判别模型的玻尔兹曼机论文源码解读
前言
三号要去参加CAD/CG会议,投了一篇关于使用生成模型和判别模型的RBM做运动捕捉数据风格识别的论文。这段时间一直搞卷积RBM了,差点把原来的实验内容都忘记了,这里复习一下判别式玻尔兹曼机的训练流程。
国际惯例,贴几个链接:
论文1——Energy Based Learning Classification task using Restricted Boltzmann Machines
链接:http://pan.baidu.com/s/1i5foeEx 密码:flq7
论文2——Classification using Discriminative Restricted Boltzmann Machines
链接:http://pan.baidu.com/s/1qYGT9z2 密码:hebj
代码——RBM-on-Classification
链接:http://pan.baidu.com/s/1qXWmwTQ 密码:xh12
数据——mnist手写数字数据库
链接:http://pan.baidu.com/s/1boGxPxX 密码:0l25
本文主要是结合论文1及其代码对判别式限制玻尔兹曼机进行解读,代码主要使用在手写数字识别mnist数据库中。
先画一下代码对应的模型结构图
第一步
从主函数入手:trainingClassRBM.m
首先是一系列的初始化,就不说了,主要包含学习率、动量项、权重衰减、分批大小、训练次数,随机初始化权重和偏置等。这里主要关注两行程序:
discrim = 1; % 1 to activate the discriminative learning, 0 otherwise freeenerg = 1; % if discrim is zero but one want to compute the free energy
对于这两句话,可以翻开论文1的第五章(第11页)说过这样一句话:
大概意思就是,为了解决特定的分类问题,我们可以简单地定义一个目标函数去进行最小化,进而得到RBM的模型参数。而目标函数可以选择三种:
1、生成模型的训练目标函数
2、判别模型的训练目标函数
3、混合模型的训练目标函数
显然,根据代码,可以发现程序使用了变量discrim来控制是否使用第三种方法,如果discrim=1则使用第三种目标函数,如果discrim=0则使用第一种目标函数。
此后也进行了数据的分批处理和验证集的选取
data_valid = data(end - valid_size + 1 : end, : ); label_valid = labels(end - valid_size + 1 : end, : ); %convert y in the notetion one out of number of classes lab = boolean(set_y(labels(1:end - valid_size,:), num_class)); %convert the dataset in batches [batch_data, batch_labels , batch_size] = ... createBatches(data(1:end - valid_size,:), lab, num_batch);
第二步
正式进入第一层for循环,用于控制训练次数,每次训练完毕都会输出相应的几个信息,包含重构误差,验证集误差,自由能变化。
sum_rec_error = 0; sum_class_error = 0; sum_tot_free_energ = 0;下一句就是在进行第五次迭代时候,将动量项改变
if i_epoch == 5
momentum = final_momentum;
end;并且使用模拟退火(simulated annealing)算法降低学习率
%simulated annealing gamma = (init_gamma) / (1 + (i_epoch - 1) / tau);
第三步
正式进入内层循环对数据的分配处理,每次只取一批数据,大小为100(最后一批大小根据情况而定)
x = batch_data{iBatch}';
y = batch_labels{iBatch}';
batch_size=size(x,2);进入生成模型的计算,即计算第一步提到的第一个目标函数对应的模型参数更新。
首先计算隐藏层的激活概率值P(h|x,y),这就是在RBM中常说的positive phase根据文章可以得到
hprob = prob_h_given_xy(x, y, w, u, b_h);其中函数prob_h_given_xy为:
function [ prob ] = prob_h_given_xy( x, y, w, u, b_h ) <span style="white-space:pre"> </span>prob = sigmf(bsxfun(@plus, w * x + u * y, b_h), [1 0]); end随后进行隐单元的随机激活,这是RBM中经常出现的一步骤,我们称为激活状态:
h = sampling(hprob);激活函数实现如下:
function [ samp ] = sampling( p ) <span style="white-space:pre"> </span>samp = p > rand(size(p)); end然后便是对应的negative phase,使用得到的隐单元状态反向计算x和y单元数据
根据论文介绍的激活函数
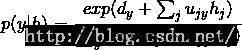
可以找到对应的激活函数程序写法:
计算P(x|h),很简单,直接计算权重乘以隐单元的激活状态(并非激活概率值)然后加上输入层偏置即可。
function [ prob ] = prob_x_given_h( h, w, b_x ) <span style="white-space:pre"> </span>prob = sig(bsxfun(@plus, w' * h, b_x)); end计算P(y|h),稍微复杂点,在分母的处理上,需要进行加和,u'*h计算得到的矩阵大小是类别数*批大小,实验中大小是30*716,而sum是将所有行加到第一行,也就是说对每一个样本计算得到的标签层单元数据进行加和,整个过程类似于进行了归一化。
