Java基础总结
转载请注明出处:
http://blog.csdn.net/gane_cheng/article/details/52304478
http://www.ganecheng.tech/blog/52304478.html (浏览效果更好)
琥哥的Java基础总结,东西非常多,经常看有一种历久弥新的感觉
一、JVM
1、内存模型
1.1.1 内存分几部分
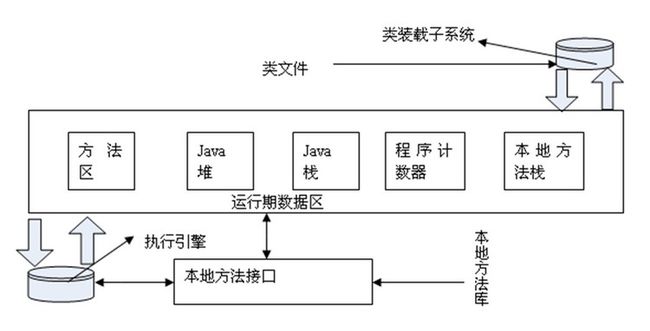
(1)程序计数器
可看作当前线程所执行的字节码的行号指示器。字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
在线程创建时创建。执行本地方法时,PC的值为null。为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,线程私有。
(2)Java虚拟机栈
线程私有,生命周期同线程。每个方法在执行同时,创建栈帧。用于存储局部变量表、操作数栈、动态链接、方法出口等信息。栈中的局部变量表主要存放一些基本类型的变量(int, short, long, byte, float,double, boolean, char)和对象句柄。
栈中有局部变量表,包含参数和局部变量。

此外,java中没有寄存器,因此所有的参数传递依靠操作数栈。
栈上分配,小对象(一般几十个bytes),在没有逃逸的情况下,可以直接分配在栈上。(没有逃逸是指,对象只能给当前线程使用,如果多个线程都要用,则不可以,因为栈是线程私有的。)直接分配在栈上,可以自动回收,减轻GC压力。因为栈本身比较小,大对象也不可以分配,会影响性能。
-XX:+DoEscapeAnalysis 启用逃逸分析,若非逃逸则可栈上分配。
(3)本地方法栈
线程私有,与Java虚拟机栈非常相似,区别不过是虚拟机栈为虚拟机执行Java 方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的 Native 方法(非java语言实现,比如C)服务。Hotspot 直接把本地方法栈和虚拟机栈合二为一。
栈&本地方法栈:线程创建时产生,方法执行是生成栈帧。
(4)Java堆
线程共有(可能划分出多个线程私有的分配缓冲区,Thread Local Allow),Java虚拟机管理内存中最大的一块,此区域唯一目的就是存放对象实例,几乎所有对象实例在此区分配,线程共享内存。可细分为新生代和老年代,方便GC。主流虚拟机都是按可扩展实现(通过-Xmx 和 -Xms 控制)。
注意:Java堆是Java代码可及的内存,是留给开发人员使用的;非堆(Non-Heap)就是JVM留给 自己用的,所以方法区、JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法的代码都在非堆内存中。
关于TLAB
Sun Hotspot JVM为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间TLAB(Thread Local Allocation Buffer),其大小由JVM根据运行的情况计算而得,在TLAB上分配对象时不需要加锁,因此JVM在给线程的对象分配内存时会尽量的在TLAB上分配,在这种情况下JVM中分配对象内存的性能和C基本是一样高效的,但如果对象过大的话则仍然是直接使用堆空间分配
TLAB仅作用于新生代的Eden Space,因此在编写Java程序时,通常多个小的对象比大的对象分配起来更加高效。详见:http://www.cnblogs.com/sunada2005/p/3577799.html
Java堆:在虚拟机启动时创建
(5)方法区
线程共有,用于存储已被虚拟机加载的类信息、常量池、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但它却有一个别名Non-Heap(非堆),目的是与Java堆区分开。
注意,通常和永久区(Perm)关联在一起。但也不一定,JDK6时,String等常量信息保存于方法区,JDK7时,移动到了堆。永久代和方法区不是一个概念,但是有的虚拟机用永久代来实现方法区,可以用永久代GC来管理方法区,省去专门写的功夫。
(6)运行时常量池
方法区的一部分,存放编译期生成的各种字面量和符号引用。
(7)直接内存
并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,也可能导致 OOM 异常(内存区域综合>物理内存时)。NIO类,可以使用Native 函数库直接分配堆外内存,然后通过一个存储在Java 堆里面的 DirectByteBuffer 对象作为这块内存的引用进行操作。
类加载时 方法信息保存在一块称为方法区的内存中, 并不随你创建对象而随对象保存于堆中。可参考《深入java虚拟机》前几章。
另参考(他人文章):
如果instance method也随着instance增加而增加的话,那内存消耗也太大了,为了做到共用一小段内存,Java 是根据this关键字做到的,比如:instance1.instanceMethod(); instance2.instanceMethod(); 在传递给对象参数的时候,Java 编译器自动先加上了一个this参数,它表示传递的是这个对象引用,虽然他们两个对象共用一个方法,但是他们的方法中所产生的数据是私有的,这是因为参数被传进来变成call stack内的entry,而各个对象都有不同call stack,所以不会混淆。其实调用每个非static方法时,Java 编译器都会自动的先加上当前调用此方法对象的参数,有时候在一个方法调用另一个方法,这时可以不用在前面加上this的,因为要传递的对象参数就是当前执行这个方法的对象。
详见:http://blog.csdn.net/scythe666/article/details/51700142
1.1.2 堆溢出、栈溢出原因及实例,线上如何排查
(1)栈溢出
递归,容易引起栈溢出stackoverflow;因为方法循环调用,方法调用会不断创建栈帧。
造成栈溢出的几种情况:
1)递归过深
2)数组、List、map数据过大
3 ) 创建过多线程
对于Java虚拟机栈和本地方法栈,Java虚拟机规范规定了两种异常状况:
① 线程请求深度>虚拟机所允许的深度,将抛出StackOverFlowError(SOF)异常;
② 如果虚拟机可动态扩展,且扩展时无法申请到足够的内存,就会抛出OutOfMemoryError(OOM)异常。
(2)堆溢出
如果在堆中没有内存完成实例分配,且堆无法扩展时,将抛出OOM异常。
在方法区也会抛出 OOM 异常。
实例
可使用以下代码造成堆栈溢出:
package overflow;
import java.util.ArrayList;
/** * Created by hupo.wh on 2016/7/7. */
public class MyTest {
public void testHeap(){
for(;;){
ArrayList list = new ArrayList (2000);
}
}
int num=1;
public void testStack(){
