ADO.NET操作数据库(四)
主要内容: 连接查询、左表、右表、内连接、外连接、笛卡尔积、on子句数据筛选、自连接、存储过程、连接查询、模糊查询、视图、T-SQL编程、全局变量、局部变量、事务、系统存储过程、用户自定义存储过程、ado.net调用存储过程、触发器。
快捷键:格式化快捷键 ctrl+K,Y
详细内容:
1、连接查询
连接查询:关键是看两张表的主外键关系
内连接:inner join:多表内连接,无论连接几张表,每次执行都是两张表进行连接。在多张表中进行查询,结果在一张表中。
外连接:左外连接(left outer join) 有外连接(right outer join)。左表和右表。
连接查询的基本执行步骤:1)笛卡尔积,好好理解这个概念2)应用on筛连接选器3)添加外部行,到此from执行完毕。
当使用连接查询的时候,如果同时要指定查询的条件,那么一定要使用where子句,不要直接在on条件后面跟and来编写其他查询条件。
内连接执行的过程是:先进行笛卡尔积,然后进行on筛选条件,如果是外连接,就添加对应表中的数据。添加外部行。
外连接的执行步骤:
1)构建笛卡尔积;
2)根据left join on条件进行行数据的筛选;
3)因为是外连接,所以要显示左表中的所有记录,所以接下来要进行"添加外部行"。把左表中哪些没有筛选出来的哪些数据再添加到当前的查询结果集中
自连接:
外连接:是指多张表进行连接。
什么叫自连接:自己和自己连接,把表中的所有列都复制一份。
select * from TblArea as t1,TblArea as t2;从这两张表中进行查询
对表起别名特别有用;对列起别名,汉字好理解。
关键是对逻辑关系的理解,弄清楚了这个,代码很好写的。
查询所有学生的姓名、年龄以及所在班级:
分析:需要从学生表和班级表中进行查询。需在在多张表中进行查询,这就需要用到连接。
select t1.tsName,t1.tsAge ,t2.tsClass FROM Student as ti inner join Class as t2 on t1.tsClass=t2.tClassId 这是连接条件?
查询年龄超过20岁的所有学生的姓名、年龄以及所在班级:
select t1.tsName,t1.tsAge ,t2.tsClass FROM Student as ti inner join Class as t2 on t1.tsClass=t2.tClassId where tsAge > 20
请查询出所有同学的姓名,年龄,英语成绩,数学成绩:(但是某些学生没有参加考试)
如何理解左外连接:如果找不到对应的值,则值为空。left join关键字两边都有一张表,把左边表中的所有数据都显示出来;
同时右边的表,如果存在就显示出来,如果找不到匹配的数据,就显示为null。
出现在left join左侧的表就是左表,出现在left join右侧的表就是右表。
内连接是只显示哪些两张表中都匹配的数据。
USE MyFirstData; SELECT * FROM dbo.Teacher; INSERT INTO Teacher VALUES ( N'赵灵儿', 1, 18, GETDATE(), N'中国台湾省', N'[email protected]', 15555 ); DELETE FROM Teacher WHERE TeaID = 8; SELECT * FROM Teacher WHERE TeaName = '陈诗音'; USE MyFirstData; INSERT INTO PhotoType VALUES ( 4, '家人' ); SELECT * FROM PhotoType; SELECT * FROM PhoneNum; INSERT INTO PhoneNum VALUES ( 5, 3, '大乔', 130241123, 700004 );
内连接:
--内连接查询的使用 INNER JOIN ...on... (连接条件 笛卡尔积加上筛选条件)
--内连接:把多张表的数据在一个表中显示
--为什么使用表名.列名,为了防止两张表中存在重名的列名。查询的时候,如果表中有重复的列名,应该在列名前面加上表名。
--查询语句的执行顺序:select* from PhoneNum;执行顺序是:先执行from子句,在执行select子句
SELECT *
FROM dbo.PhoneNum
INNER JOIN dbo.PhotoType ON PhoneNum.pTypeId = PhotoType.ptId;
SELECT PhoneNum.pId ,
PhoneNum.pName ,
PhoneNum.pCellPhone ,
pHomePhone ,
ptName
FROM dbo.PhoneNum
INNER JOIN dbo.PhotoType ON PhoneNum.pTypeId = PhotoType.ptId;
--查询的时候,为表起一个别名。
SELECT pn.pId ,
pn.pName ,
pn.pCellPhone ,
pHomePhone ,
ptName
FROM dbo.PhoneNum AS pn
INNER JOIN dbo.PhotoType ON pn.pTypeId = PhotoType.ptId;
--使用带参数的SQL语句向数据库中插入空值
SELECT *
FROM Teacher;
2、多条件查询(模糊查询)
模糊查询(多条件查询):使用带参数的SQL语句.比如根据作者查询数据,根据年份查询书籍。
