跟着Innost理解下ContentProvider
重点分析ContentProvider、SQLite、Cursor query、close函数的实现及ContentResolver openAssetFileDescriptor函数。四条分析路线。
· 第一条:以客户端进程通过query来查询相关信息为入口点,分析系统如何创建和启动ContentProvider。此分析路线着重关注客户端进程、ActivityManagerService及MediaProvider所在进程间的交互。
· 第二条:沿袭第一条分析路径,但是将关注焦点转移到SQLiteDatabase如何创建数据库的分析上。另外,本条路线还将对SQLite进行相关介绍。
· 第三条:将重点研究Cursor query和close函数的实现细节。
· 第四条:将分析ContentResolver openAssetFileDescriptor函数的实现。
1. ContentProvider的启动及创建
第一、二、三条分析路线都将以下面这段示例为参考。
void QueryImage(Context context){
//①得到ContentResolver对象
ContentResolver cr = context.getContentResover();
Uri uri = MediaStore.Images.Media.EXTERNAL_CONTENT_URI;
//②查询数据库
Cursorcursor = MediaStore.Images.Media.query(cr,uri,null);
cursor.moveToFirst();//③移动游标到头部
......//从游标中取出数据集
cursor.close();//④关闭游标
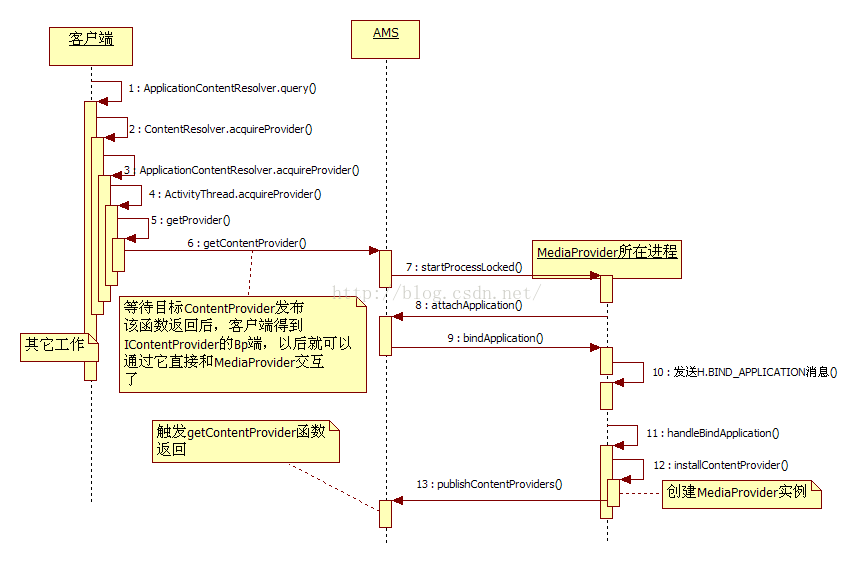
}客户端(即运行本示例的进程)查询(query)的目标ContentProvider是MediaProvider,它运行于进程android.process.media中。假设目标进程此时还未启动。
本节的关注点集中在:
· MediaProvider所在进程是如何创建的?MediaProvider又是如何创建的?
· 客户端通过什么和位于目标进程中的MediaProvider交互的?
1.1 Context的getContentResolver函数分析
Context的getContentResolver最终会调用它所代理的ContextImpl对象的getContentResolver函数. 该函数直接返回mContentResolver,此变量在ContextImpl初始化时创建. mContentResolver的真实类型是ApplicationContentResolver,它是ContextImpl定义的内部类并继承了ContentResolver。
1.2 ContentResolver.query函数分析
ContentResolver的query将调用acquireProvider,该函数定义在ContentResolver类中. acquireProvider由ContentResolver的子类实现,在本例中该函数由ApplicationContentResolver定义。
ApplicationContentResolver.acquireProvider()将调用AcitvityThread.acquireProvider();
1.3 AcitvityThread.acquireProvider()
通过调用getProvider()取得IContentProvider,然后将这个ContentProvider 保存到客户端进程的mProviderRefCountMap;
1.3.1 getProvider()
查询该应用进程是否已经保存了用于和远端ContentProvider通信的对象。如果存在,则直接返回;如果不存在,则调用AMS.getContentProvider()获取ContentProviderHolder,然后在当前应用进程调用installProvider()安装。
1.4 AMS.getContentProvider()
getContentProvider的功能主要由getContentProviderImpl函数实现,故此处可直接对它进行分析。
1.4.1 getContentProviderImpl启动目标进程
为目标ContentProvider(即MediaProvider)创建一个ContentProviderRecord对象。
如果目标进程没有启动,则启动之。然后AMS等待目标进程发布相应的目标ContentProvider。
1.4.2 目标进程创建目标ContentProvider
目标进程启动后要做的第一件大事就是调用AMS的attachApplication函数,该函数的主要功能由attachApplicationLocked完成。
booleanattachApplicationLocked()通过PKMS查询运行在该进程中的CP信息,并保存到mProvidersByClass中;调用目标应用进程的bindApplication函数,此处将providers信息传递给目标进程。
再来看目标进程bindApplication的实现,其内部最终会通过handleBindApplication函数处理。
