分析
当频繁full gc时,jstack打印出堆栈信息如下:sudo -u admin -H /opt/taobao/java/bin/jstack `pgrep java` > #your file path#可以看到的确是在跑低价信息另外在应用频繁full gc时和应用正常时,也执行了如下2种命令:sudo -u admin -H /opt/taobao/java/bin/jmap -histo `pgrep` > #your file path#sudo -u admin -H /opt/taobao/java/bin/jmap -histo:live `pgrep` > #your file path#(live会产生full gc)目的是确认以下2种信息:(1)是否存在某些引用的不正常,造成对象始终可达而无法回收(Java中的内存泄漏)(2)是否真是由于在频繁full gc时同时又有大量请求进入分配内存从而处理不过来,
造成concurrent mode failure?下图是在应用正常情况下,jmap不加live,产生的histo信息: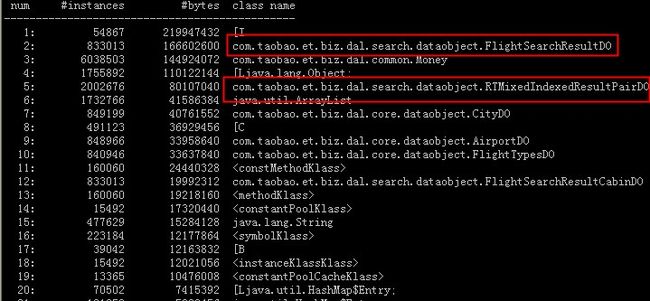
下图是在应用正常情况下,jmap加live,产生的histo信息: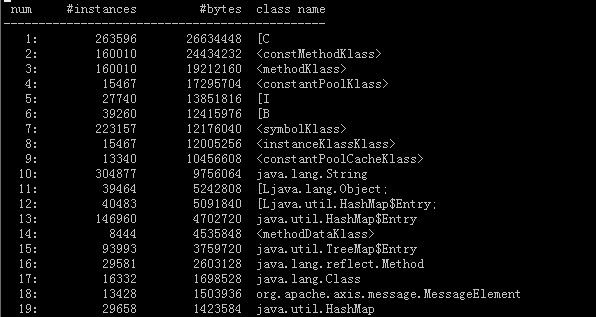
下图是在应用频繁full gc情况下,jmap不加live和加live,产生的histo信息: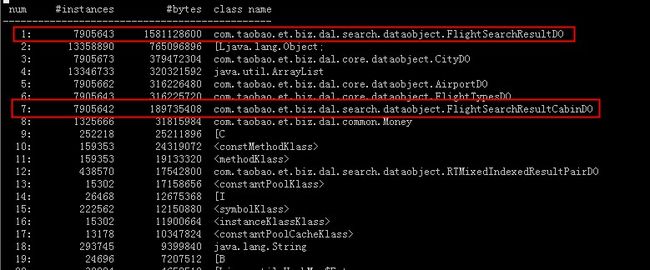
从上述几个图中可以看到:(1)在应用正常情况下,图中标红的对象是被回收的,因此不是内存泄漏问题(2)在应用频繁full gc时,标红的对象即使加live也是未被回收的,因上就是在频繁full gc时,
同时又有大量请求进入分配内存从而处理不过来的问题先从解决问题的角度,看怎样造成频繁的full gc?
从分析CMS GC开始
先给个CMS GC的概况:(1)young gc可以看到,当eden满时,young gc使用的是ParNew收集器ParNew: 2230361K->129028K(2403008K), 0.2363650 secs解释:1)2230361K->129028K,指回收前后eden+s1(或s2)大小2)2403008K,指可用的young代的大小,即eden+s1(或s2)3)0.2363650 secs,指消耗时间2324774K->223451K(3975872K), 0.2366810 sec解释:1)2335109K->140198K,指整个堆大小的变化
(heap=(young+old)+perm;young=eden+s1+s2;s1=s2=young/(survivor ratio+2))2)0.2366810 sec,指消耗时间[Times: user=0.60 sys=0.02, real=0.24 secs]解释:指用户时间,系统时间,真实时间
(2)cms gc当使用CMS收集器时,当开始进行收集时,old代的收集过程如下所示:a)首先jvm根据-XX:CMSInitiatingOccupancyFraction,-XX:+UseCMSInitiatingOccupancyOnly
来决定什么时间开始垃圾收集b)如果设置了-XX:+UseCMSInitiatingOccupancyOnly,那么只有当old代占用确实达到了
-XX:CMSInitiatingOccupancyFraction参数所设定的比例时才会触发cms gcc)如果没有设置-XX:+UseCMSInitiatingOccupancyOnly,那么系统会根据统计数据自行决定什么时候
触发cms gc;因此有时会遇到设置了80%比例才cms gc,但是50%时就已经触发了,就是因为这个参数
没有设置的原因d)当cms gc开始时,首先的阶段是CMS-initial-mark,此阶段是初始标记阶段,是stop the world阶段,
因此此阶段标记的对象只是从root集最直接可达的对象CMS-initial-mark:961330K(1572864K),指标记时,old代的已用空间和总空间e)下一个阶段是CMS-concurrent-mark,此阶段是和应用线程并发执行的,所谓并发收集器指的就是这个,
主要作用是标记可达的对象此阶段会打印2条日志:CMS-concurrent-mark-start,CMS-concurrent-markf)下一个阶段是CMS-concurrent-preclean,此阶段主要是进行一些预清理,因为标记和应用线程是并发执行的,
因此会有些对象的状态在标记后会改变,此阶段正是解决这个问题因为之后的Rescan阶段也会stop the world,为了使暂停的时间尽可能的小,也需要preclean阶段先做一部分