使用 like关键字进行模糊查询。动态拼接sql语句,看看用户输入了哪些查询条件或者前台传递过来哪些查询关键字。
1)如果用户没有输入任何条件,那就直接查询出所有的记录。2)如果用户输入了条件,则根据用户输入的条件动态拼接sql语句。
对应项目开发中的搜索模块。
static void Main(string[] args)
{
//多条件查询
//查询书籍:Books表,列:Author作者 BooKName书名 Pub出版社
StringBuilder sb = new StringBuilder("select * from Books ");
//创建一个list集合,用来保存查询条件
List<string> where = new List<string>();
where.Add(" BooKName like @bookName");
where.Add(" Author like @author");
where.Add(" Pub like @pub");
//拼接sql语句
//如果where集合当中的记录条数大于0,证明用户输入了条件
if (where.Count > 0)
{
sb.Append("where ");
//把集合中的查询条件通过and连接起来
string configtion = string.Join(" and ", where);
sb.Append(configtion);
}
//方法二:
List<SqlParameter> listParameter = new List<SqlParameter>();
listParameter.Add(new SqlParameter("@bkName",System.Data.SqlDbType.NVarChar,100));
//sql语句中所有的参数
SqlParameter[] pms= listParameter.ToArray();
//带参数的sql语句
//sb.Append(" BooKName like @bookName");
//sb.Append(" Author like @author");
//sb.Append(" Pub like @pub");
}
3、视图
视图概述:主要用于封装复杂查询的。
注意这四个问题.: 如何创建视图?如何删除视图?视图的作用是什么?什么时候使用视图?
数据是怎么存储的?
视图是一张虚拟表,它表示一张表的部分数据或者多张表的综合数据,其结构和数据是建立在对表的查询基础上。
视图在操作上和数据表没有什么区别,但是两则的差异是其本质不同:数据表是实际存储记录的地方,然而视图并不保存任何记录。
相同的数据表,根据不同用户的不同需求,可以创建不同的视图(不同的查询语句);
视图的目的是方便查询,所以一般情况下不能对视图进行增删改。
优点:筛选表中的行/降低数据库的复杂程度(调用视图,直接一句话进行查询),防止未经许可的用户访问敏感数据(看不到表名和表字段)。
视图其实是对复杂的查询语句的封装。直接调用视图就可以进行查询了。
View 关键字的封装
create View vw_TblArea as .... create View 视图名称 as ....
select * from vw_TblArea; 视图相当于别名
SQL Server下有视图结点
视图只能写(保存)查询语句,而存储过程就像方法一样,特别灵活。可以使用存储过程替代视图。
视图中不能有参数。
如果视图中的查询语句中包含了重名的列(多个表之间)必须给列起别名。
普通视图并不存储数据(虚拟表),访问的是真实表中的数据。

4、T-SQL编程
T-SQL编程:(先声明在赋值)
声明局部变量:DECLARE @变量名 数据类型 [=默认值]
例如:declare @name varchar(20); declare @age int;
赋值:
set @变量名=值; set用于普通的赋值
select @变量名=值; 用于从表中查询数据并赋值,可以一次给多个变量赋值。
例如:set @name=‘张三’; set @id=1; select @name=sName FROM Student where sId=@id
输出变量的值:(打印变量的值)
1)select以表格的方式输出,可以同时输出多个变量。select @name,@id
2)print以文本的方式输出,一次只能输出一个变量的值。print @name;print @id
print @name,@id; 这样写是错误的。
变量分类:
1)局部变量:局部变量必须以标记@作为前缀,比如 @Age int;局部变量必须先声明,在赋值。
2)全局变量:全局变量的定义必须以@@作为前缀,如 @@version 全局变量有系统维护和定义,我们只能读取,不能修改全局变量的值。
全局变量又称为系统变量。两个@@符号开头的一半都是系统变量。
SQL中常用的全局变量:
@@version:SQL Server的版本信息
@@SERVERNAME:本地计算机的名称
@@TRANSCOUNT:当前连接打开的事务数。
@@rowcount:受上一个SQL语句影响的行数。
@@max_connections:可以创建的同时连接的最大数目。
@@language:当前使用的语言的名称。
PRINT @@VERSION; PRINT @@version; PRINT @@SERVERNAME; PRINT @@TRANCOUNT; PRINT @@rowcount; PRINT @@max_connections; PRINT @@language;
在sql里面怎么写循环?