AMS传递过来的ProviderInfo列表将由目标进程的installContentProviders处理。
1.4.3 installProvider()
installProvider是一个通用函数,不论客户端使用远端的CP还是目标进程安装运行在其上的CP上,最终都会调用它,只不过参数不同罢了:
· 客户端进程调用installProvider函数时,该函数的第二个参数不为null。
· 目标进程调用installProvider函数时,该函数的第二个参数硬编码为null。
1.4.4 IContentProvider Hierachy
· 每个ContentProvider实例中都有一个mTransport成员,其类型为Transport。
· Transport类从ContentProviderNative派生。由图7-2可知,ContentProviderNative从Binder类派生,并实现了IContentProvider接口。结合前面的代码,IContentProvider将是客户端进程和目标进程交互的接口,即目标进程使用IContentProvider的Bn端Transport,而客户端使用IContentProvider的Bp端,其类型是ContentProviderProxy(定义在ContentProviderNative.java中)。

客户端如何通过IContentProvider query函数和目标CP进程交互的呢?其流程如下:
· CP客户端得到IContentProvider的Bp端(实际类型是ContentProviderProxy),并调用其query函数,在该函数内部将参数信息打包,传递给Transport(它是IContentProvider的Bn端)。
· Transport的onTransact函数将调用Transport的query函数,而Transport的query函数又将调用ContentProvider子类定义的query函数(即MediaProvider的query函数)。
1.4.5 AMS.pulishContentProviders()
要把目标进程的CP信息发布出去,需借助AMS 的pulishContentProviders函数。
1.5 客户端进程和目标CP紧密的关系
· 该关系的建立是在AMS getContentProviderImpl函数中调用incProviderCount完成的,关系的确立以ContentProviderRecorder保存客户端进程的ProcessRecord信息为标识。
· 一旦CP进程死亡,AMS能根据该ContentProviderRecorder中保存的客户端信息找到使用该CP的所有客户端进程,然后再杀死它们。
客户端能否撤销这种紧密关系呢?答案是肯定的,但这和Cursor是否关闭有关。这里先简单描述一下流程:
· 当Cursor关闭时,ContextImpl的releaseProvider会被调用。根据前面的介绍,它最终会调用ActivityThread的releaseProvider函数。
· ActivityThread的releaseProvider函数会导致completeRemoveProvider被调用,在其内部根据该CP的引用计数判断是否需要调用AMS的removeContentProvider。
· 通过AMS的removeContentProvider将删除对应ContentProviderRecord中此客户端进程的信息,这样一来,客户端进程和目标CP进程的紧密关系就荡然无存了。
2 SQLite创建数据库分析
本节的目标是分析MediaProvider如何利用SQLite创建数据库,同时还将介绍和SQLite相关的一些知识点。
2.1 SQLite及SQLiteDatabase家族
Innost总结了SQLite具有的两个特点:
· 从代码上看,SQLite所有的功能都实现在Sqlite3.c中,而头文件Sqlite3.h定义了它所支持的API。其中,Sqlite3.c文件包含12万行左右的代码,相当于一个中等偏小规模的程序。
· 从使用者角度的来说,SQLite编译完成后将生成一个libsqlite.so,大小仅为300多KB。
SQLite API的使用主要集中在以下几点上:
· 创建代表指定数据库的sqlite3实例。
· 创建代表一条SQL语句的sqlite3_stmt实例,在使用过程中首先要调用sqlite3_prepare将其和一条代表SQL语句的字符串绑定。如该字符串含有通配符“?”,后续就需要通过sqlite3_bind_xxx函数为通配符绑定特定的值以生成一条完整的SQL语句。最终调用sqlite3_step执行这条语句。
· 如果是查询(即SELECT命令)命令,则需调用sqlite3_step函数遍历结果集,并通过sqlite3_column_xx等函数取出结果集中某一行指定列的值。
· 最后需调用sqlite3_finalize和sqlite3_close来释放sqlite3_stmt实例及sqlite3实例所占据的资源。
SQLite API的使用非常简单明了。不过很可惜,这份简单明了所带来的快捷,只供那些Native层程序开发者独享。对于Java程序员,他们只能使用Android在SQLite API之上所封装的SQLiteDatabase家族提供的类和相关API。笔者心中对这个封装的评价只有一个词 “叹为观止”,综合考虑到架构及系统的稳定性和可扩展性等各种情况,Android在 SQLite API之上进行了面向对象的封装和解耦等设计,最终呈现在大家面前的是一个庞大而复杂的SQLiteDatabase家族,其成员有61个之多(参阅frameworks/base/core/java/android/database目录中的文件)。

