深度学习算法实践10---卷积神经网络(CNN)原理
好了,转入正题。我们今天将要研究的是卷积网络(CNN),这是深度学习算法应用最成功的领域之一,主要用于图像和视频识别领域。
在讨论卷积网络(CNN)之前,我们先来根据我们的常识,来讨论一下怎样可以提高图像识别的准确率。我们以印刷字母识别为例,假设我们需要网络识别大写字母A,我们给网络的训练样本可能是这样的:

但是我们实际需要识别的图片却可能是这样的:

根据我们的经验,如果可以把字母移到视野的中心去,识别的难度将下降很多,有利于提高识别率。
在这种情况下,如果我们能把图像变为标准大小,则可以提高相应的识别率。
对于真识的物体,从不同角度来看,会有不同的表现,即使对于字母识别而言,字母也能出现旋转的情况:

如果可以将图像旋转过来,将可以极大的提高识别率。
以上各种方式,在实际的图像识别领域,通常是以组合形式出现的,即图像中的元素,需要经过一系列的平移、旋转、缩放后,才能得到与训练样本相似的标准图像,因此在传统的图像识别中,需要对图像进行预处理,达到这一目的。在神经网络进行图像识别中,我们也希望神经网络可以自动处理这些变换,用学术术语来讲,就是具有平移、旋转、缩放的不变性,卷积网络(CNN)就是为解决这一问题而提出一种架构。
那么怎样才能让神经网络具有我所希望的这种变换不变性呢?我们知道,神经网络的兴起,很大程度上是仿生学在人工智能领域的应用,我们用人工神经元模型及其连接,来模仿人类大脑,解决一些常规方法不能解决的复杂问题。对于图像识别而言,神经网络的研究人员,也希望通过模拟大脑视觉皮层的处理机制,来提高图像识别的准确率。
根据Hubel and Wiesel对猫的视觉皮层的研究表明,视觉皮层细胞会组成视觉接收域,只负责对一部分图像信号的处理,处理局部的空间信息,例如图像在的边缘识别等。同时视觉皮层中存在两类细胞,一类细胞是简单细胞,主要用于识别图像边缘等基本信息,还有一类复杂细胞,具有位置不变性,可以识别各种高级的图像信息。
以上述发现为指导,研究人员提出了卷积神经网络(CNN)模型,主要包括两大方面特性:第一是层间稀疏连接,第二是共享连接权值。
层间稀疏连接主要是想要模拟大脑视觉皮层的接收域,以具有简单细胞和复杂细胞两类不同细胞,分别处理局部细节和全局空间不变性。首先我们将图像像素分为3*3的区域,所以对于l=1的输入层而言,这9个像素连接到9个输入层神经元,而这9个神经元,只连接到l=2上的一个神经元,如下图所示:注意由于我们画的是二维图,因此只显示面对我们的三个神经元,如图所示:

如上图所示,每上一层,都只与其底层3*3的神经元相连接,这样对最上层神经元,其对应的视觉接收域将变为9*9。利用上述结构,可以采用多层来表示原来的图像信息,底层神经元主要负责边缘等基本信息的识别,而越往高层走,其识别的级别越高,最上层则可以表达为我们希望区分的类别。这其实与传统的数字图像处理中,金字塔模型比较类似,解决的是同一类问题。
卷积网络的第二个特征是共享连接权值,如图所示:
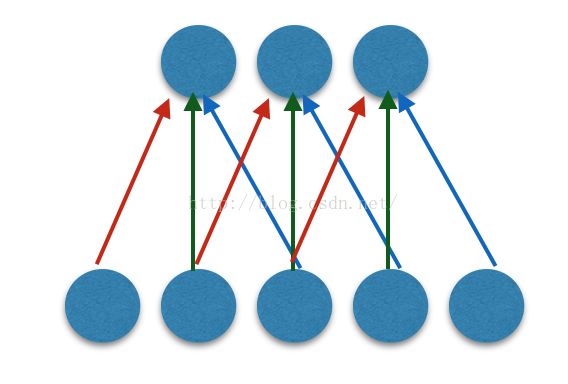
图中不同颜色的连接,具有相同的连接权值。因此,在我们的卷积神经网络(CNN)实现中,考虑到这种情况,需要对原来的算法进行修改,将以单个权值求导变为对三个权值之和进行求导,将在下一篇博文中详述。
通过共享权值模式,可以使卷积神经网络(CNN)识别出图像中的物体,而与物体的空间位置无关,即实现本文开头所提到的旋转、平移、缩放的不变性,这对于在图像识别领域经常出的物体在图像中的位置变化,大小变化,观察角度变化,所造成了识别困难,具有非常好的解决效果。同时,由于权值共享,减少了网络的参数个数,也大提高了网络的学习效率,因此成为卷积神经网络(CNN)的一个事实上的标准。
在讲完了卷积神经网络(CNN)的基本原理之后,自然就是怎么利用Theano这样的平台,来实现自己的卷积神经网络(CNN),对于这一问题,我们将在下一篇博文中进行讨论。