1)sql里面是没有for循环的,使用while循环。如何使用while循环输出100句hello?
2)在循环结构里面可以使用break,continue
在sql里面怎么写if-else?
IF(条件表达式)
begin 相当于C#里面的{
end 相当于C#里面的}
else
begin 相当于C#里面的{
end 相当于C#里面的}
--声明变量
DECLARE @name NVARCHAR(10);
DECLARE @age INT;
--赋值变量
SET @name = '陈如水';
SET @age = '12';
SELECT @name = '陈如水';
--输出,用逗号分隔的都是列名,要显示两列。
--必须全部选中才能执行,因为如果不赋值,直接取值,就会报错。
SELECT '姓名' ,
@name;
SELECT '年龄' ,
@age;
--可以使用一句话来声明多个变量,使用逗号分隔
DECLARE @UserName NVARCHAR(20) ,
@UserAge INT;
--在sql使用while循环,BEGIN和end相当于开始和结束大括号
--如何改变循环变量的值,其实就相当于设置值
DECLARE @i INT= 1;
--声明变量的同时进行赋值。
WHILE ( @i < 100 )
BEGIN
PRINT 'hello';
SET @i = @i + 1;
END;
--计算1到100之间的整数和
--如果 @sum INT 不赋初值,结果就是null,所以必须赋初值。
DECLARE @sum INT= 0 ,
@j INT = 1;
WHILE ( @j <= 100 )
BEGIN
--记得这里是为变量赋值
SET @sum = @sum + @j;
SET @j = @j + 1;
END;
PRINT @sum;
--如何实现 if-esle结构
DECLARE @a INT = 10;
IF @a > 10
BEGIN
PRINT '@a大于10';
END;
ELSE
IF @a > 5
BEGIN
PRINT '@a大于5';
END;
ELSE
BEGIN
PRINT '@a大于0';
END;
--计算1到100之间所有奇数和
--需要一个求和变量和循环变量
DECLARE @k INT= 1 ,
@sums INT= 0;
WHILE ( @k <= 100 )
BEGIN
--如果除2,能够除尽
IF @k % 2 <> 0
BEGIN
SET @sums = @sums + @k;
END;
SET @k=@k+1;
END;
PRINT @sums;
--如果打印的值为0,表示上一条sql语句执行没有出错。
PRINT @@ERROR;
5、事务
为什么需要事务?
指访问并可能更新数据库中各种数据项的一个程序执行单元,也就是说多个sql语句,必须作为一个整体执行。
这些sql语句作为一个整体一起向系统提交,要么都执行,要么都不执行。
语法:
开始事务 begin transaction
提交事务 commit transaction
回滚事务 rollback transaction
判断某条语句是否出错,使用全局变量@@error
事务分类:
1)自动提交事务:数据库自动来做,不需要用户考虑任何事情。insert into Teacher values();默认情况下sql使用的是自动提交事务。
2)隐式事务:set implicit transaction on | off 每次执行一条sql语句的时候,数据库会自动帮助我们打开一个事务,但是需要我们手动提交事务或者回滚事务。不手动提交或者回滚,sql语句执行不能成功,显示一直正在执行中。
3)显示事务:需要开发人员手动打开、回滚、提交事务。1)如果想要把一个查询结果赋值给变量,则必须用()括起来
事务的几个特性:
原子性、一致性、隔离性(多个事务之间)、持久性:事务完成后,它对于系统的影响是永久性的,该修改即使出现系统故障也将一直保持。
在转账之前最好通过if-else判断,不要让程序发生异常或者错误。
如何保证两条语句要么同时执行成功要么同时执行失败?使用事务来保证。
把要执行的代码放置到一个事务里面;如果其中的某一行行执行出错,那就让代码回滚。