· SQLiteOpenHelper是一个帮助(Utility)类,用于方便开发者创建和管理数据库。
· SQLiteQueryBuilder是一个帮助类,用于帮助开发者创建SQL语句。
· SQLiteDatabase代表SQLite数据库,它内部封装了一个Native层的sqlite3实例。
· Android提供了3个类SQLiteProgram、SQLiteQuery和SQLiteStatement用于描述和SQL语句相关的信息。从图可知,SQLiteProgram是基类,它提供了一些API用于参数绑定。SQLiteQuery主要用于query查询操作,而SQLiteStatement用于query之外的一些操作(根据SDK的说明,如果SQLiteStatement用于query查询,其返回的结果集只能是1行*1列)。注意,在这3个类中,基类SQLiteProgram将保存一个指向Native层的sqlite3_stmt实例的变量,但是这个成员变量的赋值却和另外一个对开发者隐藏的类SQLiteComplieSql有关。从这个角度看,可以认为Native层sqlite3_stmt实例的封装是由SQLiteComplieSql完成的。这方面的知识在后文进行分析时即能见到。
· SQLiteClosable用于控制SQLiteDatabase家族中一些类的实例的生命周期,例如SQLiteDatabase实例和SQLiteQuery实例。每次使用这些实例对象前都需要调用acquireReference以增加引用计数,使用完毕后都需要调用releaseReferenece以减少引用计数。
2.2 ContentProvider 创建数据库
两个关键点,分别是:
· 构造一个DatabaseHelper对象。
· 调用DatabaseHelper对象的getWritableDatabase函数得到一个代表SQLite数据库的SQLiteDatabase对象。
2.2.1 DatabaseHelper分析
DatabaseHelper从SQLiteOpenHelper派生。
2.2.1.1 DatabaseHelper构造函数分析
·从SQLiteOpenHelper的构造函数中可知,MediaProvider对应的数据库对象(即SQLiteDatabase实例)并不在该函数中创建。那么,代表数据库的SQLiteDatabase实例是何时创建呢?
此处使用了所谓的延迟创建(lazy creation)的方法,即SQLiteDatabase实例真正创建的时机是在第一次使用它的时候,也就是本例中第二个关键点函数getWritableDatabase。
Lazy initialization: 所谓的“重型”资源(如占内存较大或创建时间比较长的资源),是系统开发和设计中常用的一种策略[①]。在使用这种策略时,开发人员不仅在资源创建时“斤斤计较”,在资源释放的问题上也是“慎之又。资源释放的控制一般会采用引用计数技术。
2.2.1.2 getWritableDatabase函数分析
代表数据库的SQLiteDatabase对象是由context openOrCreateDatabase创建的。
2.2.2 ContextImpl openOrCreateDatabase分析
2.2.2.1 openOrCreateDatabase函数分析
其实openDatabase主要就干了两件事情,即创建一个SQLiteDatabase实例,然后调用该实例的dbopen函数。
2.2.2.2. SQLiteDatabase的构造函数及dbopen函数分析
Java层的SQLiteDatabase对象会和一个Native层sqlite3实例绑定,从以上代码中可发现,绑定的工作并未在构造函数中开展。实际上,该工作是由dbopen函数完成的。
使用dbopen函数其实就是为了得到Native层的一个sqlite3实例。另外,Android对SQLite还设置了一些平台相关的函数,这部分内容将在后文进行分析。
2.2.3 SQLiteCompiledSql介绍
Native层sqlite3_stmt实例的封装是由未对开发者公开的类SQLiteCompileSql完成的。由于它的隐秘性,没有在图7-4中把它列出来。现在我们就来揭开它神秘的面纱。
当compile函数执行完后,一个绑定了SQL语句的sqlite3_stmt实例就和Java层的SQLiteCompileSql对象绑定到一起了。
2.2.4 Android SQLite自定义函数介绍
2.2.4.1 触发器介绍
触发器(Trigger)是数据库开发技术中一个常见的术语。其本质非常简单,就是在指定表上发生特定事情时,数据库需要执行的某些操作。
db.execSQL("CREATE TRIGGER IF NOT EXISTSimages_cleanup DELETE ON images " + "BEGIN " + "DELETE FROM thumbnails WHERE image_id = old._id;" +
"SELECT _DELETE_FILE(old._data);" +
"END");上面这条SQL语句是什么意思呢?