num++;
this.testStack();
}
public static void main(String[] args){
MyTest t = new MyTest();
t.testHeap();
//t.testStack();
}
}如下代码会造成OOM堆溢出:
package OOM;
import java.util.ArrayList;
import java.util.List;
/** * Created by hupo.wh on 2016/7/15. */
public class App1 {
static class OOMClass {
long[] num = new long[10240];
}
public static void main(String[] args) {
List<OOMClass> list = new ArrayList<>();
while (true) {
list.add(new OOMClass());
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

另外,Java虚拟机的堆大小如何设置:命令行
java –Xms128m //JVM占用最小内存
–Xmx512m //JVM占用最大内存
–XX:PermSize=64m //最小堆大小
–XX:MaxPermSize=128m //最大堆大小
2、类加载机制
基本上所有的类加载器都是 java.lang.ClassLoader类的一个实例。下面详细介绍这个 Java 类。
1.2.1 java.lang.ClassLoader类介绍
java.lang.ClassLoader类的基本职责就是根据一个指定的类的名称,找到或者生成其对应的字节代码,然后从这些字节代码中定义出一个 Java 类,即 java.lang.Class类的一个实例。除此之外,ClassLoader还负责加载 Java 应用所需的资源,如图像文件和配置文件等。
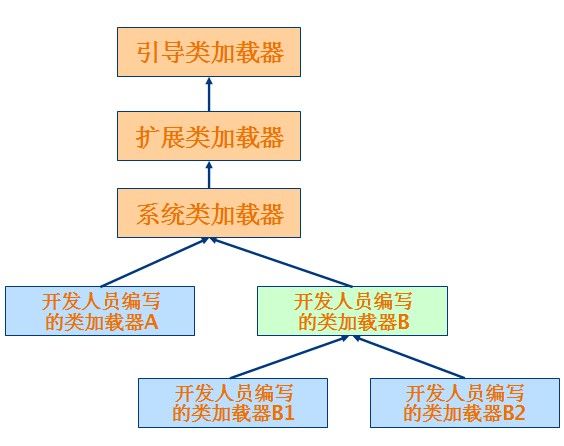
1.2.2 类加载器的树状组织结构
Java 中的类加载器大致可以分成两类:一类是系统提供的,另外一类则是由 Java 应用开发人员编写的。系统提供的类加载器主要有下面三个:
(1)引导类加载器(bootstrap class loader):它用来加载 Java 的核心库,是用原生代码来实现的,并不继承自 java.lang.ClassLoader。
BootStrapClassLoader
负责jdk_home/jre/lib目录下的核心 api或 -Xbootclasspath选项指定的jar包加载进来。
(2)扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
ExtClassLoader
负责jdk_home/jre/lib/ext目录下的jar包或 -Djava.ext.dirs指定目录下的jar包加载进来。
(3)系统类加载器(system class loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,Java 应用的类都是由它来完成加载的。可以通过 ClassLoader.getSystemClassLoader()来获取它。
AppClassLoader
负责java -classpath/-Djava.class.path所指的目录下的类与jar包加载进来,System.getClassLoader获取到的就是这个类加载器。
除了系统提供的类加载器以外,开发人员可以通过继承 java.lang.ClassLoader类的方式实现自己的类加载器,以满足一些特殊的需求。
除了引导类加载器之外,所有的类加载器都有一个父类加载器。getParent()方法可以得到。对于系统提供的类加载器来说,系统类加载器的父类加载器是扩展类加载器,而扩展类加载器的父类加载器是引导类加载器;对于开发人员编写的类加载器来说,其父类加载器是加载此类加载器 Java 类的类加载器。因为类加载器 Java 类如同其它的 Java 类一样,也是要由类加载器来加载的。一般来说,开发人员编写的类加载器的父类加载器是系统类加载器。类加载器通过这种方式组织起来,形成树状结构。树的根节点就是引导类加载器。
1.2.3 双亲委派模型
类加载器在尝试自己去查找某个类的字节代码并定义它时,会先代理给其父类加载器,由父类加载器先去尝试加载这个类,依次类推。
在介绍代理模式背后的动机之前,首先需要说明一下 Java 虚拟机是如何判定两个 Java 类是相同的。Java 虚拟机不仅要看类的全名是否相同,还要看加载此类的类加载器是否一样。只有两者都相同的情况,才认为两个类是相同的。即便是同样的字节代码,被不同的类加载器加载之后所得到的类,也是不同的。比如一个 Java 类 com.example.Sample,编译之后生成了字节代码文件 Sample.class。两个不同的类加载器 ClassLoaderA和 ClassLoaderB分别读取了这个 Sample.class文件,并定义出两个 java.lang.Class类的实例来表示这个类。这两个实例是不相同的。对于 Java 虚拟机来说,它们是不同的类。试图对这两个类的对象进行相互赋值,会抛出运行时异常 ClassCastException。
所以才有双亲委派模型,这样的话,可保证加载的类(特别是Object和String这类基础类)是同一个。
package classloaderstring;
/** * Created by hupo.wh on 2016/7/7. */
public class String {
public java.lang.String toString() {
return "这是我自定义的String类的toString方法";
}
}
package classloaderstring;
import java.lang.*;
import java.lang.reflect.Method;
/** * Created by hupo.wh on 2016/7/7. */
public class TestString {
public static void main(java.lang.String args[]) throws Exception {
java.lang.String classDataRootPath = "D:\\xiaohua\\WhTest\\out\\production\\WhTest\\classloader\\Sample";
FileSystemClassLoader fscl1 = new FileSystemClassLoader(classDataRootPath);
Class<?> class1 = fscl1.loadClass("classloaderstring.String");
Object obj1 = class1.newInstance();
System.out.println(java.lang.String.class.getClassLoader());
System.out.println(class1.getClassLoader());
