【代码克隆检测】基于K-gram hash 分析特征提取技术(代码篇)
写在前面的话
这篇文章,是上面一章 基于K-gram的winnowing特征提取剽窃查重检测技术(概念篇)的延续版,本章为代码篇。
那就是说明我们要开始写代码了。今天双十一,大家都在玩淘宝天猫,抢红包,我一个码农苦逼的对着电脑写了一天的代码,并且依然要工作下去。
生活真是不!容!易!啊!
为了联盟,为了部落,为了伟大的社会主义,为了码农的明天会更好,我依然在写代码,看代码,调程序,看英语。哇咔咔。
这个,上面这句话会不会让人觉得我刚才医院跑出来没多久。并且忘记吃药了。。。。
1.背景知识
首先我们这篇文章的主要讲的是一个03年就提出的技术。我们主要参考的是这篇文章:Winnowing: Local Algorithms for Document Fingerprinting 你可以在这个地方下载到这篇文章。
2.实现思路
写代码不就跟做菜一样么,首先我们得想想我们需要什么食材,巧妇难为无米之炊嘛~
根据前一章的分析我们可以知道
1.我们需要一堆待检测的文档。
我们还需要对我们的文档进行一些处理,因为空格,制表符, 换行符,标点符号对我们的代码检测以及文本的相似性检测是没有任何意义的。
2. 构建 k-gram 集合
3. 构建出对应的k-gram的hash值的集合
4. winnowing算法提取出我们的特征值fingerprint
3.代码实现
3.1 构建k-gram集合
为了清楚我们的代码思路我们还是通过例子来构建我们的代码。
我们用上一章的例子来说明有一个简单的文档 叫做A,由字母yabbadabbadoo组成:
我们给它们都编一个号:
0 1 2 3 4 5 6 7 8 9 10 11 12
A : y a b b a d a b b a d o o
这个时候我们在A这个文档上取一个大小为3的滑动窗口,就得到了一个3-gram 的集合:
A : yab abb bba dad ada dab abb bba bad ado doo
我们把这个集合中的元素都称为shingle.
我们按照k来划分得到的shingle 的个数是:
N-K+1
首先这个K应该是由用户来决定的,因为这个是和我们处理的文本和代码有关系的。我们接受到用户设置的K值之后对其进行划分。每个shingle的大小为3.
我用Python 来完成今天的代码
由于产生的是集合,所以我们很容易想到存储的数据结构用list来表示。并且python给我提供了非常方便的切片方式
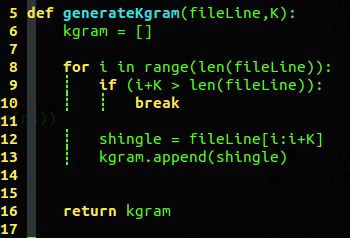
所以说产生K-gram 的代码应该很容易实现:
#!/usr/bin/env python
# coding=utf-8
# @ author : Chicho
# @ date : 2016-11-11
# fileline中存放的是我们经过处理之后的文档,已经去除掉空格制
#表符等等无关的符号的文档或者是代码
# K使我们要切片的大小
def generateKgram(fileLine,K):
kgram = [] # kgram 中存放的是我们的文档的所有shingle的集合
for i in range(len(fileLine)):
if (i+K > len(fileLine)):
break
shingle = fileLine[i:i+K]
kgram.append(shingle)
return kgram
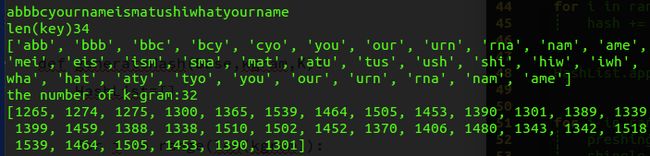
我们来验证一下算法的准确性:
多来几组试试:


k-gram集合都满足N-K+1的关系。并且都是正确的。
3.2 hash 算法
之前已经说过为了减少存储空间,提高算法的效率我们需要把特征值转换为hash值。
在这里我们采用的hash 算法是下面这个:![]() =
=
其中H表示的是映射关系,这里操作的对象是我们的每一个shingle,所以C1…CK表示的是一个有K位的元model ,将每一个C按照我们的公式进行计算得到一个hash 值,这里的b 表示的是一个基底(Base) 这里是用户自己设定的某个值,我们一般选取一个质数来做我们的基底,按照上面的公式我们计算得到我们每个 Shingle的hash 值。
有了我们的hash算法,我们就可以计算每一个shingle的hash值。
我们的文档有N,按照k 来划分,得到的shingle 总共是N-K+1个。所以我们要计算N-K+1个长度为K的shingle的hash.
这个代码按照我们之前的叙述是可以很快的解决的,如下所示
def generateHash(Base,kgram,K):
HashList=[]
for i in range(len(kgram)):
hash = 0
shingle = kgram[i]
for j in range(K):
hash +=ord(shingle[j])*(Base**(K-1-j))
HashList.append(hash)
return HashList我们现在来看一下我们的计算结果:
在这里Base 是我们自己设定的,根据我们自己设定的Hash算法计算出我们相应的散列值。
3.2.1 rolling hash 算法
但是但是,这样就ok了么。事情远没有这么简单。为什么?why?
因为实在是太浪费时间了。首先我们的文档长度是N,这个歌值可能已经很多了,在经过分组划分后,我们得到的K-gram 中含有的shingle的个数是N-K+1 ,我们要计算N-K+1 个shingle的Hash值并且每一个Hash值都有K为那么计算的时间复杂度就是O(m*K) 这里的m=N-K+1
有没有什么方法可以快一些?
这就是我们要解决的问题。一切为了性能,一切为了效率,时间就是金钱。。。。我疯了。。。
根据观察我们可以发现一些规律
比如我们要处理的文档是
yabbadabbadoo,我们设定K的值为3
这个时候我们可以得到下面的shingle,我们只列出部分,不列出全部了
yab, abb,bba
首先,要减小我们的计算复杂度你首先必须明白hash算法,它是把每一个字符串都根据某些特定的规则进行计算,我们使用的
这个算法。
我们开始的时候是计算出了yab 的Hash值,我们要abb的Hash值。这个时候我们要找出他们之间的关系。
我们在算yab的时候已经计算过ab的Hash值了,前面这个ab的hash值和后面这个ab的Hash值存在着什么样的关系呢。
其实根据算法不能找出他们的规律,就是下面这个样子的,
![]()
前面的yab的Hash值减去y的Hash值,把ab的Hash值乘以b,在加上新加入的b的Hash值就可以得到我们新的Hash值。这样就少了一次数据的遍历,并且是内层循环,效率会大大提高。这个就是传说中的 “rolling” hash 算法。
这个思想来源与一个叫做:Karp-Rabin String Matching 的思想。
OK,那么我们现在就来改进一下我们的代码。
def generateHash1(Base,kgram,K):
HashList=[]
hash=0
firstShingle = kgram[0]
for i in range(K):
hash += ord(firstShingle[i])*(Base**(K-1-i))
HashList.append(hash)
for i in range(1,len(kgram)):
preshingle = kgram[i-1]
shingle = kgram[i]
hash = hash * Base - ord(preshingle[0])*Base**K + ord(shingle[K-1])
HashList.append(hash)
return HashList 那么我们来比较一下这两个代码的性能,下面这个代码的改进能使我们的性能提升多少?
我们来看一下这两个方法分别花费的时间。要计算花费的时间我们可以参考:计算Python的代码块或程序的运行时间 这篇文章
由于我们的字符串还是比较少的,当文档越大的时候性能的差距就会越大
3.3 特征提取
为了使得我们的选取的特征值分布相对来说比较合理一点,这里我们使用了winnowing 的方法。在上面的一个小节中我们已经对这个方法做了一个简单的介绍。
这个方法的基本思想就是,我们首先设置一个大小为W的滑动窗口。将每个窗口中最小的那个hash保留下来(如果窗口中最小的hash 有两个或者多个,就保留最右边的那一个),这样就保证了我们保留下来的文档原文的间隔不会超过 W+K-1.注意,选过的特征是不能在挑选的,我们需要记录下下标。因为hash值是可能重复的。
那么在这里我想到的就是使用字典来做我们的数据结构。key就是我们的下标,value就是我们的hash值。经过这样的处理,我们就可以找出我们的fingerprint。
下面是代码的基本实现思路
#!/usr/bin/env python
# coding=utf-8
WINSIZE=4
hashValues=[77,74,42,17,98,50,17,98,8,88,67,39,77,74,42,17,98]
minHash=0
minPos=0
fingerPrint={}
for i in range(len(hashValues)):
if ((i+WINSIZE)>len(hashValues)):
break
tmplist = hashValues[i:WINSIZE+i]
minHash= tmplist[WINSIZE-1]
minPos =WINSIZE+i-1
for j in range(WINSIZE):
if tmplist[j]<minHash:
minHash = tmplist[j]
minPos = i+j
if not fingerPrint.has_key(minPos):
fingerPrint[minPos]=minHash
print fingerPrint
来看下运行结果,测试出来也是正确的。

我们只要或许我们的文章的list依次算出我们的特征值就可以了。对于之后的相似性比较我们下次再说
好的这章我们就讲到这里。
要是各位看官觉得小的博客讲的还算不错,可以随意打个赏钱呗。 感激不尽~~~~
现在是家里唯一劳动力,男丁都已经去世,一个人要养整个家不容易。希望自己成功的速度比外婆衰老的脚步快一点,他们老人家把这么淘气又喜欢惹事情的我养大十分不容易,如果大家觉得这个博客值,跪求打赏。当然不打同情牌,只用实力吃饭,觉得好的感谢支持,仅此而已。当然,没有钱场给个人场那也是极好的~~~^-^


你必须非常努力,才可以看起来毫不费力