· CREATE TRIGGER IF NOT EXITSimages_cleanup:如果没有定义名为images_cleanup的触发器,就创建一个名为images_cleanup的触发器。
· DELETE ON images:设置该触发器的触发条件。显然,当我们对images表执行delete操作时,该触发器将被触发。
BEGIN和END之间则定义了该触发器要执行的动作。从前面的代码可知,它将执行两项操作:
q 删除thumbnails(缩略图)表中对应的信息。为什么要删除缩略图呢?因为原图的信息已经不存在了,留着它没用。
q 执行_DELETE_FILE函数,其参数是old.data。从名字上来看,这个函数的功能应为删除文件。为什么要删除此文件?原因也很简单,数据库都没有该项信息了,还留着图片干什么!另外,如不删除文件,下一次媒体扫描时就又会把它们找到。
2.2.4.2 register_android_functions介绍
3 ContentProvider的query的实现分析
ContentResolver query函数的工作流程:
· 调用远程CP的query函数,返回一个Cursor类型的对象qCursor。
· 该函数最终返给客户端的是一个CursorWrapperInner类型的对象。
3.1 提取query关键点
序列图来展示query调用顺序,其中ContentProvider框和MediaProviderer框代表同一个对象。
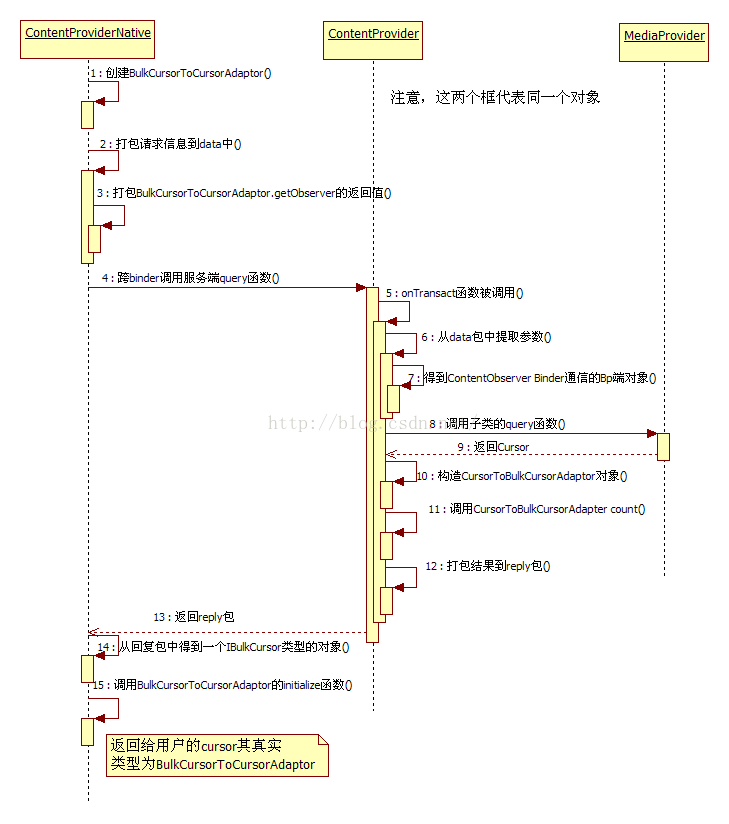
几个拦路虎,它们分别是:
· 客户端创建的BulkCursorToCursorAdaptor、从服务端query后返回的IBulkCursor。
· 服务端创建的CursorToCursorAdaptor,以及从子类query函数返回的Cursor。
3.1.1 客户端query关键点
按以前的分析习惯,碰到Binder调用时会马上转入服务端(即Bn端)去分析,但是这个思路在query函数中行不通。为什么?来看IContentProvider Bp端的query函数,它定义在ContentProviderProxy中,还大有文章,其中一共列出了4个关键点。最令人头疼的是其中新出现的两个类BulkCursorToCursorAdaptor和IBulkCursor。此处不必急于分析它们。
3.1.2 服务端query关键点
和客户端对应,服务端的query处理也比较复杂,其中的拦路虎仍是新出现的几种数据类型。
3.2 MediaProvider的query
此次分析的焦点是要搞清query函数返回的Cursor到底是什么。
两个关键点分别是:
· 调用SQLiteQueryBuilder的query函数得到一个Cursor类型的对象。
· 调用Cursor类型对象的setNotificationUri函数。从名字上看,是为该对象设置通知URI。和ContentObserver有关的内容留到其他文章再进行分析。
3.2.1 SQLiteQueryBuilder的query函数分析
3.2.1.1 SQLiteCursorDriver query函数分析
SQLiteCursorDriver的query函数的主要功能就是创建一个SQLiteQuery实例和一个SQLiteCursor实例。至此,我们终于搞清楚了MediaProvider 的query返回的游标对象其真实类型是SQLiteCursor。
3.2.1.2 SQLiteQuery介绍
SQLiteQuery将和一个代表SELECT命令的sqlite3_stmt实例绑定。同时,为了减少创建sqlite3_stmt实例的开销,SQLiteDatabase框架还会把对应的SQL语句和对应的SQLiteCompiledSql对象缓存起来。如果下次执行同样的SELECT语句,那么系统将直接取出之前保存的SQLiteCompiledSql对象,这样就不用重新创建sqlite3_stmt实例了。
3.2.1.3 SQLiteCursor分析
3.2.2 Cursor分析
图中元素较多,包含的知识点也较为复杂,因此必须仔细阅读下文的解释。
query查询(即SELECT命令)的结果和一个Native sqlite_stmt实例绑定在一起,开发者可通过遍历该sqlite_stmt实例得到自己想要的结果(例如,调用sqlite3_step遍历结果集中的行,然后通过sqlite3_column_xxx取出指定列的值)。查询结果集可通过数据库开发技术中一个专用术语——游标(Cursor)来遍历和获取。
图的左上部分是和Cursor有关的类,它们包括:接口类Cursor和CrossProcessCursor、抽象类AbstractCursor、AbstractWindowCursor,以及真正的实现类SQliteCursor。根据前面的分析,SQLiteCursor内部保存一个已经绑定了sqlite3_stmt实例的SQLiteQuery对象,故读者可简单地把SQLiteCursor看成是一个已经包含了查询结果集的游标对象,虽然此时还并未真正执行SQL语句。
如上所述,SQLiteCursor是一个已经包含了结果集的游标对象。从进程角度看,query的结果集目前还属于MediaProvider所在的进程,而本次query请求是由客户端发起的,所以一定要有一种方法将MediaProvider中的结果集传递到客户端进程。数据传递使用的技术很简单,就是大家耳熟能详的共享内存技术。SQLite API没有提供相关的功能,但是SQLiteDatabase框架对跨进程数据传递进行了封装,最终得到了图左上部分的CursorWindow类。其代码中的注释明确表明了CursorWindow的作用:它是“A buffer containing multiplecursor rows”。