System.out.println(java.lang.String.class);
System.out.println(class1);
Method setSampleMethod = class1.getMethod("toString");
System.out.println(setSampleMethod.invoke(obj1));
}
}
输出:
null
sun.misc.Launcher$AppClassLoader@42a57993
class java.lang.String
class classloaderstring.String
这是我自定义的String类的toString方法
- 1
- 2
- 3
- 4
- 5
这两个类并不是一个String类,要包名类名+loader一致是不可能的,所以双亲委派模型从外界无法破坏。
注意:这里有
- 若加载的类能被系统加载器加载到(Sample类在classpath下),则无异常。因为defining class loader都是AppClassLoader
- 若加载的类不能被系统加载器加载到,则抛异常。此时的 defining class loader 才是自定义的 FileSystemClassLoader
1.2.4 defining loader 和 initiating loader
前面提到过类加载器会首先代理给其它类加载器来尝试加载某个类。这就意味着真正完成类的加载工作的类加载器和启动这个加载过程的类加载器,有可能不是同一个。真正完成类的加载工作是通过调用 defineClass来实现的;而启动类的加载过程是通过调用 loadClass来实现的。前者称为一个类的定义加载器(defining loader),后者称为初始加载器(initiating loader)。在 Java 虚拟机判断两个类是否相同的时候,使用的是类的定义加载器。也就是说,哪个类加载器启动类的加载过程并不重要,重要的是最终定义这个类的加载器。两种类加载器的关联之处在于:一个类的定义加载器是它引用的其它类的初始加载器。如类 com.example.Outer引用了类 com.example.Inner,则由类 com.example.Outer的定义加载器负责启动类 com.example.Inner的加载过程。
方法 loadClass()抛出的是 java.lang.ClassNotFoundException异常;方法 defineClass()抛出的是 java.lang.NoClassDefFoundError异常。
类加载器在成功加载某个类之后,会把得到的 java.lang.Class类的实例缓存起来。下次再请求加载该类的时候,类加载器会直接使用缓存的类的实例,而不会尝试再次加载。也就是说,对于一个类加载器实例来说,相同全名的类只加载一次,即 loadClass方法不会被重复调用。
1.2.5 Class.forName 加载
Class.forName是一个静态方法,同样可以用来加载类。该方法有两种形式:
Class.forName(String name, boolean initialize, ClassLoader loader)
- 1
和
Class.forName(String className)
- 1
第一种形式的参数 name表示的是类的全名;initialize表示是否初始化类;loader表示加载时使用的类加载器。
第二种形式则相当于设置了参数 initialize的值为 true,loader的值为当前类的类加载器。Class.forName的一个很常见的用法是在加载数据库驱动的时候。如 Class.forName("org.apache.derby.jdbc.EmbeddedDriver").newInstance()用来加载 Apache Derby 数据库的驱动。
详见:http://www.ibm.com/developerworks/cn/java/j-lo-classloader/index.html
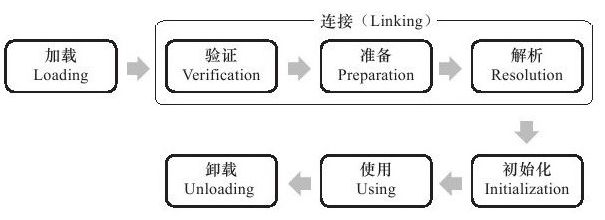
1.2.6 类加载过程
从类被加载到虚拟机内存中开始,到卸载出内存为止,类的生命周期包括加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)7个阶段。
http://www.open-open.com/lib/view/open1352161045813.html
其中加载(除了自定义加载)+链接的过程是完全由jvm负责的,什么时候要对类进行初始化工作(加载+链接在此之前已经完成了),jvm有严格的规定(四种情况):
1.遇到new,getstatic,putstatic,invokestatic这4条字节码指令时,加入类还没进行初始化,则马上对其进行初始化工作。其实就是3种情况:用new实例化一个类时、读取或者设置类的静态字段时(不包括被final修饰的静态字段,因为他们已经被塞进常量池了)、以及执行静态方法的时候。
2.使用java.lang.reflect.*的方法对类进行反射调用的时候,如果类还没有进行过初始化,马上对其进行。
3.初始化一个类的时候,如果他的父亲还没有被初始化,则先去初始化其父亲。
4.当jvm启动时,用户需要指定一个要执行的主类(包含static void main(String[] args)的那个类),则jvm会先去初始化这个类。
以上4种预处理称为对一个类进行主动的引用,其余的其他情况,称为被动引用,都不会触发类的初始化。
加载:
在加载阶段,虚拟机主要完成三件事:
1.通过一个类的全限定名来获取定义此类的二进制字节流。
2.将这个字节流所代表的静态存储结构转化为方法区域的运行时数据结构。
3.在Java堆中生成一个代表这个类的java.lang.Class对象,作为方法区域数据的访问入口。
验证:
验证阶段作用是保证Class文件的字节流包含的信息符合JVM规范,不会给JVM造成危害。如果验证失败,就会抛出一个java.lang.VerifyError异常或其子类异常。验证过程分为四个阶段:
1.文件格式验证:验证字节流文件是否符合Class文件格式的规范,并且能被当前虚拟机正确的处理。
2.元数据验证:是对字节码描述的信息进行语义分析,以保证其描述的信息符合Java语言的规范。
3.字节码验证:主要是进行数据流和控制流的分析,保证被校验类的方法在运行时不会危害虚拟机。
4.符号引用验证:符号引用验证发生在虚拟机将符号引用转化为直接引用的时候,这个转化动作将在解析阶段中发生。
准备:
准备阶段为变量分配内存并设置类变量的初始化。在这个阶段分配的仅为类的变量(static修饰的变量),而不包括类的实例变量,实例变量将会在对象实例化时随着对象一起分配在Java堆中。对非final的变量,JVM会将其设置成“零值”,而不是其赋值语句的值:
private static int size = 12;
- 1
那么在这个阶段,size的值为0,而不是12。 final修饰的类变量将会赋值成真实的值。
解析:
解析过程是将常量池内的符号引用替换成直接引用。主要包括四种类型引用的解析。类或接口的解析、字段解析、方法解析、接口方法解析。
初始化:
在准备阶段,类变量已经经过一次初始化了,在这个阶段,则是根据程序员通过程序制定的计划去初始化类的变量和其他资源。这些资源有static{}块,构造函数,父类的初始化等。
至于使用和卸载阶段阶段,这里不再过多说明,使用过程就是根据程序定义的行为执行,卸载由GC完成
3、垃圾回收 GC
1.3.1 引用计数法
目前主流的虚拟机都没有使用引用计数法,主要原因就是它很难解决对象之间互相循环引用的问题。
1.3.2 可达性分析算法
思想:
通过一系列称为 GC Roots 的对象作为起始点,从这些点开始向下搜索,搜索走过的路径称为引用链,当一个对象到GC Roots没有任何引用链连接(用图论的话来说,就是从GC Roots到这个对象不可达),证明此对象不可用。
Java语言中,可作为GC Roots的对象包括:
(1)虚拟机栈(栈帧中的本地变量表)中引用的对象
(2)方法区中类静态属性引用的对象
(3)方法区中常量引用的对象
(4)本地方法栈中JNI ( 即一般说的Native方法)引用的对象
1.3.3 再谈引用
在JDK 1.2之后 ,Java对引用的概念进行了扩充,将引用分为强引用(Strong Reference )、软引用(Soft Reference )、弱引用(Weak Reference )、虚引用(Phantom Reference) 4种 , 引用强度依次逐渐减弱。
强引用
指在程序代码之中普遍存在的,类似“Object obj=new Object ( ) ”这类的引用 ,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。
软引用
用来描述一些还有用但并非必需的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行二次回收。如果这次回收还没有足够的内存,才会拋出内存溢出异常。在JDK 1.2之后,提供了SoftReference类来实现软引用。
弱引用
也是用来描述非必需对象的,但是它的强度比软引用更弱一些,被弱引用关联的对象只能生存到下一次垃圾收集发生之前。在JDK1.2之后,提供了PhantomReference类来实现虚引用。
虚引用
也称为幽灵引用或者幻影引用,它是最弱的一种引用关系。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。在JDK1.2之后,提供了PhantomReference类来实现虚引用。
1.3.4 对象回收过程
即使在可达性分析算法中不可达的对象,也并非是“非死不可”的 ,这时候它们暂时处于“缓刑” 阶段 ,要真正宣告一个对象死亡 ,至少要经历两次标记过程
如果这个对象被判定为有必要执行finalize() 方法,那么这个对象将会放置在一个叫做 F-Queue的队列之中,并在稍后由一个由虚拟机自动建立的、低优先级的Finalizer线程去执行它。
1.3.5 对于方法区(Hotspot虚拟机的永久代)的回收
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面3个条件才能算是“无用的类”:
(1)该类所有的实例都已经被回收,也就是Java堆中不存在该类的任何实例
(2)加载该类的ClassLoader已经被回收
(3)该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
详情参考:深入理解Java虚拟机第三章 对象存活判定算法
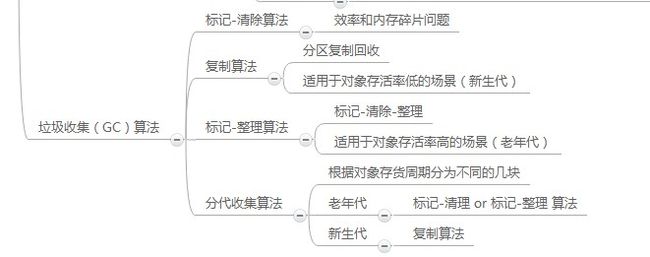
1.3.6 垃圾收集算法
1.3.6.1 标记-清除算法
望名生意,算法分为“标记”和“清除”两个阶段:
首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象,它的标记过程如前
它的主要不足有两个:
(1)效率问题,标记和清除两个过程的效率都不高;
(2)空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
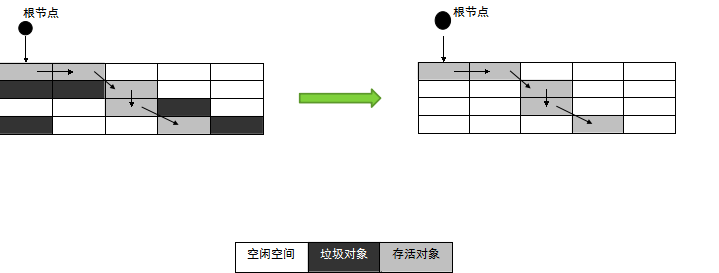
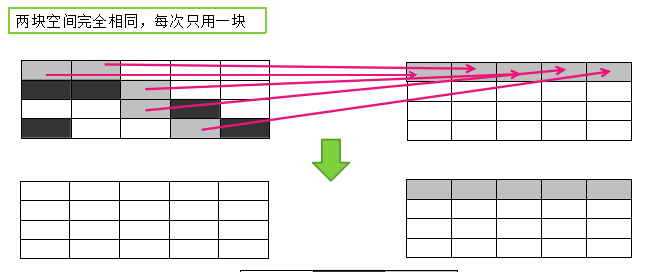
1.3.6.2 复制算法
将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
适用于对象存活率低的场景(新生代)
这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针 ,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半,未免太高了一点。
将内存分为一块较大的Eden空间和两块较小的Survivor空间 ,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次地复制到另外一块Survivor空间上,最 后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是 8:1,也就是每次新生代中可用内存空间为整个新生代容量的90% ( 80%+10% ) ,只有10% 的内存会被 “浪费”。当然,98%的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖其他内存(这里指老年代)进行分配担保( Handle Promotion ) 。

1.3.6.3 标记-整理算法
适用于对象存活率高的场景(老年代)
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是 ,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
标记过程类似“标记-清除”算法,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存,类似于磁盘整理的过程
总的分类如下图:
1.3.7 内存申请过程
内存由Perm和Heap组成。其中Heap = {Old + NEW = { Eden , from, to } }。perm用来存放常量等。
heap中分为年轻代(young)和年老代(old)。年轻代又分为Eden,Survivor(幸存区)。Survivor又分为from,to,也可以不只是这两块,切from和to没有先后顺序。其中,old和young区比例可手动分配。
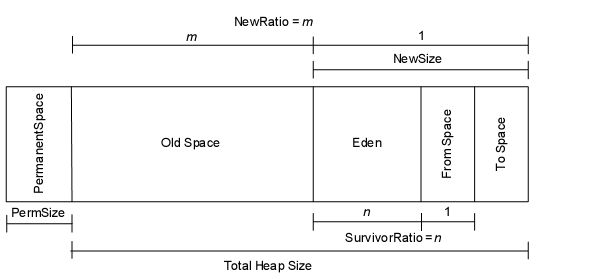
当OLD区空间不够时,JVM会在OLD区进行完全的垃圾收集。完全垃圾收集后,若Survivor及OLD区仍然无法存放从Eden复制过来的部分对象,导致JVM无法在Eden区为新对象创建内存区域,则出现”out of memory”Error。
好文请见:http://blog.csdn.net/scythe666/article/details/51852938
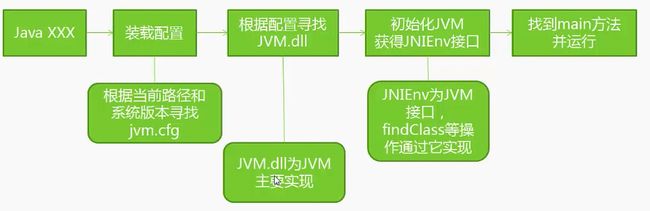
4、JVM启动过程
JVM工作原理和特点主要是指操作系统装入JVM是通过jdk中Java.exe来完成,通过下面4步来完成JVM环境.
