)是表示第i个相同的关键词在话题p1中的权重,wi(p)是第i个关键词在话题p1中的权重
通过这样的运算后,该问题就转换为一个图聚类问题,这时可以采用LPA算法(一种本地化的群体检测方法)实现:


该算法的时间复杂度为O(n)
3-话题关联分析
为了检测出良好定义的话题之间的关系,我们采用互信息来进行运算,该信息是用来度量不同变量之间的依赖性:

这里我们考虑两个因素影响两个话题之间的依赖程度,一个是语义的联系;一个是社会参与者的联系。我们假定拥有相似关键词或者联系紧密的社会参与者回复的帖子之间存在较大的关联性,而那些随意创建的帖子之间的关联性较小。话题a和话题b存在联系,如果关键词相同超过一定程度,或者两个话题之间的社会参与者联系紧密。
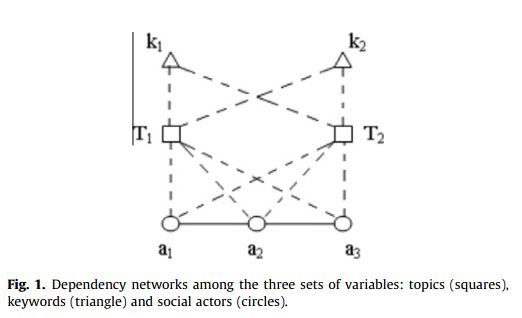
这幅图表明,三个社会参与者联系在一起,两个话题有相同的关键词联系,两个主题之间的联系可以如下表示:
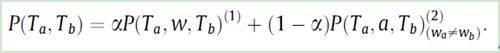
第一项定义了两个话题拥有相同关键词的概率,第二项定义了两个话题拥有紧密联系社会参与者的可能性。下面分别列出计算过程:
相同的关键词:

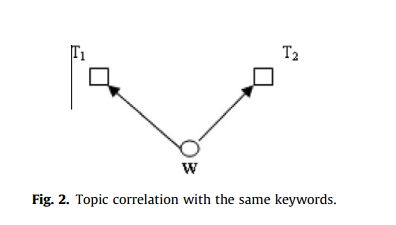
相同的主题参与者:

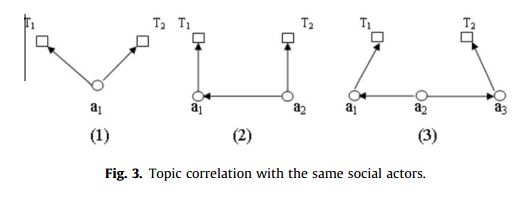
上面分别对应有相同的发帖者;帖子T2由a2创建,同时a2回应了a1创建的帖子T1;a2回应了a1,a3创建的帖子。
最后通过采用贝叶斯方法,我们可以对公式进行变形:
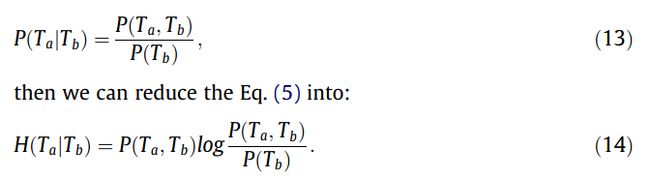
然后通过设定三个Num参数,使用概率估计算法得到:
Num(Ti,wk)表明话题i中含有关键词k的个数
Num(j,j’)表明j’回应j的次数
Num(Ti,j,j’)表明j’在话题i中回应j的次数
通过以上这些工作,我们不仅能发现话题的关联性,也能从中找到意见领袖计算P(a|Ta,Tb)即可