认识了CursorWindow,相信读者也能猜出query中数据传递的大致流程了。
MediaProvider将结果集中的数据存储到CursorWindow的共享内存中,然后客户端将其从共享内存中取出来即可。
上述流程描述是对的,但实际过程并非如此简单,因为SQLiteDatabase框架希望客户端看到的不是共享内存,而是一个代表结果集的游标对象,就好像客户端查询的是本进程中的数据库一样。由于存在这种要求[②],Android构造了图右下角的类家族。
其中,最重要的两个类是CursorToBulkCursorAdaptor和BulkCursorToCursorAdatpor。从名字上看,它们采用了设计模式中的Adaptor模式;从继承关系上看,这两个类将参与跨进程的Binder通信(其中客户端使用的BulkCursorToCursorAdaptor通过mBulkCursor与位于MediaProvider所在进程的CursorToBulkCursorAdaptor通信)。这两个类中最重要的是onMove函数,以后我们碰到时再作分析。
另外,图中右上角部分展示了CursorWrapperInner类的派生关系。CursorWrapperInner类是ContentResolver query函数最终返回给客户端的游标对象的类型。CursorWrapperInner的目的应该是拓展CursorToBulkCursorAdaptor类的功能。
Cursor家族有些复杂。笔者觉得,目前对Cursor的架构设计有些过度(over-designed)。这不仅会导致我们分析时困难重重,并且也会对实际代码的运行效率造成一定损失。

3.2.3 query跨进程的数据传输
本节将按如下顺序分析query函数中的关键点:
· 首先介绍服务端的CursorToBulkCursorAdaptor及其count函数。
· 跨进程共享数据的关键类CursorWindow。
· 客户端的BulkCursorToCursorAdaptor及其initialize函数,以及返回给客户端使用的CursorWrapperInner类
3.2.3.1 CursorToBulkCursorAdaptor分析
3.2.3.1.1 构造函数分析
3.2.3.1.2 count函数分析
count最终将调用SQLiteCursor的getCount函数, getCount函数将调用一个非常重要的函数,即fillWindow。顾名思义,读者可以猜测到它的功能:将结果数据保存到CursorWindow的那块共享内存中。
3.2.3.2 CursorWindow
CursorWindow的创建源于前边代码中对fillWindow的调用。
3.2.3.2.1 clearOrCreateLocalWindow函数分析
CursorWindow的create函数将构造一个Native的CursorWindow对象。最终,Java层的CursorWindow对象会和此Native的CursorWindow对象绑定。
至此,用于承载数据的共享内存已创建完毕,但我们还没有执行SQL的SELECT语句。这个工作由SQLiteQuery的fillWindow函数完成。
3.2.3.2.2 SQLiteQuery fillWindow分析
SQLiteQuery保存了一个Native层的sqlite3_stmt实例,那么它的fillWindow函数是否就是执行SQL语句后将结果信息填充到CursorWindow中了呢?可以通过以下代码来验证。
fillWindow函数实现的就是将SQL语句的执行结果填充到了CursorWindow的共享内存中。读者如感兴趣,不妨研究一下CursorWindow是如何保存结果信息的。
3.2.3.2.3 CursorWindow分析总结
其实,CursorWindow就是对一块共享内存的封装。另外我们也看到了如何将执行SELECT语句后得到的结果集填充到这块共享内存中。但是这块内存现在还仅属于服务端进程,只有客户端进程得到这块内存后,客户端才能真正获取执行SELECT后的结果。那么,客户端是何时得打这块内存的呢?让我们回到客户端进程。
3.2.3.3 BulkCursorToCursorAdaptor和CursorWrapperInner分析
客户端的工作是先创建BulkCursorToCursorAdaptor,然后根据远端query的结果调用BulkCursorToCursorAdaptor的intialize函数。
BulkCursorToCursorAdaptor仅简单保存了来自远端的信息,并没有什么特殊操作。看来客户端进程没有在上面代码的执行过程中共享内存。该工作会不会由CursorWrapperInner来完成呢?看ContentResolver query最终返回给客户端的对象的类CursorWrapperInner
CursorWrapperInner的构造函数也没有去获取共享内存。别急,先看看执行query后的结果。
客户端通过Image.Media query函数,将得到一个CursorWrapperInner类型的游标对象。当然,客户端并不知道这么重要的细节,它只知道自己用的是接口类Cursor。根据前面的分析,此时客户端通过这个游标对象可与服务端的CursorToBulkCursorAdaptor交互,即进程间Binder通信的通道已经打通。但是此时客户端还未拿到那块至关重要的共享内存,即进程间的数据通道还没打通。那么,数据通道是何时打通的呢?
