scala筑基篇-02-集合类型
- 集合库概览
- 继承层次图
- 说明
- 序列
- List
- ListBuffer
- Array
- ArrayBuffer
- Queue
- Stack
- StringRichString
- Set
- 普通Set
- 有序的Set
- Map
- 普通Map
- 有序的Map
- 元组
集合库概览
继承层次图
scala的集合库包含了许多特质和类。要了解清楚整个结构非常非常的困难。
借助于 官网 的文档中的几个图,先大致了解下继承机构吧
scala.collection继承图
该图片来自于:http://www.scala-lang.org/docu/files/collections-api/collections.html
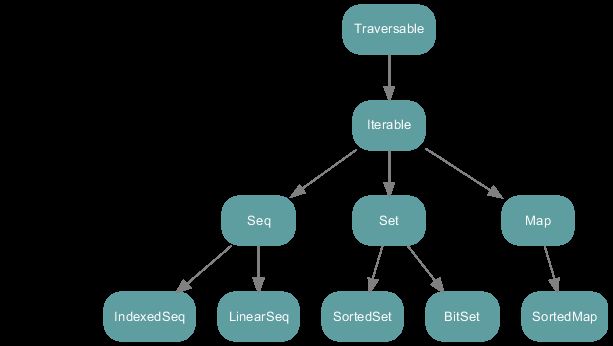
scala.collection.immutable继承图
该图片来自于:http://www.scala-lang.org/docu/files/collections-api/collections.html
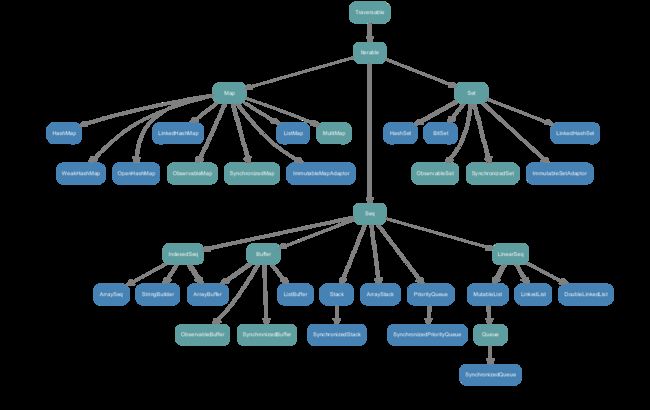
scala.collection.mutable继承图
该图片来自于:http://www.scala-lang.org/docu/files/collections-api/collections.html
说明
需要注意的是,默认情况下 scala.Predef 会被每一个scala源文件隐式导入,而在Predef中定义了诸多默认类型:
object Predef extends LowPriorityImplicits with DeprecatedPredef {
//............
type Map[A, +B] = immutable.Map[A, B]
type Set[A] = immutable.Set[A]
val Map = immutable.Map
val Set = immutable.Set
//.................
}所以,在不显式导入mutable包的情况下使用的都是immutable中的集合类。
序列
List
有关List的操作可以看看我的另一篇文章:http://blog.csdn.net/hylexus/article/details/52528498
ListBuffer
有关 ListBuffer 的操作可以看看我的另一篇文章:http://blog.csdn.net/hylexus/article/details/52528498
Array
注意点
- 使用索引访问元素应该使用圆括号而不是像java或其他语言中的方括号
//定义包含五个默认元素的数组
scala> val ints=new Array[Int](5)
ints: Array[Int] = Array(0, 0, 0, 0, 0)
//定义并制定其内容
scala> val ints1=Array(1,2,3,4,5)
ints1: Array[Int] = Array(1, 2, 3, 4, 5)
//访问应该使用圆括号而不是方括号
scala> ints1(1)
res0: Int = 2
//改变某一个元素的值
scala> ints1(1)=ints(1)
scala> ints1
res2: Array[Int] = Array(1, 0, 3, 4, 5)ArrayBuffer
scala> val ab=new scala.collection.mutable.ArrayBuffer[Int]()
ab: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
scala> ab+=1
res3: ab.type = ArrayBuffer(1)
scala> ab+=2
res4: ab.type = ArrayBuffer(1, 2)
scala> ab+=2
res5: ab.type = ArrayBuffer(1, 2, 2)
scala> ab.length
res6: Int = 3
scala> ab(0)
res7: Int = 1
scala> ab.toArray
res8: Array[Int] = Array(1, 2, 2)Queue
scala> val q1 = new scala.collection.mutable.Queue[Int]
q1: scala.collection.mutable.Queue[Int] = Queue()
//追加元素
scala> q1 += 1
res16: q1.type = Queue(1)
scala> q1 += 2
res17: q1.type = Queue(1, 2)
//追加多个元素并返回队列
scala> q1 ++= List(3, 4)
res18: q1.type = Queue(1, 2, 3, 4)
//返回并从队列删除第一个元素
scala> q1.dequeue()
res19: Int = 1
//追加多个元素,返回类型为Unit
scala> q1.enqueue(5, 6, 7)
scala> q1
res21: scala.collection.mutable.Queue[Int] = Queue(2, 3, 4, 5, 6, 7)
//队列首部
scala> q1.head
res23: Int = 2
//队列尾部
scala> q1.tail
res24: scala.collection.mutable.Queue[Int] = Queue(3, 4, 5, 6, 7)Stack
scala> val s = new scala.collection.mutable.Stack[Int]()
s: scala.collection.mutable.Stack[Int] = Stack()
//入栈
scala> s.push(1)
res25: s.type = Stack(1)
//入栈多个元素
scala> s.push(2, 3, 4)
res26: s.type = Stack(4, 3, 2, 1)
//出栈
scala> s.pop()
res27: Int = 4
scala> s
res28: scala.collection.mutable.Stack[Int] = Stack(3, 2, 1)
scala> s.push(5)
res29: s.type = Stack(5, 3, 2, 1)
//取栈顶元素而不出栈
scala> s.top
res31: Int = 5
scala> s
res32: scala.collection.mutable.Stack[Int] = Stack(5, 3, 2, 1)String/RichString
