说起互联网、电商的数据分析,更多的是谈应用案例,如何去实践数据化管理运营。而这里,我们要从技术角度分享关于数据的技术架构干货,如何应用BI。
原文是云猴网BI总经理王卫东在帆软大数据上的演讲,以下是整理的文字稿。
在电商领域,我们一般认为所有的数据都可以分为四大类型,流量、销量、商品和会员,这也是最基础的报表需求。
流量部分,可以分为受访、点击、搜索、来源等等。这些流量信息运用的重点在于一些广告包括一些产品的改版以及搜索引擎的相关信息展示。虽然这方面百度、GA可以给你提供这方面的信息,但未必能完成一个企业的所有需求。
销量部分,会分为销售、补贴、渠道、支付、地域等等。但对于这些信息,领导更关注流量有多少,销量有多少,然后投入是多少,哪个渠道带来的销量是最多的,转化率是最高的,目标客户重点在什么区域。但是对于我们的实际运营,我们还要继续往下细钻,需要对商品和会员的信息挖掘得更加细致。
商品部分,会涉及到的品类、库存、毛利、动销和转化,一般电商商品的品类大多会分为三级,但也会往下细分到四级,他需要细化到每个品类的转化率,哪个更高?以及在每一个品类里面哪一个商品的动销率最高,哪种的商品的转化率是最高,因为你需要实时调整和改变。对于会员来讲,还要了解其注册情况、复购情况、活跃度以及喜好和流失等等。所有的这些就构成了我们的常规基础报表。
关于BI,包含3个阶段。第一阶段是常规的报表阶段,第二阶段是数据分析,这里的数据分析并不是现有数据的陈述,那是历史数据没有太大意义,不能帮助预测。而数据的价值恰恰在于预测而不是陈述,所以这些信息我们会用来风控。
在电商领域会有这样几个风控需求,流量异常,转化异常和订单异常。那这样的风控是怎么做的呢?比如流量异常,加入我们设定的日常流量是30万的PV,某天突然间小于30万了,那就可以设一个阈值说我的流量小于30万了,这个称之为预警。
然后讲一下统计学上的一些操作。第一种称之为UCL,在统计学里面称之为质量控制图。在这个图里,所有的流量都含有一定的趋势,可以去判断一个数据的出错,与历史信息产生的异常。一般来讲,产生的绝大多数数据会满足质量分布,98%的数据所处的范围区间会在均值加上两倍标准差的概率之内。为什么要做这样一个模型呢?以前我们没有运用这个模型之前,运营部门经常会跟老板报告这一天流量、销量是多少,当问及为什么下降的时候无从解释,数据是否超出了可控范围无从知晓。有了这样一个模型就很好解决了。
风控之后还有其他需求比如用户画像-推荐。用户画像是基本投放的前提条件,只有先做用户画像才能有推荐系统。推荐系统之外还有一个底价系统,底价系统是用来监控对方的价格数据以及提取商品卖点。
所有这些之后,如果要建设一个BI系统,该如何选型呢?免费?收费?还是自建?这里据一些实际例子,做个对比。
- 免费统计
比如免费的流量统计,百度、GA都是免费的统计工具,接入很快,埋入代码就行,但是无法联通H5,APP,数据也不能连入数据库。其次,免费的工具无法解决销量会员商品数据问题,处于企业自身数据安全的问题,包括企业的BI系统,外网是无法访问的。
其次,广告渠道的数据不准确,他的统计一定虚高,所以这一块需要第三方的参照。而且每家计算标准不一,数据差异大。
- 收费平台
收费平台介入快,成本相对较低,但数据的私密性较差,多数据源的聚合有难度,每一个端口的唯一识别问题很难去定义。自定义程度也不高,因为它是做通用化的,行业细化不够,沟通成本较高。
- 自建平台
最大的有点在于自定义程度高,数据更为精细,可以为多数据的聚合和钻取,但缺点就在于建设周期长,人才很难找。
选型建议
这也是我们为什么找帆软这个企业来做第三方的工具,因为相关人员的成本很高,所以这方面工具的选型建议找专业的来做。避免被业务人员的需求带着跑,而是利用工具去引导。
其次,我们一直认为数据的实时性和准确性很重要,用于风控和预测,而帆软报表FineReport的自定义程度可以让非专业人员也能着手做。最后一点,数据的可视化采用编程代价最小,这一点FineReport在数据可视化方面是很不错的。
系统架构
这是目前我们公司的系统架构
首先是两个数据,用户行为数据和业务数据。商品会员交易库存这一方面是业务数据,这些业务数据多数存储在my sql数据库里。埋点系统里的渠道数据分为两端,PC和H5的采集很简单,用脚本组件进行采集,这是通用的。但App就需要打制组件。
拿到数据以后会往flume里面去,到flume里直接取到之后,上面会搭一层队列,因为如果单纯依靠flume的话,系统会卡死,因为flume经常出现卡顿现象,也就是说你去控制他的一些监控脚本的话也是没意义的,因为有时候他的内存卡住了,资源占用,他依然在那动。所以搭建这个队列有个好处,第一,走的是消费者模式;第二,里面有位置信息,一旦出现数据错乱可以回补。
这些数据,我们首先要满足实时性问题,我们采用的是ES。利用ES做实时查询能解决很多问题,这也是我们原来做大数据的时候经常说给到对方企业采购时,你会发现前期没问题,但越做到后面我们一直说做数据仓要分主题,包括说做Cube之类的,这些都没有意义,当数据量达到一定层级以后,依然很慢。
然后是我们的BI系统。所有BI系统都是在展现层和应用层,展现层可以选择FineReport、echart、excel,这个根据企业的情况去定义。但如果企业没有专业的人员, FineReport是你最好的选择,如果用别的话,后期维护成本很高。在BI系统里面不光是做展示你还需要做接口的,这个信息设施需要做接口推送给第三方,包括PC、H5、微信的应用,都是从这个系统里出去的,能实现聚合一个企业的所有数据,在一个系统里面进行展示。
应用案例
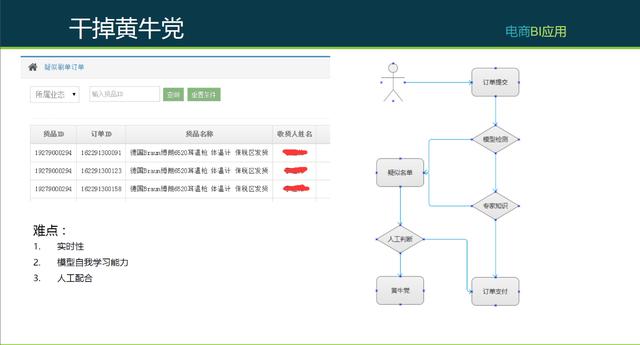
电商里面存在很多黄牛党的事儿。但我们做活动的目的是让用户享受到实惠,所以在提交订单的时候会有一个过程,并不是立即审核通过的,但这个过程必须很短,要考虑到订单转化的问题。如下图,左边是后台系统的展示,这是疑似刷单名单的截图展示。流程是这样的,用户提交完订单以后,会有一个模型检测,这个模型检测是纯机器,从模型检测再到专家知识。如果在模型检测中符合会到名单里去,否则会进入到专家支持,专家支持完了以后如果认为是正常订单,才能到支付阶段,否则的话都会到疑似名单,到时候再人工判断。