数据通道打通的时间又和lazy creation联系上了,即只在使用它时才打通。
3.2.3.4 moveToFirst函数分析
客户端从Image.Media query函数得到的游标对象,其真实类型是CursorWrapperInner。游标对象的使用有一个特点,即必须先调用它的move家族的函数。这个家族包括moveToFirst、moveToLast等函数。为什么一定要调用它们呢?来分析最常见的moveToFirst函数.
moveToPosition将调用子类实现的onMove函数。在本例中,子类就是BulkCursorToCursorAdaptor,接下来看它的onMove函数。
3.2.3.4.1 BulkCursorToCursorAdaptor的onMove函数分析
建立数据通道的关键函数是IBulkCurosr的getWindow。对于客户端而言,IBulkCursor Bp端对象的类型是BulkCursorProxy,下面介绍它的getWindow函数。
3.2.3.4.2 BulkCursorProxy的 getWindow函数分析
再来看IBulkCursor Bn端的getWindow函数,此Bn端对象的真实类型是CursorToBulkCursorAdaptor。
3.2.3.4.3 CursorToBulkCursorAdaptor的 getWindow函数分析
服务端返回的CursorWindow对象正是之前在count函数中创建的那个CursorWindow对象,其内部已经包含了执行本次query的查询结果。
另外,在将服务端的CursorWindow传递到客户端之前,系统会调用CursorWindow的writeToParcel函数进行序列化工作。读者可自行阅读CursorWindow的writeToParcel及其native实现nativeWriteToParcel函数。
3.2.3.4.4 SQLiteCursor的 moveToPostion函数分析
该函数由SQLiteCursor的基类AbstractCursor实现。我们前面已经看过它的代码了,其内部的主要工作就是调用AbstractCursor子类(此处就是SQLiteCursor自己)实现onMove函数,因此可直接看SQLiteCursor的onMove函数。
具体解释如下:
· 当mWindow为空,即服务端未创建CursorWindow时(当然,就本例而言,CursorWindow早已在query时就创建好了),需调用fillWindow。该函数内部将调用clearOrCreateLocalWindow。如果CursorWindow不存在,则创建一个CursorWindow对象。如果已经存在,则清空CursorWindow对象的信息。
· 当newPosition小于上一次查询得到的CursorWindow的起始位置,或者newPosition大于上一次查询得到的CursorWindow的最大行位置,也需调用fillWindow。由于此时CursorWindow已经存在,则clearOrCreateLocalWindow会调用它的clear函数以清空之前保存的信息。
· 调用fillWindow后将执行SQL语句,以获得正确的结果集。例如,假设上次执行query时设置了查询从第10行开始的90条记录(即10~100行的记录),那么,当新的query若指定了从0行开始或从101行开始时,就需重新fillWindow,即将新的结果填充到CursorWindow中。如果新query查询的行数位于10~100之间,则无需再次调用fillWindow了。
这是服务端针对query做的一些优化处理,即当CursorWindow已经包含了所要求的数据时,就没有必要再次查询了。按理说,客户端也应该做类似的判断,以避免发起不必要的Binder请求。我们回过头来看客户端BulkCursorToCursorAdaptor的onMove函数。
3.2.3.4.5 moveToFirst函数分析总结
moveToFirst及相关的兄弟函数(如moveToLast和move等)的目的是移动游标位置到指定行。通过上面的代码分析,我们发现它的工作其实远不止移动游标位置这么简单。对于还未拥有CursorWindow的客户端来说,moveToFirst将导致客户端反序列化来自服务端的CursorWindow信息,从而使客户端和服务端之间的数据通道真正建立起来。
4. Cursor close函数实现分析
虽然大部分Java程序员对主动回收资源(包括内存等)的认识普遍不如C/C++程序员,但是对于Cursor这种重型资源(不仅占用了一个文件描述符,还共享了一块2MB的内存)来说,Java程序员在编程过程中务必显示调用close函数以释放这些资源。在日常工作中,笔者已无数次碰到因为Cursor未关闭而导致Monkey测试未通过的情况了。
另外,有些同事曾问笔者,虽然没有显示调用close函数,但这个对象也没有地方再引用它了。按照Java垃圾回收机制的规矩,该对象在一定时间后会被回收。既然Cursor本身都被回收了,为什么它包含的资源(指CursorWindow)却没有被回收呢?关于这个问题,本节最后再作讨论。
4.1 客户端close的分析
客户端拿到的游标对象的真实类型是CursorWrapperInner.