1)打开一个事务 begin transaction
2)declare @sum int;每执行一条sql语句,就记上这样一句话:set @sum=@sum+@@error。只要有人恶化一条sql语句出错,sum的值就不是0。
3)if @sum<>0 说明其中的代码执行出错。
begin
说明其中的代码执行出错。
直接进行回滚
rollback;
end
else
begin
//如果程序执行没有出错,就进行提交代码。
commit
end
6、存储过程
1)其实就是在数据库中运行方法(函数),它和c#里面的方法一样,由存储过程名/存储过程参数组成/可以有返回结果。
2)if--else、while、变量、insert等,都可以在存储过程中使用。
3)使用存储过程的优点:执行速度快,在数据库中保存的存储过程语句都是编译过的。允许模块化程序设计,类似方法的复用。提高系统安全性,防止SQL注入;减少网络流通量,只要传输存储过程的名字。
4)系统存储过程:由系统定义,存放在master数据库中。名称以“sp_”开头或者“xp_”开头,自定义的存储过程可以以usp_开头。
5)自定义的存储过程:由用户在自己的数据库中创建的存储过程usp。
6)使用存储过程也有缺点:如果在服务器端写了过多的存储过程,当用户访问量比较大时,所有的压力都有数据库来承担了。把业务逻辑也写到存储过程里面了,业务逻辑应在在C#代码里面的。一旦服务器出现瓶颈,优化起来比较困难。注意控制使用存储过程的数量。
存储过程和函数在本质上没有区别。函数只能返回一个变量,而存储过程可以返回多个。一般来说存储过程实现额功能要复杂一些,而函数实现的功能针对性比较强。
把存储过程当做一个独立的部分来执行。
把常用的代码封装到存储过程里面,直接调用存储过程名就好了。
usp_开头一般是用户存储过程。
存储过程内部就是一段sql代码。
order by 索引 :按照第几列进行排序。
系统存储过程:直接可以拿来用。凡是以sp开头的一般都是存储过程。
sp_databases:列出服务器上所有的数据库。
sp_helpdb:报告有关指定数据库或所有数据库的信息。
sp_renamedb:更改数据库的名称。
sp_tables:返回当前环境下所有的数据表(use关键字的使用)。
sp_columns:返回某个表列的信息。
sp_help:查看某个表的所有信息。
sp_helpconstraint:查看某个表的约束。
sp_helpindex:查看某个表的索引。
sp_stored_procedures:列出当前环境下所有的存储过程。
sp_password:添加或修改登录账户的密码。
sp_helptext:显示默认值、未加密的存储过程、用户定义的存储过程、触发器或试图的实际文本。(获取存储过程的源代码)
如何执行存储过程?
如果是系统存储过程,直接选中存储过程的名字,可以直接执行;
对于用户自定义的存储过程,存储过程名之前要加exec:exec 存储过程名。
如何创建自定义的存储过程?
定义存储过程的语法:
create proc[edure] 存储过程名
@参数1 数据类型=默认值 output,
@参数n 数据类型=默认值 output
as
sql语句
参数说明:参数可选,参数分为输入参数、输出参数,输入参数允许有默认值。
1)存储过程的分类: 系统存储过程与用户自定义存储过程
2)执行存储过程的关键字: exec 存储过程名 [参数] ;创建存储过程的语句:CREATE PROC usp_say_he。
3)用户自定义存储过程一般以usp开头,见名知意,要使用关键字表示,这个存储过程是操作哪张表的?
4)存储过程英语: procedure
5)创建执行过程----->执行存储过程(调用存储过程),这是两个过程,千万别忘了。
6)自定义存储过程的标准语法:create proc 存储过程名 as begin 具体的业务逻辑 end。
7)如何删除存储过程: drop proc 存储过程名。
8)如何查看某个存储过程的源代码? exec sp_helptext 'sp_databases';
1)如何创建带参数的存储过程;
2)如何设置存储过程参数的默认值?
3)如何调用带参数的存储过程?