function [ prob ] = prob_y_given_h( h, u , b_y ) <span style="white-space:pre"> </span>prob_not_norm = exp(bsxfun(@plus, u' * h, b_y)); <span style="white-space:pre"> </span>norm_factor = sum(prob_not_norm); <span style="white-space:pre"> </span>prob = bsxfun(@rdivide, prob_not_norm, norm_factor); end计算得到x和y的激活概率值之后同样需要激活状态
xrprob = prob_x_given_h( h, w, b_x ); yrprob = prob_y_given_h( h, u, b_y ); xr = sampling(xrprob); yr = sampling_y(yrprob);进行negative phase的最后一步,利用新的x和y的状态值(0或者1)去计算隐层的激活概率值
hrprob = prob_h_given_xy( xr, yr, w, u, b_h);根据以上计算的positive phase和negative phase相关值计算生成模型各参数的更新梯度,主要包含隐层至输入层的连接权重w,隐层至标签层的连接权重v,输入层偏置b_x,隐藏层偏置b_h,标签层偏置b_y。注意更新的时候用的是激活概率值去更新,而非激活状态值去更新。
g_w_gen = (hprob * x' - hrprob * xrprob') / batch_size; g_u_gen = (hprob * y' - hrprob * yrprob') / batch_size; g_b_x_gen = (sum(x,2) - sum(xrprob,2)) / batch_size; g_b_y_gen = (sum(y,2) - sum(yrprob,2)) / batch_size; g_b_h_gen = (sum(hprob,2) - sum(hrprob,2)) / batch_size;
第四步
进入判别模型的目标函数计算,上面第一节介绍的第二个目标函数。
当然首先就是判断我们是否选择使用判别模型,以及初始化判别模型计算中的相关参数,包含隐层偏置梯度,两个权重w和u的梯度
if (discrim || freeenerg)
%initialization of the gradients
g_b_h_disc_acc = 0;
g_w_disc_acc = 0;
g_u_disc_acc = zeros(h_size,num_class);特别注意,此处是没有输入层偏置的,详细可看论文1中的这样一句话:

意思就是b(文章的b是输入层的偏置)的梯度为0,因为计算P(y|x)的时候并没有用到输入层的偏置。
让我们看看P(y|x)的计算方法
其中F 就代表自由能量(free energy)。
还是写一下比较好,后面的代码会单独计算这个自由能量,其中dy是标签层偏置
后面的步骤便是逐步实现这个采样函数
注意这里的softplus也是一个函数,而非简单的加法,具体介绍点击此处
![]()
①首先发现式子中始终有w*x这一项,所以提出来计算一下,避免后面的重复计算
%ausiliary variables
w_times_x = w * x;②接下来计算自由能量函数
for iClass= 1:num_class
o_t_y(:,:,iClass) = bsxfun(@plus, b_h + u(:,iClass), w_times_x );
neg_free_energ(iClass,:) = b_y(iClass) + sum(log(1 + exp(o_t_y(:,:,iClass))));
end;
注意这里的两个变量的维度:
o_t_y维度大小是800*716*30,分别代表隐单元神经元个数、一批样本数、标签总数,就像对隐层求了30个800*716的单元数值,然后后面计算的时候也确实如此,每次计算都用了一个for循环对第三个维度的800*716矩阵分别遍历,应该就是为了计算此样本属于每一个标签的概率。
neg_free_energ大小是30*716,分别代表标签总数、样本总数
计算的时候是依次计算标签层每个神经元所代表的所有样本之和。有点像先用x和y计算得到h,然后将h经过softplus映射,最后将每一个样本的隐层800个单元求和,得到一个样本在对应的标签单元的值。比如o_t_y计算iClass=1时候得到的其实是一个800*716的矩阵,然后经过sum得到1*716的向量,直接作为标签层的第一个单元的所有样本的值即可。
然后记录了一下当前批数据的总共的能量和,用于与下一批的自由能量和相加
sum_tot_free_energ = sum_tot_free_energ + sum(-neg_free_energ(y));至此“ if (discrim || freeenerg)”中的freeenerg计算完毕。
③接下来就是计算discrim对应的参数更新梯度了
主要就是计算P(y|x)根据上面提到的式子。
程序中首先对求得的neg_free_energ进行了零均值化,并计算出了分子的值
med = mean2(neg_free_energ);
p_y_given_x = exp(neg_free_energ - med);利用分子的值,计算分子/分母的值,注意这里的加是将每个样本对应的30个标签层值相加,即sum(p_y_given_x)的结果是将30*716加和成了1*716维度的向量
p_y_given_x = bsxfun(@rdivide, p_y_given_x, sum(p_y_given_x));④最后就是计算梯度了
首先计算标签层的梯度,按照原文的公式
![]()
说白了就是用原始标签减去P(y|x)推理得到的标签值,最后计算一下加和即可,便得到了标签层偏置更新梯度