下面来看CursorWrapperInner的基类CursorWrapper的close函数。须提醒读者注意,后文对函数分析会频繁从基类转到子类,又从子类转到基类。造成这种局面的原因就是对类封装得太利害的结果。
对于Cursor close函数来说,笔者更关注其中所包含的CursorWindow资源是如何释放的。根据以上代码中的注释可知,BulkCurosrToCursorAdaptor的close调用的基类close函数会释放CursorWindow。
4.2 服务端close的分析
服务端close函数的触发是因为客户端通过IBulkCurosrclose函数发送了Binder请求。IBulkCurosr的Bn端就是目标CP进程的CursorToBulkCursorAdaptor
4.3 finalize函数分析
现在来回答本节最开始提出的问题,如果没有显示调用游标对象的close函数,那么该对象被垃圾回收时是否会调用close函数呢?下面用代码来回答这个问题。
游标对象被回收前,其finalize函数将被调用。来看CursorWrapperInner的finalize函数
很可惜,我们寄予厚望的super.finalize函数也不会做出什么特殊的处理。难道CursorWindow资源就没地方处理了?这个问题的答案如下:
· 客户端所持有的CursorWindow资源会在该对象执行finalize时被回收。读者可查看CursorWindow的finalize函数。
· 前面分析过,服务端的close函数由BulkCurosrToCursorAdaptor调用IBulkCursor close函数触发。但BulkCurosrToCursorAdaptor却没有实现finalize函数,故BulkCurosrToCursorAdaptor被回收时,并不会触发服务端的Cursor释放。所以,如客户端不显示调用close,将导致服务端进程的资源无法释放。
提示笔者在分析Monkey测试失败案例时发现,导致进程问题的原因都在android.process.media中。根据对finalize的分析可知,问题的根源在客户端。由于使用MediaProvider的客户端较多(包括Music、Gallery3D、Video等),所以每次出现这种问题时,都需要所有MediaProvider的客户端开发者协助调查。
5 ContentResolver.openAssetFileDescriptor
客户端进程可像查询本地数据库那样,从目标CP进程获取信息。不过,这种方法也有其局限性:
q 客户端只能按照结果集的组织方式来获取数据,而结果集的组织方式是行列式的,即客户端须移动游标到指定行,才能获取自己感兴趣的列的值。在实际生活中,不是所有信息都能组织成行列的格式。
q query查询得到的数据的数据量很有限。通过分析可知,用于承载数据的共享内存只有2MB大小。对于较大数据量的数据,通过query方式来获取显然不合适。
考虑到query的局限性,ContentProvider还支持另外一种更直接的数据传输方式,笔者称之为“文件流方式”。因为通过这种方式客户端将得到一个类似文件描述符的对象,然后在其上创建对应的输入或输出流对象。这样,客户端就可通过它们和CP进程交互数据了。
5.1 openAssetFileDescriptor之客户端调用分析
openAssetFileDescriptor是一个通用函数,它支持三种sheme类型的URI。
· SCHEME_ANDROID_RESOURCE:字符串表达为“android.resource”。通过它可以读取APK包(其实就是一个压缩文件)中封装的资源。假设在应用进程的res/raw目录下存放一个test.ogg文件,最终生成的资源id由R.raw.tet来表达,那么如果应用进程想要读取这个资源,创建的URI就是“android.resource://com.package.name/R.raw.test”。读者不妨试一试。
· SCHEME_FILE:字符串表达为“file”。通过它可以读取普通文件。
· 除上述两种scheme之外的URI:这种资源背后到底对应的是什么数据需要由目标CP来解释。
5.1.1 openTypedAssetFileDescriptor函数分析
· FileDescriptor类是Java的标准类,它是对文件描述符的封装。进程打开的每一个文件都有一个对应的文件描述符。在Native语言开发中,它用一个int型变量来表示。
· 文件描述符作为进程的本地资源,如想越过进程边界将其传递给其他进程,则需借助进程间共享技术。在Android平台上,设计者封装了一个ParcelFileDescriptor类。此类实现了Parcel接口,自然就支持了序列化和反序列化的功能。从图可知,一个ParcelFileDescriptor通过mFileDescritpor指向一个文件描述符。
· AssetFileDescriptor也实现了Parcel接口,其内部通过mFd成员变量指向一个ParcelFileDescriptor对象。从这里可看出,AssetFileDescritpor是对ParcelFileDescriptor类的进一步封装和扩展。实际上,根据SDK文档中对AssetFileDescritpor的描述可知,其作用在于从AssetManager(后续分析资源管理的时候会介绍它)中读取指定的资源数据。
提示简单向读者介绍一下与AssetFileDescriptor相关的知识。它用于读取APK包中指定的资源数据。如果通过AssetFileDescriptor读取它,那么其mFd成员则指向一个ParcelFileDescriptor对象。且不管这个对象是否跨越了进程边界,它毕竟代表一个文件。假设这个文件是一个APK包,AssetFileDescriptor的mStartOffset变量用于指明test.ogg在这个APK包中的起始位置,比如100字节。而mLength用于指明test.ogg的长度,假设是1000字节。通过上面的介绍可知,该APK文件从100字节到1100字节这一段空间中存储的就是test.ogg的数据。这样,AssetFileDescriptor就能将test.ogg数据从APK包中读取出来了。
5.2 ContentProvider的 openTypedAssetFile函数分析
5.2.1 MediaProvider.openFile分析
MediaProvider将首先通过客户端指定的音乐文件的_id去查询它的专辑信息。得到的结果集包含:第一列音乐文件的_id值,第二列返回音乐文件所属专辑的album_id值,第三列返回对应歌曲的文件存储路径。
在调用openFileHelper函数前构造了一个新的URI变量,根据代码中的注释可知,它将查询album_art表
5.2.2 ContentProvider.openFileHelper函数分析
至此,服务端已经打开指定文件了。那么,这个服务端的文件描述符是如何传递到客户端的呢?我们单起一节来回答这个问题。
5.3 跨进程传递文件描述符的探讨
实现文件描述符跨进程传递的目的是什么?