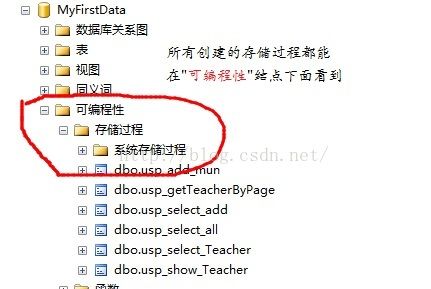
--存储过程的分类: 系统存储过程与用户自定义存储过程 --执行存储过程的关键字: EXEC;创建存储过程的语句:CREATE PROC usp_say_he。用户自定义存储过程一般以use开头 --存储过程英语: procedure EXEC sp_databases; USE Activity GO EXEC sp_tables; go --返回某张表下的所有列 --自定义存储过程(无参数与无返回值) CREATE PROC usp_say_he AS BEGIN SELECT 1+1; END --如何执行存储过程 EXEC usp_say_he --如何删除存储过程 DROP PROC dbo.usp_say_he; go --子定义存储过程 CREATE PROC usp_select_all AS BEGIN SELECT * FROM Teacher; END EXEC usp_select_all; --创建带参数的存储过程 CREATE PROC usp_add_mun @n1 int, @n2 int AS BEGIN SELECT @n1+@n2; END EXEC usp_add_mun 100,500; --创建两个带参数的存储过程 CREATE PROC usp_select_Teacher @TeaGender bit, @TeaAge INT AS BEGIN SELECT * FROM Teacher WHERE TeaGender>=@TeaGender AND TeaAge >=@TeaAge; END --把参数写全也是可以的。 EXEC usp_select_Teacher 1,25; EXEC usp_select_Teacher @TeaGender=1,@TeaAge=25; --设置存储过程参数的默认值(如果给定新值,就是用新值进行计算,没有就是用默认值进行计算) CREATE PROC usp_select_add @n1 int, @n2 INT=10 AS BEGIN SELECT @n1+@n2; END EXEC usp_select_add 20,20; --带输出参数的存储过程(使用输出参数两个地方都会用到,设置输出参数的地方,打印输出参数的地方) --当在存储过程中需要返回多个值的时候,就可以使用输出参数来返回这些值。 --查询年龄大于给定年龄的所有记录 CREATE PROC usp_show_Teacher @TeaAge int, @recordcount int OUTPUT --这个值用于向外输出 AS BEGIN SELECT * FROM Teacher WHERE TeaAge> @TeaAge --把查询到的值赋值给变量(记录的条数) SELECT @recordcount=(SELECT COUNT(*) FROM Teacher WHERE TeaAge> @TeaAge); END --调用存储过程 --调用带有输出参数的存储过程的时候,需要定义变量,将变量传递给输出参数,在存储过程中使用的输出参数,其实就是你传递进来的变量值 --声明一个变量 DECLARE @re INT EXEC usp_show_Teacher 22,@recordcount=@re output; PRINT @re; SELECT * FROM Teacher; --使用存储过程来实现分页查询 --对Teacher实现分页查询,用户传递进来两个,传递给用户两个。 --对每一列都进行编号 --把分页查询的代码都封装到一个存储过程里面 --在创建存储过程的语句前面添加一句话go,就不会报错了。 go CREATE PROC usp_getTeacherByPage @pagesize int=3,--每页记录条数,每页默认显示三条记录 @pageindex INT=1, --要查看第几页的数据 @recodecount int OUTPUT, --总的记录的条数 @pagecount int OUTPUT --总的页数 AS BEGIN --编写查询语句,把用户所要的数据查询出来,相当于是一哥新的表 --使用between关键字应该注意:and左侧的数比较小,and右侧的数应该比较大。 SELECT * FROM ( SELECT *,rn=ROW_NUMBER() OVER (ORDER BY TeaID ASC) FROM Teacher) AS newTable WHERE newTable.rn BETWEEN (@pageindex-1)*@pagesize+1 AND @pageindex*@pagesize --计算总的记录条数 SET @recodecount=(SELECT COUNT(*) FROM Teacher); --计算总的页数 ceiling向上取整数 SET @pagecount =CEILING(@recodecount*1.0/@pagesize) END --分页查询,存储过程的调用 DECLARE @rc INT; DECLARE @pc INT EXEC usp_getTeacherByPage @pagesize=4,@pageindex=2,@recodecount=@rc output,@pagecount=@pc output; PRINT @rc PRINT @pc
7、set与select赋值区别
declare @a int
set @a=(select count(*) from Teacher)
select @a=count(*) from Teacher
print @a;
2)print每次只能打印一个变量的值。
set @a=1;
select @a=1;
3)下面这种情况是有问题的
declare @i int;
set @i=(select tsage from Teacher)
print @i;
因为查询结果不是一个数据,而是一列数据,所以这样赋值会报错。
当通过set为变量赋值的时候,如果查询语句返回的不是单个值,那么就会报错。
下面这种写法不会报错的。
declare @i int;
select @i=(select tsage from Teacher)
print @i;
但是当通过select为变量赋值的时候,如果查询语句返回的不止一个值,那么会将最后一个结果赋值给该变量。
相对而言,set赋值更严谨一些,select赋值更灵活一点。
八、如何通过ado.net来调用存储过程?