1.创建JVM装载环境和配置
2.装载JVM.dll
3.初始化JVM.dll并挂界到JNIENV(JNI调用接口)实例
4.调用JNIEnv实例装载并处理class类。
详见:http://blog.csdn.net/ning109314/article/details/10411495
5、Class文件结构
Class文件的总体结构如下:
Class文件 {
文件描述
常量池
类概述
字段表
方法表
扩展信息表
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.5.1 文件描述
(1)magic位、class文件版本号。Magic位很容易记住,数值是0xCAFEBABE。
(2)常量池
存储一组常量,供class文件中其它元素引用。常量池中顺序存储着一组常量,常量在池中的位置称为索引。Class文件中其它结构通过索引来引用常量。常量最主要是被指令引用。编译器将源码编译成指令和常量,图形表示如下:
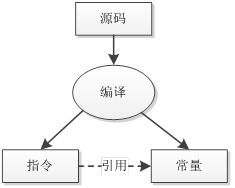
(3)类概述
存储了当前类的总体信息,包括当前类名、所继承的父类、所实现的接口。
(4)字段表
存储了一组字段结构,类中每个字段对应一个字段结构。
字段结构存储了字段的信息,包括字段名、字段修饰符、字段指向的类型等。
(5)方法表
存储了一组方法结构,类中每个方法对应一个方法结构。
方法结构比较复杂,它内部最重要的结构是Code结构。每个非抽象方法的方法结构下有一个Code结构,存储了方法的字节码。
(6)扩展信息表
存储了类级别的可选信息,例如类级别的annotation。(方法、字段级别的annotation分别存储在方法结构、字段结构中)
1.5.2 栈结构
我们对于站结构的内部构造,大部分则了解甚少。字节码的执行依赖栈结构,理解栈结构是理解字节码的基础。
栈由帧组成,一个帧对应一个方法调用。一个方法被调用时,一个帧被创建,方法返回时,对应的帧被销毁。
帧存储了方法执行期间的数据,包括变量数据和计算的中间结果。帧由两部分组成,变量表和操作栈。这两个结构是字节码执行期间直接依赖的两个结构
操作栈
顾名思义,操作栈是一个栈结构,即LIFO结构。操作栈位于帧内部,用于存储方法执行期间的中间结果。操作栈在JVM中的角色,类似于寄存器在实体机中的角色。
字节码中绝大多数指令,都是围绕着操作栈执行的。它们或是从其他地方读数据,压入操作栈;或是从操作栈弹数据进行处理;还有的先弹数据,再处理,最会将结果压入操作。
在JVM中,要对数据进行处理,首先要把数据读进操作栈。
int变量求和
要对两个int变量求和,我们先通过iload指令量两个变量压入操作栈,然后执行iadd指令。iadd从操作栈弹出两个int值,求和,然后将结果压入操作栈。
调用方法对象
调用对象方法时,我们需要将被调用对象,调用参数依次压入操作栈,然后执行invokevirtual指令。该指令从操作栈弹出调用参数,被调用对象,执行方法调用。
变量表
变量表用于存储变量数据。
变量表由一组槽组成。一个槽能够存储一个除long、double外其他类型的数据。两个槽能够存储一个long型或double型数据。变量所在的槽在变量表中位置称为变量索引,对于long和double类型,变量索引是第一个槽的位置。
变量在表量表中的顺序是:
this、方法参数(从左向右)、其它变量
如果是static方法,则this没有。
示例:
有如下方法:
void test(int a,int b){
int c=0;
long d=0;
}
- 1
- 2
- 3
- 4
其对应的变量表为:
![]()
二、Java基础
1、什么是接口?什么是抽象类?区别是什么?