dif_y_p_y = y - p_y_given_x;
g_b_y_disc_acc = sum(dif_y_p_y,2);
随后便是计算剩下的三个量权重w、v和隐层偏置b_h的梯度,查看论文1的计算方法

其中
相关的计算程序如下:
首先计算第一项和第二项的 O 函数
sig_o_t_y = sig(o_t_y(:,:,iClass)); sig_o_t_y_selected = sig_o_t_y(:,y(iClass,:));然后分别套入对b_h、w、u的计算中
g_b_h_disc_acc = g_b_h_disc_acc + sum(sig_o_t_y_selected, 2) - sum(bsxfun(@times, sig_o_t_y, p_y_given_x(iClass,:)),2); %update the gradient of w fot the class 'iClass' g_w_disc_acc = g_w_disc_acc + sig_o_t_y_selected * x(:,y(iClass,:))' - bsxfun(@times, sig_o_t_y, p_y_given_x(iClass,:)) * x'; %update the gradient of u fot the class 'iClass' g_u_disc_acc(:,iClass) = sum(bsxfun(@times, sig_o_t_y, dif_y_p_y(iClass,:)), 2);注意这两部分代码要用一个for循环包含起来
for iClass= 1:num_class主要也就是上面说过的,对o_t_y(维度为隐层单元数*一批样本数*标签类别总数)的第三维进行遍历,每次遍历得到的隐单元数*批样本数作为隐层单元即sig_o_t_y(代码维度是800*716),然后从中抽取出标签为iClass的样本(比如716个样本中,有29个样本标签为当前循环的iClass)得到sig_o_t_y_selected(iClass=1时文章维度为800*29)这样就比较好理解了,就像生成模型的RBM一样:
计算隐层偏置b_h的时候,计算sig_o_t_y_selected与sig_o_t_y*P(y|x)的差值即可;
计算连接权重w的时候,计算sig_o_t_y_selected*x_selected(这个变量代表批样本x中标签为iClass的样本矩阵)与sig_o_t_y*P(y|x)*x对应的差值即可;
计算连接权重u的时候,只需计算sig_o_t_y与dif_y_p_y(iClass,:)的乘积即可,因为在计算dif_y_p_y的时候,已经计算过差值了,所以没有像上面计算b_h和w一样去做差。
⑤全部计算完了,就更新一下判别模型中的几个参数吧
g_b_y_disc = g_b_y_disc_acc / batch_size; g_b_h_disc = g_b_h_disc_acc / batch_size; g_w_disc = g_w_disc_acc / batch_size; g_u_disc = g_u_disc_acc / batch_size;
第五步
利用第一步介绍的目标函数三进行全局梯度更新
delta_w = delta_w * momentum + ...
gamma * (discrim * g_w_disc + alpha * g_w_gen - weight_cost * w);
delta_u = delta_u * momentum + ...
gamma * (discrim * g_u_disc + alpha * g_u_gen - weight_cost * u);
delta_b_x = delta_b_x * momentum + ...
gamma * alpha * g_b_x_gen;
delta_b_y = delta_b_y * momentum + ...
gamma * (discrim * g_b_y_disc + alpha * g_b_y_gen);
delta_b_h = delta_b_h * momentum + ...
gamma * (discrim * g_b_h_disc + alpha * g_b_h_gen);
w = w + delta_w;
u = u + delta_u;
b_x = b_x + delta_b_x;
b_y = b_y + delta_b_y;
b_h = b_h + delta_b_h;后面做了一个平均,表示没太懂是干什么用的,好像是削减梯度?而且在每次迭代输出的验证集误差的时候使用的依旧是上面的b_y, b_h, w, u 而非做平均的b_y_avg, b_h_avg, w_avg, u_avg 。这个还有待探讨。
第六步
获得所有参数以后需要进行识别,很简单,有一个输入testdata,对应的标签testlabels,总类别数目num_class,对应的模型参数b_y, b_h, w, u,然后利用能量函数F的计算得到样本属于每个标签的概率,前面也说了,neg_free_energ的大小是标签数*样本数,这样就能得到每一个样本对应的每一个标签的概率是对少了,取最大的那个概率就是了。
function [ err ] = predict( testdata, testlabels, num_class, b_y, b_h, w, u )
numcases= size(testdata, 1);
w_times_x = w * testdata';
neg_free_energ = zeros(num_class, numcases);
for iClass= 1:num_class
neg_free_energ(iClass,:) = b_y(iClass) + sum(log(1 + ...
exp(bsxfun(@plus, b_h + u(:,iClass), w_times_x ))));
end;
[~, prediction] = max(neg_free_energ);
err = sum(prediction ~= testlabels') / numcases * 100;
end
第七步
补充一下,如何看模型的效果好坏呢?