工作以节省时间此阶段会打印2条日志:CMS-concurrent-preclean-start,CMS-concurrent-precleang)下一阶段是CMS-concurrent-abortable-preclean阶段,加入此阶段的目的是使cms gc更加可控一些,
作用也是执行一些预清理,以减少Rescan阶段造成应用暂停的时间此阶段涉及几个参数:-XX:CMSMaxAbortablePrecleanTime:当abortable-preclean阶段执行达到这个时间时才会结束-XX:CMSScheduleRemarkEdenSizeThreshold(默认2m):控制abortable-preclean阶段什么时候开始执行, 即当eden使用达到此值时,才会开始abortable-preclean阶段-XX:CMSScheduleRemarkEdenPenetratio(默认50%):控制abortable-preclean阶段什么时候结束执行此阶段会打印一些日志如下:CMS-concurrent-abortable-preclean-start,CMS-concurrent-abortable-preclean,
CMS:abort preclean due to time XXXh)再下一个阶段是第二个stop the world阶段了,即Rescan阶段,此阶段暂停应用线程,对对象进行重新扫描并
标记YG occupancy:964861K(2403008K),指执行时young代的情况CMS remark:961330K(1572864K),指执行时old代的情况此外,还打印出了弱引用处理、类卸载等过程的耗时i)再下一个阶段是CMS-concurrent-sweep,进行并发的垃圾清理j)最后是CMS-concurrent-reset,为下一次cms gc重置相关数据结构(3)full gc:有2种情况会触发full gc,在full gc时,整个应用会暂停a)concurrent-mode-failure:当cms gc正进行时,此时有新的对象要进行old代,但是old代空间不足造成的b)promotion-failed:当进行young gc时,有部分young代对象仍然可用,但是S1或S2放不下,
因此需要放到old代,但此时old代空间无法容纳此
频繁full gc的原因
从日志中可以看出有大量的concurrent-mode-failure,因此正是当cms gc进行时,有新的对象要进行old代,
但是old代空间不足造成的full gc进程的jvm参数如下所示:影响cms gc时长及触发的参数是以下2个:-XX:CMSMaxAbortablePrecleanTime=5000-XX:CMSInitiatingOccupancyFraction=80解决也是针对这两个参数来的根本的原因是每次请求消耗的内存量过大解决
(1)针对cms gc的触发阶段,调整-XX:CMSInitiatingOccupancyFraction=50,提早触发cms gc,就可以
缓解当old代达到80%,cms gc处理不完,从而造成concurrent mode failure引发full gc(2)修改-XX:CMSMaxAbortablePrecleanTime=500,缩小CMS-concurrent-abortable-preclean阶段
的时间(3)考虑到cms gc时不会进行compact,因此加入-XX:+UseCMSCompactAtFullCollection
(cms gc后会进行内存的compact)和-XX:CMSFullGCsBeforeCompaction=4
(在full gc4次后会进行compact)参数但是运行了一段时间后,只不过时间更长了,又会出现频繁full gc计算了一下heap各个代的大小(可以用jmap -heap查看):total heap=young+old=4096mperm:256myoung=s1+s2+eden=2560myoung avail=eden+s1=2133.375+213.3125=2346.6875ms1=2560/(10+1+1)=213.3125ms2=s1eden=2133.375mold=1536m可以看到eden大于old,在极端情况下(young区的所有对象全都要进入到old时,就会触发full gc),
因此在应用频繁full gc时,很有可能old代是不够用的,因此想到将old代加大,young代减小改成以下:-Xmn1920m新的各代大小:total heap=young+old=4096mperm:256myoung=s1+s2+eden=1920myoung avail=eden+s1=2133.375+213.3125=1760ms1=1760/(10+1+1)=160ms2=s1eden=1600mold=2176m此时的eden小于old,可以缓解一些问题
改完之后,运行了2天,问题解决,未频繁报full gc https://my.oschina.net/goldwave/blog/168516