2.1.1 接口
在软件工程中,接口泛指供别人调用的方法或者函数。从这里,我们可以体会到Java语言设计者的初衷,它是对行为的抽象。
接口中可以含有 变量和方法。但是要注意,接口中的变量会被隐式地指定为public static final变量(并且只能是public static final变量,用private修饰会报编译错误),而方法会被隐式地指定为public abstract方法且只能是public abstract方法(用其他关键字,比如private、protected、static、 final等修饰会报编译错误),并且接口中所有的方法不能有具体的实现,也就是说,接口中的方法必须都是抽象方法。从这里可以隐约看出接口和抽象类的区别,接口是一种极度抽象的类型,它比抽象类更加“抽象”,并且一般情况下不在接口中定义变量。
可以看出,允许一个类遵循多个特定的接口。如果一个非抽象类遵循了某个接口,就必须实现该接口中的所有方法。对于遵循某个接口的抽象类,可以不实现该接口中的抽象方法。
2.1.2 抽象类
抽象方法是一种特殊的方法:它只有声明,而没有具体的实现。抽象方法的声明格式为:
abstract void fun();
- 1
抽象方法必须用abstract关键字进行修饰。如果一个类含有抽象方法,则称这个类为抽象类,抽象类必须在类前用abstract关键字修饰。因为抽象类中含有无具体实现的方法,所以不能用抽象类创建对象。
下面要注意一个问题:在《JAVA编程思想》一书中,将抽象类定义为“包含抽象方法的类”,但是后面发现如果一个类不包含抽象方法,只是用abstract修饰的话也是抽象类。也就是说抽象类不一定必须含有抽象方法。个人觉得这个属于钻牛角尖的问题吧,因为如果一个抽象类不包含任何抽象方法,为何还要设计为抽象类?所以暂且记住这个概念吧,不必去深究为什么。
/** * Created by hupo.wh on 2016/7/7. */
public abstract class AbstractClass {
public void ab() {
System.out.println("Hello");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
从这里可以看出,抽象类就是为了继承而存在的,如果你定义了一个抽象类,却不去继承它,那么等于白白创建了这个抽象类,因为你不能用它来做任何事情。对于一个父类,如果它的某个方法在父类中实现出来没有任何意义,必须根据子类的实际需求来进行不同的实现,那么就可以将这个方法声明为abstract方法,此时这个类也就成为abstract类了。
包含抽象方法的类称为抽象类,但并不意味着抽象类中只能有抽象方法,它和普通类一样,同样可以拥有成员变量和普通的成员方法。注意,抽象类和普通类的主要有三点区别:
1)抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public。
2)抽象类不能用来创建对象;
3)如果一个类继承于一个抽象类,则子类必须实现父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
在其他方面,抽象类和普通的类并没有区别。
2.1.3 区别
2.1.3.1 语法层面上的区别
1)抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
2)抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
3)接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
4)一个类只能继承一个抽象类,而一个类却可以实现多个接口。
2.1.3.2 设计层面上的区别
1)抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。
抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。举个简单的例子,飞机和鸟是不同类的事物,但是它们都有一个共性,就是都会飞。那么在设计的时候,可以将飞机设计为一个类Airplane,将鸟设计为一个类Bird,但是不能将 飞行 这个特性也设计为类,因此它只是一个行为特性,并不是对一类事物的抽象描述。此时可以将 飞行 设计为一个接口Fly,包含方法fly( ),然后Airplane和Bird分别根据自己的需要实现Fly这个接口。然后至于有不同种类的飞机,比如战斗机、民用飞机等直接继承Airplane即可,对于鸟也是类似的,不同种类的鸟直接继承Bird类即可。从这里可以看出,继承是一个 “是不是”的关系,而 接口 实现则是 “有没有”的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。
2)设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。
什么是模板式设计?最简单例子,大家都用过ppt里面的模板,如果用模板A设计了ppt B和ppt C,ppt B和ppt C公共的部分就是模板A了,如果它们的公共部分需要改动,则只需要改动模板A就可以了,不需要重新对ppt B和ppt C进行改动。而辐射式设计,比如某个电梯都装了某种报警器,一旦要更新报警器,就必须全部更新。也就是说对于抽象类,如果需要添加新的方法,可以直接在抽象类中添加具体的实现,子类可以不进行变更;而对于接口则不行,如果接口进行了变更,则所有实现这个接口的类都必须进行相应的改动。
详见好文:http://www.cnblogs.com/dolphin0520/p/3811437.html
2、什么是序列化?
2.2.1 概念
序列化,序列化是可以把对象转换成字节流在网络上传输。将一个java对象变成字节流的形式传出去或者从一个字节流中恢复成一个java对象。
个人认为,序列化就是一种思想,能够完成转换,能够转换回来,效率越高越好
序列化(Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。之后可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
java中的序列化(serialization)机制能够将一个实例对象的状态信息写入到一个字节流中,使其可以通过socket进行传输、或者持久化存储到数据库或文件系统中;然后在需要的时候,可以根据字节流中的信息来重构一个相同的对象。序列化机制在java中有着广泛的应用,EJB、RMI等技术都是以此为基础的。
一般而言,要使得一个类可以序列化,只需简单实现java.io.Serializable接口即可(还要实现无参数的构造方法)。该接口是一个标记式接口,它本身不包含任何内容,实现了该接口则表示这个类准备支持序列化的功能。
2.2.2 序列化与反序列化例程
序列化一般有三种形式:默认形式、xml、json格式
默认格式如下:
package serializable;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
/** * Created by hupo.wh on 2016/7/3. */
public class SerializeToFlatFile {