1、通过ado.net调用存储过程与调用带参数的sql语句的区别
1)把sql语句变成存储过程名.
2)设置SqlCommand对象的CommandType为CommandType.StoredProcedure.
3)根据存储过程的参数来设置输出参数的Direction属性.
4)如果有输出参数,需要设置输出参数的Direction属性为Direction=ParameterDirection.Output.
2、如果是通通过调用Command对象的ExecuteReader()方法来执行该存储过程的,
那么想要获取输出参数,必须等到关闭reader对象后,才能获取输出参数的值。
3、为什么执行存储过程的时候,需要设置CommandType.StoredProcedure.设置此属性,到底做了什么事情?
4、同一个SqlParameter不能同时用于多个SDqlCommand对象,否则会报错。
int pagesize = 3;
int pageindex = 2;
int recodecount;
int pagecount;
//如何通过ado.net调用存储过程
string connStr = @"data source=172.16.20.1\dev; initial catalog =MyFirstData;user ID=gungnirreader;PASSWORD=itsme999";
using (SqlConnection conn = new SqlConnection(connStr))
{
//1)把sql语句修改成存储过程的名字
string sql1 = "usp_getTeacherByPage";
using (SqlCommand comm = new SqlCommand(sql1, conn))
{
//2)告诉命令对象,现在执行的不是sql语句,而是存储过程
comm.CommandType = System.Data.CommandType.StoredProcedure;
//增加参数:存储过程中有四个参数,这里就要增加四个参数
SqlParameter[] spm = new SqlParameter[] {
//参数名称必须和存储过程中的参数名称一样
new SqlParameter("@pagesize",System.Data.SqlDbType.Int) {Value=pagesize},
new SqlParameter("@pageindex",System.Data.SqlDbType.Int) { Value=pageindex},
//输出参数不需要给它赋值,只需要取值就可以啦
//告诉命令对象,这两个参数是输出参数,使用枚举值进行标识
new SqlParameter("@recodecount",System.Data.SqlDbType.Int) { Direction=System.Data.ParameterDirection.Output},
new SqlParameter("@pagecount",System.Data.SqlDbType.Int){ Direction=System.Data.ParameterDirection.Output}
};
//把参数添加到命令对象中
comm.Parameters.AddRange(spm);
}
}
//使用sqlDataAdapter来实现
string sql = "usp_getTeacherByPage";
//存储过程名称和连接字符串
using (SqlDataAdapter adapter = new SqlDataAdapter(sql, connStr))
{
//查询结果是一张数据表
DataTable dt = new DataTable();
//告诉adapter执行的不是sql语句,而是存储过程
adapter.SelectCommand.CommandType = System.Data.CommandType.StoredProcedure;
//增加参数:存储过程中有四个参数,这里就要增加四个参数
//存储过程中有几个参数就添加几个参数
SqlParameter[] spm = new SqlParameter[] {
//参数名称必须和存储过程中的参数名称一样
new SqlParameter("@pagesize",System.Data.SqlDbType.Int) {Value=pagesize},
new SqlParameter("@pageindex",System.Data.SqlDbType.Int) { Value=pageindex},
//输出参数不需要给它赋值,只需要取值就可以啦
//告诉命令对象,这两个参数是输出参数,使用枚举值进行标识
new SqlParameter("@recodecount",System.Data.SqlDbType.Int) { Direction=System.Data.ParameterDirection.Output},
new SqlParameter("@pagecount",System.Data.SqlDbType.Int){ Direction=System.Data.ParameterDirection.Output}
};
adapter.SelectCommand.Parameters.AddRange(spm);
//所有的查询结果都在这张表里面
adapter.Fill(dt);
//如何拿到输出参数的值(获取输出参数)
string a = spm[2].Value.ToString();
string b = spm[3].Value.ToString();
//总共只有三步,调用存储过程。如果有输出参数,必须存储过程调用完毕后才能获取输出参数的值,必须设置参数的方向。
//通过ado.net调用存储过程与通过ado.net调用sql语句的区别。
//把sqlhelper中添加可以调用存储过程的方法
//为什么执行存储过程的时候,需要设置CommandType.StoredProcedure?设置该属性,到底做了什么事情?
