整理系列-20161111-Spark学习周记_3
2016.02.16
复制虚拟机:
将图中文件夹内三个框选出来的文件中出现的master全部替换为slave-x,剩余文件名也做相应改动。当然这些都只是为了让文件夹看起来更加整齐而已。
然后尝试运用到完全分布模式时,伟大的鸟哥和老魏等:
1. 鸟哥のlinux.Hadoop集群完全分布式模式环境部署.2016.02.16
2. weifield.【Hadoop】搭建完全分布式的hadoop.2016.02.17
(然而,后来发现两个文档都太老了,yarn框架没有被包括在里面,为之后的resource manager 启动失败埋了一个很深的伏笔!!)
yhason.hadoop学习之hadoop完全分布式集群安装.2016.02.17
两个虚机跑了4G内存,然后,挂了!Restart 0%。这个教训告诉我们,vmware是一个伟大的公司,完美解决硬件设备动态分配,and workstation与win10 “完美”的兼容性,醉!
这个时候来两套神器对比图!左边是计算机系统结构第一个小实验所用到的工具。右 边是工作中常用的两个,putty 的优点是无需安装,精巧实用,同类软件还有 SecureCRT。 WinSCP 和 SSH Secure 就差不多了。
简单说几点感触:
(1)计算机系统结构真的应该好好学,实验不是白做的!实验的工具在用过那么多软 件后,对比发现做得还是很业界良心的!后来自己也写过 ssh 连接的 vbs 和 python 脚本,细节上的处理真的是很多自己在用的时候没有发现的,谨以此记,提醒自己不要在实验的 过程中停止思考。
(2)计算机系统结构后面几个集群的实验,现在再看真是整个人都不好了。是时候整 理一下思路了。
Note_1
bachelor27.Ubuntu 10.04 启动到字符界面.2016.02.16
Note_2
Alt+Ctrl+F1-F6 / F7 => 字符界面 / 图形化界面
smilettxp.Ubuntu-图形界面和字符界面转换、指定默认启动界面.2016.02.16
Note_3
虚机装的不好这件事,坑死一片,同时开两个虚机就分分钟死机了,还是应该踏踏实实 装 slave,复制出来的虚机 mac 地址相同这件事巨坑无解。
Note_4
先留个笔记:

2016.02.17
Note_5
Resource manager 挂了?

tail -n200 logs/yarn-${user.name}-resourcemanager-${host}.local.log # 输出日志报错信息。 如下所示:
看了一下 yarn-site.xml 的配置内容,恍然大悟!
妥!

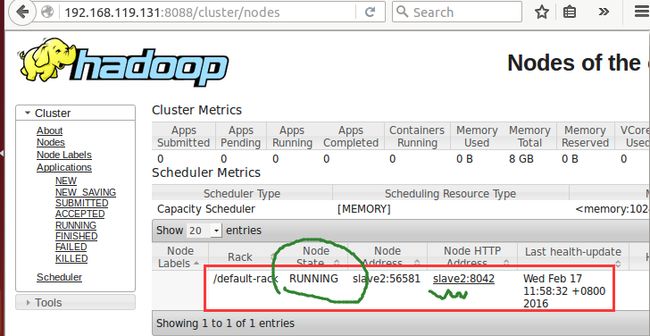
两个节点的集群搭建成功,醉了! 感谢 oschina 论坛大牛:
hoodlake.hadoop ResourceManager 无法启动.2016.02.17
伟大的 about 社区:
大数据(hadoop 系列)资源.2016.02.17
接下来准备作死学习 Spark 了!先跑一个简例试试!
![]()
2016.02.18
关闭 Ubuntu 防火墙
ufw disableNote_6
出现以下报错?
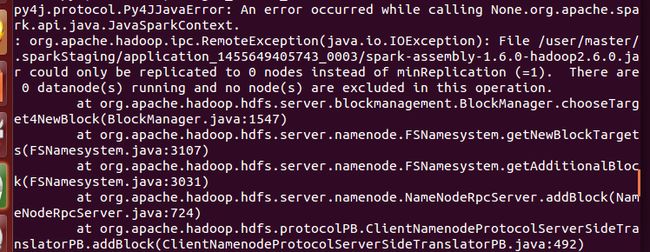
感谢伟大的百度!
Hadoop 异常解决一例.Linux社区.2016.02.18
conf/core-site.xml 中 hadoop.tmp.dir 的值
<configuration>
<property>
<name>
fs.default.name
</name>
<value>
hdfs://localhost:9000
</value>
</property>
<property>
<name>
hadoop.tmp.dir
</name>
<value>
/home/dhfs/tmp
</value>
</property>
</configuration>当时偷懒没有做,自己种的苦自己吃。
Note_7
网上的资源分为第一代的 hadoop 和第二代 YARN 框架下的 hadoop,然后就开始各种百度混乱。
「表格贴不了,重写的话太长了,直接来个链接」
感谢官网的力量!
IBM developerWorks.Hadoop 新 MapReduce 框架 Yarn 详解.2016.02.18
Note_8
重复格式化 hadoop 也会报错!!!再见!
2016.02.22
今天重新捡起了之前做的集群环境,还是决定重新进行配置。然后发现之前所有节点都挂 了的原因是/tmp 文件被我误删了,当然有办法重新将 tmp 中的 pid 和 namenode/datanode 对应,但是最后还是决定重新安装,顺便再熟悉一下安装流程。
1. slp195.hadoop 无法启动 namenode,报错:tmp 目录不存在.2016.02.22
2. 误删/tmp 导致 hadoop 无法启停, jsp 无法查看的解决方法.2016.02.22
2016.02.23
spark-shell --master yarnhttp://192.168.119.141:50070
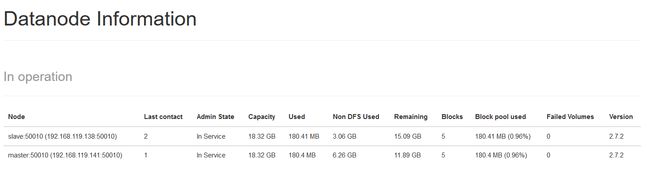
「刚才–把整个一篇博客洗掉了!!!呵呵,就这样吧,换一篇再写比较保险。。」