public static void main(String[] args) {
SerializeToFlatFile ser = new SerializeToFlatFile();
ser.savePerson();
ser.restorePerson();
}
public void savePerson(){
Person myPerson = new Person("Jay", 24);
try{
FileOutputStream fos = new FileOutputStream("d:\\person.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);
System.out.println("Person--Jay,24---Written");
oos.writeObject(myPerson);
oos.flush();
oos.close();
}catch(Exception e){
e.printStackTrace();
}
}
//@SuppressWarnings("resource")
public void restorePerson(){
try{
FileInputStream fls = new FileInputStream("d:\\person.txt");
ObjectInputStream ois = new ObjectInputStream(fls);
Person myPerson = (Person)ois.readObject();
System.out.println("\n---------------------\n");
System.out.println("Person --read:");
System.out.println("Name is:"+myPerson.getName());
System.out.println("Age is :"+myPerson.getAge());
}catch(Exception e){
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
另两种大同小异
2.2.3 应用场景
序列化的实现:将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流
详见:http://blog.csdn.net/scythe666/article/details/51718784
三种情况下需要进行序列化
1、把对象持久化到文件或数据中
2、在网络上传输
3、进行RMI传输对象时
RPC和RMI都是远程调用,属于中间件技术。RMI是针对于java语言的,它使用的是JRMP协议通信,而RPC是更大众化的,使用http协议传输。
其版本号id,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
常用序列化技术有3种:java seriaizable,hessian,hessian2,以及protobuf
工具有很多,网上有个对比:
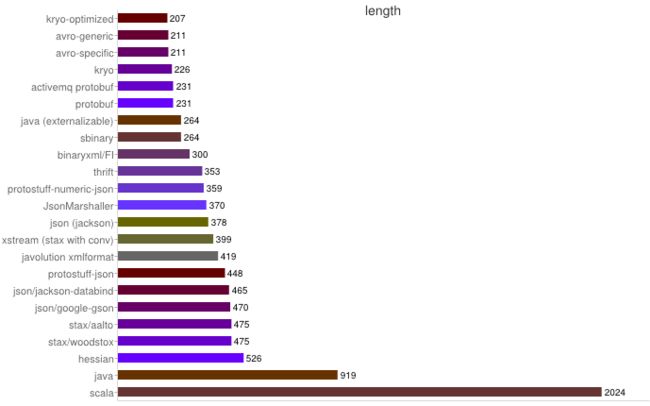
详见:http://kb.cnblogs.com/page/515982/
3、网络通信过程及实践
2.3.1 TCP三次握手和四次挥手
明显三次握手是建立连接,四次挥手是断开连接,总图如下:
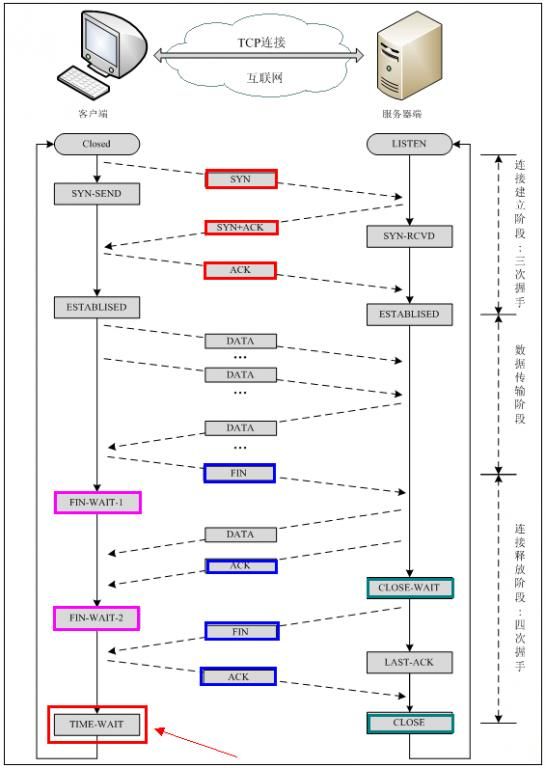
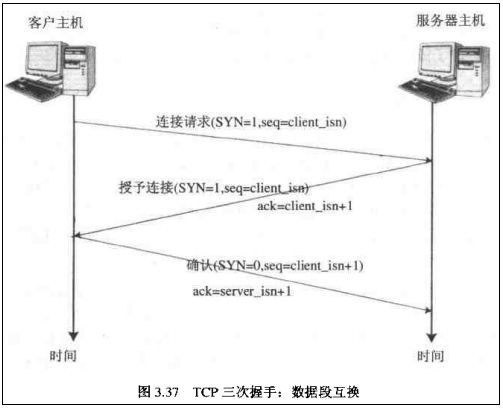
2.3.1.1 握手
(1)首先,Client端发送连接请求报文(SYN=1,seq=client_isn)
(2)Server段接受连接后回复ACK报文,并为这次连接分配资源。(SYN=1,seq=client_isn,ack = client_isn+1)
(3)Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了。(SYN=0,seq=client_isn+1,ack = server_isn+1)
三次握手过程如下图所示:
2.3.1.2 挥手
注意:
中断连接端可以是Client端,也可以是Server端。
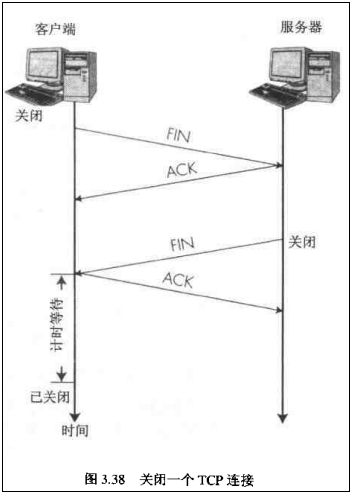
(1)假设Client端发起中断连接请求,也就是发送FIN报文。
(2) Server端接到FIN报文后,意思是说”我Client端没有数据要发给你了”,但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以 Server 端会先发送ACK,”告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息”。
这个时候Client端就进入 FIN_WAIT 状态,继续等待Server端的FIN报文。
(3)当Server端确定数据已发送完成,则向Client端发送FIN报文,”告诉Client端,好了,我这边数据发完了,准备好关闭连接了”。
(4)Client端收到FIN报文后,”就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送 ACK 后进入 TIME_WAIT 状态,如果 Server 端没有收到 ACK 则可以重传“,Server端收到ACK后,”就知道可以断开连接了”。
Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!
注意:
(1)2个wait状态,FIN_WAIT和TIME_WAIT
(2)如果是Server端发起,过程反过来,因为在挥手的时候c和s在对等位置。
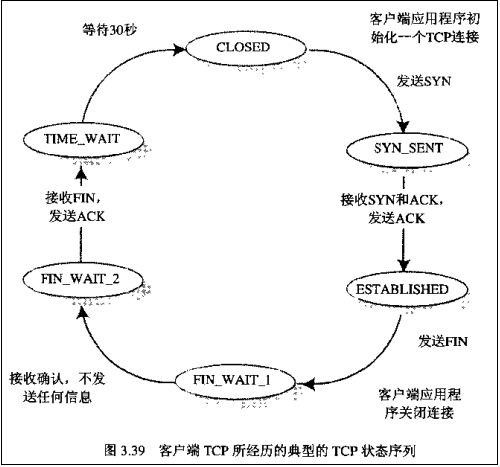
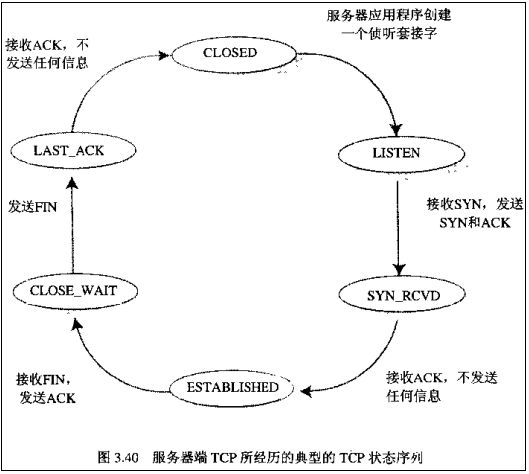
2.3.1.3 握手挥手状态图
Client端所经历的状态如下:
Server端所经历的过程如下:
2.3.1.4 注意问题
1、在TIME_WAIT状态中,如果TCP client端最后一次发送的ACK丢失了,它将重新发送。TIME_WAIT状态中所需要的时间是依赖于实现方法的。典型的值为30秒、1分钟和2分钟。等待之后连接正式关闭,并且所有的资源(包括端口号)都被释放。
2、为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,”你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
3、为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
2.3.1.5 附:报文详解
TCP报文中的SYN,FIN,ACK,PSH,RST,URG
TCP的三次握手是怎么进行的:发送端发送一个SYN=1,ACK=0标志的数据包给接收端,请求进行连接,这是第一次握手;接收端收到请求并且允许连接的话,就会发送一个SYN=1,ACK=1标志的数据包给发送端,告诉它,可以通讯了,并且让发送端发送一个确认数据包,这是第二次握手;最后,发送端发送一个SYN=0,ACK=1的数据包给接收端,告诉它连接已被确认,这就是第三次握手。之后,一个TCP连接建立,开始通讯。