//如果不想设置CommandType.StoredProcedure,直接在存储过程名称前添加exec即可
}
}
九、静态类构造函数的特点:
static MyClass(){
}
1)要使用static关键字修饰。
2)只执行一次,在第一次使用静态类之前执行一次。
3)静态构造函数不重载。
十、把事务转账封装到一个存储过程里,并通过ado.net调用该存储过程。
--案例:创建存储过程使用事务实现转账
CREATE TABLE bank( cid INT identity(1,1) PRIMARY key,balance MONEY)
SELECT * FROM bank;
DROP TABLE bank;
INSERT INTO dbo.bank VALUES( 930.00)
INSERT INTO dbo.bank VALUES( 80.00)
INSERT INTO dbo.bank VALUES( 100000.00)
GO
CREATE PROCEDURE usp_transfer
@from INT,
@to INT,
@balance MONEY, --转账金额
@result int OUTPUT --转账结果(1表示转账成功2表示转账失败0表示余额不足)
AS
BEGIN
--判断是否执行成功,进行提交事务或者回滚事务
--判断金额是否足够转账
DECLARE @money MONEY
SELECT @money=balance FROM bank WHERE cid=@from;
IF(@money-@balance>=10)
--说明金额足够转账,开始转账
BEGIN
--开启事务
BEGIN TRANSACTION;
DECLARE @sum INT;
--账户一扣钱,更新账户一,从哪个账户转出
UPDATE bank SET balance=balance-@balance WHERE cid=@from;
--如果执行不出错,@@ERROR结果为0,
SET @sum=@sum+@@ERROR;
--账户二加钱
UPDATE bank SET balance=balance+@balance WHERE cid=@to;
SET @sum=@sum+@@ERROR
--判断转账是否执行成功
IF(@sum<>0)
BEGIN
SET @result=2;
ROLLBACK TRANSACTION;--转账失败
END
ELSE
BEGIN
SET @result=1;
COMMIT TRANSACTION;--转账成功
END
END
ELSE
BEGIN
SET @result=0;--表示余额不足
END
END
DECLARE @re int
EXEC dbo.usp_transfer @from = '1', -- char(4)
@to = '2', -- char(4)
@balance = 100, -- money
@result = @re OUTPUT -- int
PRINT @re;
DECLARE @resu int
EXEC dbo.usp_transfer @from = '1', -- char(4)
@to = '2', -- char(4)
@balance = 8000, -- money
@result = @resu OUTPUT -- int
PRINT @resu;
SqlParameter[] pms = new SqlParameter[] {
new SqlParameter("@from",SqlDbType.Int) {Value=1},
new SqlParameter("@to",SqlDbType.Int) { Value =2},
new SqlParameter("@balance",SqlDbType.Money) {Value=10 },
new SqlParameter("@result",SqlDbType.Int) { Direction=ParameterDirection.Output } };
SqlHelper.ExecuteNonQuery("usp_transfer", CommandType.StoredProcedure, pms);
int rows = Convert.ToInt32(pms[3].Value);
switch (rows)
{
case 1: Console.WriteLine("转账成功!"); break;
case 2: Console.WriteLine("转账失败!"); break;
case 0: Console.WriteLine("余额不足!"); break;
default:
Console.WriteLine("没有匹配的项");
break;
}
Console.ReadKey();
十一、如何通过存储过程对表实现增删改查?