在scala中String完全可以当RichString来使用,因为在Predef中包含了从String到RichSting的隐式转换。
scala> val s="hello"
s: String = hello
scala> s.toUpperCase
res33: String = HELLO
//此处的exists方法来自于RichString
scala> s.exists(_.isLower)
res35: Boolean = trueSet
普通Set
特性
- 无序性
- 互异性
//创建一个空的Set
scala> val s=scala.collection.mutable.Set.empty[String]
s: scala.collection.mutable.Set[String] = Set()
//添加元素
scala> s+="tom"
res36: s.type = Set(tom)
scala> s+="cat"
res37: s.type = Set(tom, cat)
//重复元素被忽略
scala> s+="cat"
res38: s.type = Set(tom, cat)
//删除元素
scala> s-"tom"
res39: scala.collection.mutable.Set[String] = Set(cat)
//添加多个元素
scala> s++List("apache","Spark")
res40: scala.collection.mutable.Set[String] = Set(apache, Spark, tom, cat)
scala> s.contains("tom")
res41: Boolean = true
scala> s.contains("TOM")
res42: Boolean = false
scala> s.clear
scala> s
res44: scala.collection.mutable.Set[String] = Set()有序的Set
scala定义了SortedSet特质来实现Set元素的有序存放,SortedSet由TreeSet实现。
SortedSet中的元素必须实现特质Ordered,或者能隐式转换为Ordered特质.
scala> val s = scala.collection.mutable.TreeSet(2, 39, 6, 4)
s: scala.collection.mutable.TreeSet[Int] = TreeSet(2, 4, 6, 39)
scala> s+=1
res60: s.type = TreeSet(1, 2, 4, 6, 39)
scala> s+=5
res61: s.type = TreeSet(1, 2, 4, 5, 6, 39)Map
普通Map
scala> val m=scala.collection.mutable.Map.empty[String,Int]
m: scala.collection.mutable.Map[String,Int] = Map()
//添加键为spark值为1的元素
scala> m("spark")=1
scala> m("scala")=2
scala> m
res47: scala.collection.mutable.Map[String,Int] = Map(spark -> 1, scala -> 2)
scala> m("spark")=3
scala> m
res49: scala.collection.mutable.Map[String,Int] = Map(spark -> 3, scala -> 2)
//读取键为spark的元素
scala> m("spark")
res50: Int = 3
//添加键为apache值为2的元素
scala> m += ("apache"->2)
res53: m.type = Map(spark -> 3, scala -> 2, apache -> 2)
//删除键为scala的元素
scala> m - "scala"
res54: scala.collection.mutable.Map[String,Int] = Map(spark -> 3, apache -> 2)
//添加多个元素
scala> m ++= List("hadoop"->3,"scala"->5)
res56: m.type = Map(hadoop -> 3, spark -> 3, scala -> 5, apache -> 2)
scala> m
res57: scala.collection.mutable.Map[String,Int] = Map(hadoop -> 3, spark -> 3, scala -> 5, apache -> 2)
//删除多个元素
scala> m --=List("hadoop","apache")
res58: m.type = Map(spark -> 3, scala -> 5)
scala> m
res59: scala.collection.mutable.Map[String,Int] = Map(spark -> 3, scala -> 5)有序的Map
scala定义了SortedMap特质来实现Map元素的有序存放,SortedMap由TreeMap实现。
SortedMap中的元素必须实现特质Ordered,或者能隐式转换为Ordered特质.
scala> val m = scala.collection.immutable.TreeMap[String, Int]("c" -> 2, "a" -> 1)
m: scala.collection.immutable.TreeMap[String,Int] = Map(a -> 1, c -> 2)元组
scala也提供了像python中的元组的类型。原生的java中并没有这种类型。
有时候需要返回多个值的时候可以考虑这种类型。
获取数组中第一个长度为偶数的元素和其索引
def findFirst(arr: Array[String]): (String, Int) = {
for (i <- 0 to arr.length - 1) {
if ((arr(i).length() & 1) == 0) {
return (arr(i), i)
}
}
return ("", -1)
}
def main(args: Array[String]) {
val arr = Array[String]("tom", "cat", "apache", "spark")
val r = findFirst(arr)
println("第一个长度为偶数的元素是:" + r._1 + ",其索引为:" + r._2)
}