以上节所示读取音乐专辑的缩略图为例,问题的答案就是,让客户端能够读取专辑的缩略图文件。为什么客户端不先获得对应专辑缩略图的文件存储路径,然后直接打开这个文件,却要如此大费周章呢?原因有二:
q 出于安全的考虑,MediaProvider不希望客户端绕过它去直接读取存储设备上的文件。另外,客户端须额外声明相关的存储设备读写权限,然后才能直接读取其上面的文件。
q 虽然本例针对的是一个实际文件,但是从可扩展性角度看,我们希望客户端使用一个更通用的接口,通过这个接口可读取实际文件的数据,也可读取来自的网络的数据,而作为该接口的使用者无需关心数据到底从何而来。
5.3.1 序列化ParcelFileDescriptor
现在服务端已经打开了某个缩略图文件,并且获得了一个文件描述符对象FileDescriptor。这个文件是服务端打开的。如何让客户端也打开这个文件呢?各据前文分析,客户端不会也不应该通过文件路径自己去打开这个文件。那该如何处理?
没关系,Binder驱动支持跨进程传递文件描述符。先来看ParcelFileDescriptor的序列化函数writeToParcel
ParcelFileDescriptor的序列化过程就是将其内部对应文件的文件描述符取出,并存储到一个由Binder驱动的flat_binder_object对象中。该对象最终会发送给Binder驱动。
5.3.2 反序列化ParcelFileDescriptor
假设客户端进程收到了来自服务端的回复,客户端要做的就是根据服务端的回复包构造一个新的ParcelFileDescriptor。我们重点关注文件描述符的反序列化,其中调用的函数是Parcel的readFileDescriptor
此fd是彼fd吗?这个问题的真实含义是:
· 服务端打开了一个文件,得到了一个fd。注意,fd是一个整型。在服务端上,这个fd确实对应了一个已经打开的文件。
· 客户端得到的也是一个整型值,它对应的是一个文件吗?
如果说客户端得到一个整型值,就认为它得到了一个文件,这种说法未免有些草率。在以上代码中,我们发现客户端确实根据收到的那个整型值创建了一个FileDescriptor对象。那么,怎样才可知道这个整型值在客户端中一定代表一个文件呢?
这个问题的终极解答在Binder驱动的代码中。来看它的binder_transaction函数。
5.3.3 文件描述符传递之Binder驱动的处理
原来,Binder驱动代替客户端打开了对应的文件,所以现在可以肯定,客户端收到的整型值确确实实代表一个文件。
5.3.4 在研究这段代码时,笔者曾经向所在团队同仁问过这样一个问题:在Linux平台上,有什么办法能让两个进程共享同一文件的数据呢?曾得到下面这些回答:
· 两个进程打开同一文件。这种方式前面讨论过了,安全性和可扩展性都比较差,不是我们想要的方式。
· 通过父子进程的亲缘关系,使用文件重定向技术。由于这两个进程关系太亲近,这种实现方式拓展性较差,也不是我们想要的。
· 跳出两个进程打开同一个文件的限制。在两个进程间创建管道,然后由服务端读取文件数据并写入管道,再由客户端进程从管道中获取数据。这种方式和前面介绍的openAssetFileDescriptor有殊途同归之处。
在缺乏类似Binder驱动支持的情况下,要在Linux平台上做到文件描述符的跨进程传递是件比较困难的事。从上面三种回答来看,最具扩展性的是第三种方式,即进程间采用管道作为通信手段。但是对Android平台来说,这种方式的效率显然不如现有的openAssetFileDescriptor的实现。原因在于管道本身的特性。
服务端必须单独启动一个线程来不断地往管道中写数据,即整个数据的流动是由写端驱动的(虽然当管道无空间的时候,如果读端不读取数据,写端也没法再写入数据,但是如果写端不写数据,则读端一定读不到数据。基于这种认识,笔者认为管道中数据流动的驱动力应该在写端)。