Hadoop集群搭建示意图即相应配置文件汇总
核心内容:
1、Hadoop1.1.2伪分布(或集群)搭建核心配置文件
2、Hadoop2.4.1伪分布(或集群无HA)搭建核心配置文件
3、Hadoop2.4.1 + HA 集群搭建核心配置文件
| 1、Hadoop1.1.2伪分布(或集群)搭建核心配置文件 |
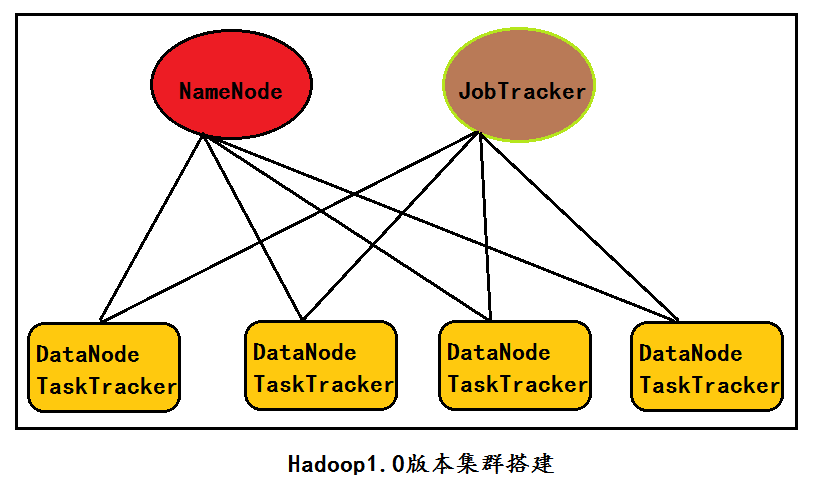
hadoop1.1.2伪分布(集群)搭建
前期准备(略)
安装hadoop1.1.2
1、解压缩
2、修改配置文件
----------------------core-site.xml---------------------
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop11:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
----------------------hdfs-site.xml---------------------
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
----------------------mapred-site.xml-------------------
<property>
<name>mapred.job.tracker</name>
<value>hadoop11:9001</value>
</property>
---------------------------------------------------------
3、启动hadoop
start-all.sh (start-dfs.sh+start-mapred.sh)
stop-all.sh (stop-dfs.sh+stop-mapred.sh)
进程5个
NameNode
SecondaryNode
Datanode
JobTracker
TaskTracker| 2、Hadoop2.4.1伪分布(或集群无HA)搭建核心配置文件 |
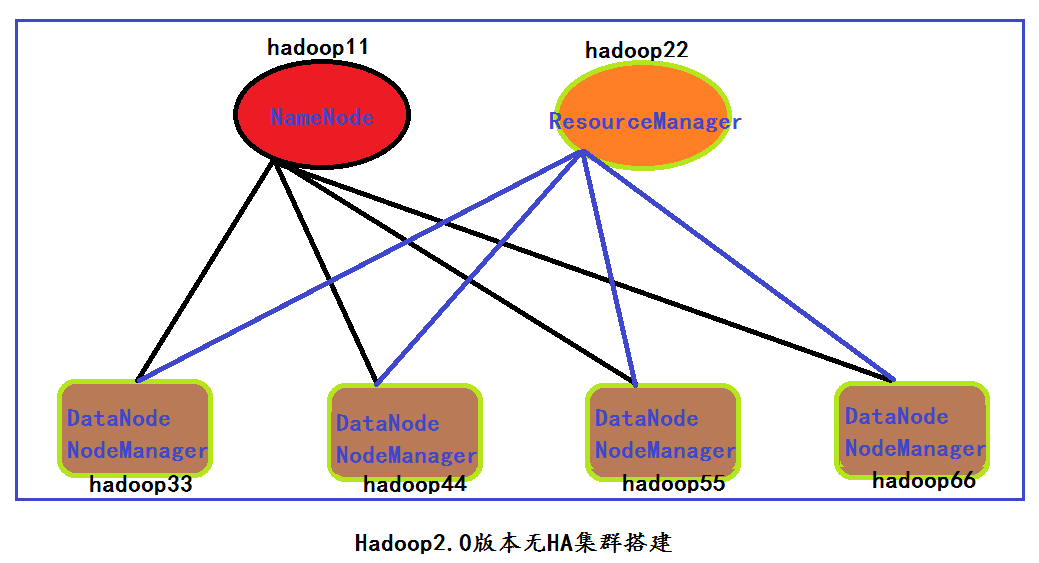
hadoop2.4.1伪分布搭建(不用HA机制:伪分布也只能有一个namenode)
前期准备(略)
安装hadoop2.4.1
1>解压缩
2>修改配置文件
-----------hadoop-env.sh------------------
JAVA_HOME=/usr/local/jdk
-------core-site.xml----------------------
注:在此采用的是hadoop1.0中hdfs的配置方式,而没有采用名字联盟的方式。
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop11:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
-------hdfs-site.xml----------------------
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
-------mapred-site.xml----------------------
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
-------yarn-site.xml----------------------
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop22</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
----------
3>启动
start-all.sh(start-dfs.sh+start-yarn.sh)
stop-all.sh(stop-dfs.sh+stop-yarn.sh)
显示进程:
4334 SecondaryNameNode
4781 Jps
4614 NodeManager
4188 DataNode
4074 NameNode
4474 ResourceManager
----------| 3、Hadoop2.4.1 + HA 集群搭建核心配置文件 |

![]()
hadoop2.4.1集群搭建(用HA机制)
前期准备(略)
安装hadoop2.4.1
1>解压缩
2>修改配置文件
原则:
1>NameNode节点的位置在core-site.xml中指定
2>ResourceManager(JobTracker)节点的位置在yarn-site.xml中指定
3>Datanode和NodeManager(TaskerTracker)节点的位置在slaves中指定
4>Journalnode节点的位置在hdfs-site.xml中指定
5>Zookeeper节点的位置在core-site.xml中指定
集群描述:(6个机器)
NameNode: hadoop11 hadoop22
DataNode: hadoop44 hadoop55 hadoop66
JournalNode: hadoop44 hadoop55 hadoop66
ResourceManager: hadoop33
NodeManager: hadoop44 hadoop55 hadoop66
Zookeeper: hadoop44 hadoop55 hadoop66
--------------------core-site.xml------------------
//cluster1在这里为一个虚拟的名称
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop44:2181,hadoop55:2181,hadoop66:2181</value>
</property>
--------------------hdfs-site.xml------------------