首先重构误差不必多说,肯定是慢慢降低
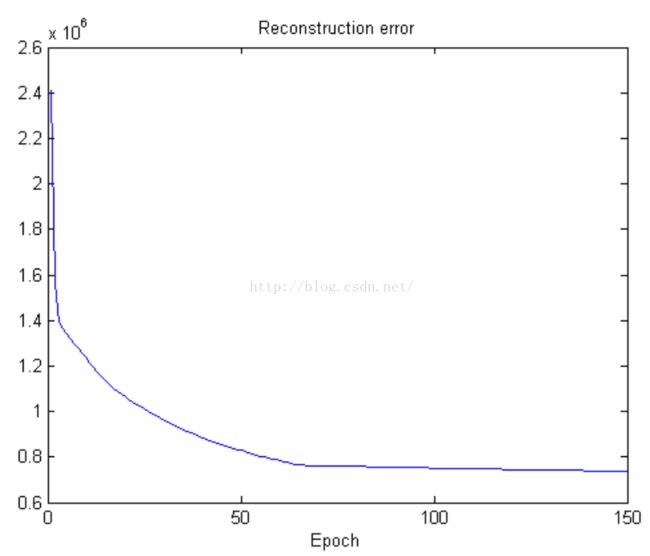
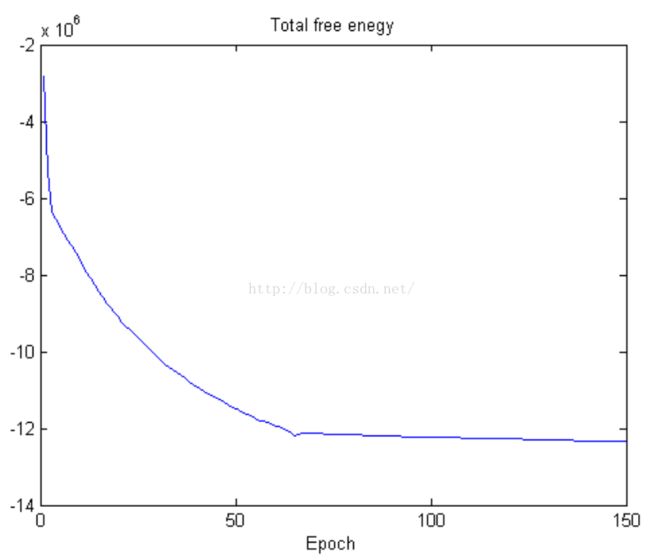
其次就是自由能量了,根据RBM的描述,系统最稳定的时刻就是能量最少的时候。
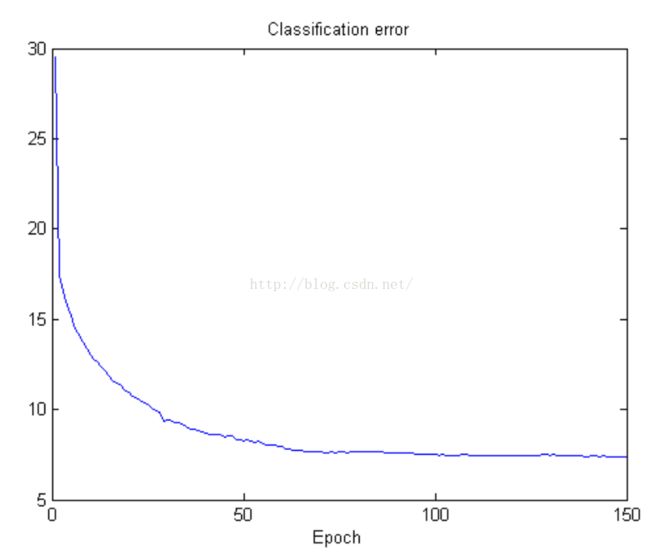
当然咯,分类误差肯定也是降低啦
还有,有时候能量会突然升高,这时候不要慌,先等等,看看是否一直升高,有可能在某次迭代完成就下降了呢,类似于这样