--使用存储过程实现对表Teacher的增删改查 SELECT * FROM Teacher; --使用存储过程向表中插入数据 GETDATE() 获取当前的时间 go CREATE PROCEDURE usp_insert_Teacher @TeaName NVARCHAR(20), @TeaGender BIT, @TeaAge INT, @TeaAddress NVARCHAR(20), @TeaEmail NVARCHAR(20), @TeaSalary MONEY AS BEGIN INSERT INTO Teacher VALUES(@TeaName,@TeaGender,@TeaAge,@TeaAddress,@TeaEmail,@TeaSalary); END; DROP PROC usp_insert_Teacher; ALTER TABLE Teacher DROP COLUMN TeaBirthdat; --忘记声明变量了,如果没有输出参数就不用声明变量。 EXECUTE usp_insert_Teacher @TeaName='江湖',@TeaGender=1,@TeaAge=2,@TeaAddress='人间',@TeaEmail='[email protected]',@TeaSalary=1111; --使用存储过程删除表中的记录(根据主键id) GO CREATE PROC usp_delete_Teacher @TeaID INT AS BEGIN DELETE FROM Teacher WHERE TeaID=@TeaID END SELECT * FROM Teacher; EXEC usp_delete_Teacher 16; --使用存储过程更新表中的记录 GO CREATE PROCEDURE usp_update_Teacher @TeaID INT, @TeaName NVARCHAR(20), @TeaGender BIT AS BEGIN UPDATE Teacher SET TeaName=@TeaName,TeaGender=@TeaGender WHERE TeaID=@TeaID END EXEC usp_update_Teacher 1 ,'凌霄',1;--必须和参数声明的顺序一一对应。 --使用存储过程查询表中的记录 go CREATE procedure usp_select_Teacher1 AS BEGIN SELECT * FROM Teacher; END
十一、sql里面的try...catch..。
--sql里面的try...catch... BEGIN TRY UPDATE Teacher SET TeaAge=-1 WHERE TeaID=1; END TRY BEGIN CATCH PRINT '出异常了' END CATCH
十二、触发器:
trigger(枪上的扳机)
1)作用是:自动化操作,减少了手动操作以及出错的几率。
2)理解:触发器是一种特殊的存储过程,在SQL内部把触发器看做是存储过程但是不能传递参数。
3)一般的存储过程通过存储过程名被直接调用,但是触发器主要是通过事件进行触发而执行。
4)处罚器是一个功能强大的工具,在表的数据发生变化时自动强制执行。触发器还可以用于Sql server约束、默认值和规则的完整性检查
还可以完成难以用普通约束实现的复杂功能。
5)什么是触发器呢? 在SQL Server里面也就是对某一个表的某种操作,处罚某个条件,从而执行的一段程序。触发器是一个特殊的存储过程。
可以理解为一个特殊的存储过程。触发器不是用户自己调用的,而是在某种情况下自动执行的。
触发器分类:
1)DML触发器:数据操作 删除、更新、插入; after触发器(for) instead of触发器()
2)DDL触发器:数据定义 create table; create database; alter; drop比如当一张表创建以后,立即出发一个事情。
3)inserted表与deleted表,这两张表是做什么的?inserted表包含新数据,insert、update触发器会用得到。
deleted表包含旧数据,delete、update触发器会用到。
十三、使用SqlHelper封装存储过程的调用:
//5)调用存储过程
//5.1执行增删改的方法
//可变参数的位置必须是在参数的最后一个位置
public static int ExecuteNonQuery(string sql, CommandType cmdType, params SqlParameter[] pms)
{
using (SqlConnection conn = new SqlConnection(connStr))
{
using (SqlCommand comm = new SqlCommand(sql, conn))
{
//用于区别是存储过程还是sql语句
comm.CommandType = cmdType;
if (pms != null)
{
comm.Parameters.AddRange(pms);
}
conn.Open();
return comm.ExecuteNonQuery();
}
}
}
//5.2执行查询,返回单个值的方法
public static object ExecuteScale(string sql, CommandType cmd, params SqlParameter[] pms)
{
using (SqlConnection conn = new SqlConnection(connStr))
{
using (SqlCommand comm = new SqlCommand(sql, conn))
{
comm.CommandType = cmd;
if (pms != null)
{
comm.Parameters.AddRange(pms);
}
conn.Open();
return comm.ExecuteScalar();
}
}
}
//5.3执行查询,返回多行多列的方法 ExecuteReader()
public static SqlDataReader ExecuteReader(string sql, CommandType cmd, params SqlParameter[] pms)
{
using (SqlConnection conn = new SqlConnection(connStr))
{
using (SqlCommand comm = new SqlCommand(sql, conn))
{
comm.CommandType = cmd;
if (pms != null)
{
comm.Parameters.AddRange(pms);
}
try
{
conn.Open();
return comm.ExecuteReader(CommandBehavior.CloseConnection);
}
catch (Exception)
{
//关闭连接、释放资源。
conn.Close();
conn.Dispose();
throw;
}
}
}
}
//5.4查询数据,返回DataTable
public static DataTable ExecuteDataTable(string sql, CommandType cmd, params SqlParameter[] pms)
{
DataTable dt = new DataTable();
using (SqlDataAdapter adapter = new SqlDataAdapter(sql, connStr))
{
adapter.SelectCommand.CommandType = cmd;
if (pms != null)
{
adapter.SelectCommand.Parameters.AddRange(pms);
adapter.Fill(dt);
}
return dt;
}
}