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>hadoop11,hadoop22</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.hadoop11</name>
<value>hadoop11:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.hadoop11</name>
<value>hadoop11:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.hadoop22</name>
<value>hadoop22:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.hadoop22</name>
<value>hadoop22:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop44:8485;hadoop55:8485;hadoop66:8485/cluster1</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.cluster1</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/tmp/journal</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
----------------------------mapred-site.xml------------------------------------------------------
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
----------------------------yarn-site.xml---------------------------------------------------------
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop33</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
---------------------------slaves----------------------------------------------------------------
hadoop44
hadoop55
hadoop66
--------------------------------------------------------------------------------------------------
3>启动(注意:第一次启动集群的时候必须这个顺序)
1> 启动zk集群:zkServer.sh start (分别)
2> 格式化 Zookeeper: hdfs zkfc -formatZK 备注:(在cluster中的两个Namenode节点中任选一个去执行即可) zkfc主要负责状态管理
3> hadoop-daemon.sh start journalnode(分别) 备注:本步骤必须进行操作
格式化hdfs:注意cluster中的两个NameNode都要格式化
4> hdfs(hadoop) namenode -format 备注:(格式化namenode1)
5> hdfs(hadoop) namenode -bootstrapStandby 备注:(格式化namenode2) 呵呵,我几次都是失败,而后是通过复制tmp成功的
启动hdfs
6> start-dfs.sh(active和standy均可)
启动yarn
7> start-yarn.sh(RM)
启动NameNode中监控的ZKFC进程
8> hadoop-daemon.sh start zkfc 备注:两个NameNode节点都要启动
最终启动之后的效果图:
[root@hadoop11 mapreduce]# jps
47144 NameNode
47507 Jps
47443 DFSZKFailoverController
[root@hadoop22 local]# jps
3749 Jps
3570 NameNode
3699 DFSZKFailoverController
[root@hadoop33 local]# jps
17741 Jps
17458 ResourceManager
[root@hadoop44 bin]# jps
18286 JournalNode
18381 NodeManager
18507 Jps
17362 QuorumPeerMain
18196 DataNode
[root@hadoop55 local]# jps
17738 NodeManager
17639 JournalNode
17863 Jps
17549 DataNode
16789 QuorumPeerMain
[root@hadoop66 hadoop]# jps
17600 JournalNode
17825 Jps
17510 DataNode
17699 NodeManager
16802 QuorumPeerMain
| 注意:第二次以后启动的顺序 |
①启动ZooKeeper集群 zkServer.sh start
②启动HDFS 集群 start-dfs.sh
③启动YARN集群 start-yarn.sh

④启动cluster1中的两个监听器:
hadoop-daemon.sh start zkfc 备注:两个NameNode节点都要启动
关闭的顺序:
①关闭两个监听器: hadoop-daemon.sh stop zkfc
②关闭HDFS集群
③关闭YARN集群
④关闭ZK集群
如有问题,欢迎留言指正!