*SYN:同步标志
同步序列编号(Synchronize Sequence Numbers)栏有效。该标志仅在三次握手建立TCP连接时有效。它提示TCP连接的服务端检查序列编号,该序列编号为TCP连接初始端(一般是客户端)的初始序列编号。在这里,可以把 TCP序列编号看作是一个范围从0到4,294,967,295的32位计数器。通过TCP连接交换的数据中每一个字节都经过序列编号。在TCP报头中的序列编号栏包括了TCP分段中第一个字节的序列编号。*ACK:确认标志
确认编号(Acknowledgement Number)栏有效。大多数情况下该标志位是置位的。TCP报头内的确认编号栏内包含的确认编号(w+1,Figure-1)为下一个预期的序列编号,同时提示远端系统已经成功接收所有数据。*RST:复位标志
复位标志有效。用于复位相应的TCP连接。*URG:紧急标志
紧急(The urgent pointer) 标志有效。紧急标志置位*PSH:推标志
该标志置位时,接收端不将该数据进行队列处理,而是尽可能快将数据转由应用处理。在处理 telnet 或 rlogin 等交互模式的连接时,该标志总是置位的。*FIN:结束标志
带有该标志置位的数据包用来结束一个TCP回话,但对应端口仍处于开放状态,准备接收后续数据。
TCP的几个状态对于我们分析所起的作用
在TCP层,有个FLAGS字段,这个字段有以下几个标识:SYN, FIN, ACK, PSH, RST, URG.其中,对于我们日常的分析有用的就是前面的五个字段。它们的含义是:SYN表示建立连接,FIN表示关闭连接,ACK表示响应,PSH表示有 DATA数据传输,RST表示连接重置。其中,ACK是可能与SYN,FIN等同时使用的,比如SYN和ACK可能同时为1,它表示的就是建立连接之后的响应,如果只是单个的一个SYN,它表示的只是建立连接。
TCP的几次握手就是通过这样的ACK表现出来的。但SYN与FIN是不会同时为1的,因为前者表示的是建立连接,而后者表示的是断开连接。RST一般是在FIN之后才会出现为1的情况,表示的是连接重置。一般地,当出现FIN包或RST包时,我们便认为客户端与服务器端断开了连接;而当出现SYN和SYN+ACK包时,我们认为客户端与服务器建立了一个连接。PSH为1的情况,一般只出现在 DATA内容不为0的包中,也就是说PSH为1表示的是有真正的TCP数据包内容被传递。TCP的连接建立和连接关闭,都是通过请求-响应的模式完成的。
详见:http://blog.csdn.net/scythe666/article/details/50967632
tcp的状态
http://www.cnblogs.com/qlee/archive/2011/07/12/2104089.html
http://www.2cto.com/net/201209/157585.html
2.3.2 Socket通信
套接字(socket)是通信的基石,是支持TCP/IP协议的网络通信的基本操作单元。它是网络通信过程中端点的抽象表示,包含进行网络通信必须的五种信息:连接使用的协议,本地主机的IP地址,本地进程的协议端口,远地主机的IP地址,远地进程的协议端口。
套接字对是一个四元组,(local ip, local port, remote ip, remote port),通过这一四元组,唯一确定了网络通信的两端(两个进程或线程),ip地址确定主机,端口确定进程。
经典的在同一台主机上两个进程或线程之间的通信通过以下三种方法
管道通信(Pipes)
消息队列(Message queues)
共享内存通信(Shared memory)
这里有许多其他的方法,但是上面三中是非常经典的进程间通信。
详见:http://blog.csdn.net/violet_echo_0908/article/details/49539593
socket编程实例:
/////TalkClient .java
package socket;
import java.io.*;
import java.net.*;
/** * Created by hupo.wh on 2016/7/8. */
public class TalkClient {
public static void main(String args[]) {
try {
Socket socket = new Socket("10.63.37.140", 4700);
//向本机的4700端口发出客户请求
BufferedReader sin = new BufferedReader(new InputStreamReader(System.in));
//由系统标准输入设备构造BufferedReader对象
PrintWriter os = new PrintWriter(socket.getOutputStream());
//由Socket对象得到输出流,并构造PrintWriter对象
BufferedReader is = new BufferedReader(new InputStreamReader(socket.getInputStream()));
//由Socket对象得到输入流,并构造相应的BufferedReader对象
String readline;
readline = sin.readLine(); //从系统标准输入读入一字符串
while (!readline.equals("bye")) {
//若从标准输入读入的字符串为 "bye"则停止循环
os.println(readline);
//将从系统标准输入读入的字符串输出到Server
os.flush();
//刷新输出流,使Server马上收到该字符串
System.out.println("Client:" + readline);
//在系统标准输出上打印读入的字符串
System.out.println("Server:" + is.readLine());
//从Server读入一字符串,并打印到标准输出上
readline = sin.readLine(); //从系统标准输入读入一字符串
} //继续循环
os.close(); //关闭Socket输出流
is.close(); //关闭Socket输入流
socket.close(); //关闭Socket
} catch (Exception e) {
System.out.println("Error" + e); //出错,则打印出错信息
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
/////TalkServer.java
package socket;
/** * Created by hupo.wh on 2016/7/8. */
import java.io.*;
import java.net.*;
public class TalkServer{
public static void main(String args[]) {
try{
ServerSocket server=null;
try{
server=new ServerSocket(4700);
//创建一个ServerSocket在端口4700监听客户请求
}catch(Exception e) {
System.out.println("can not listen to:"+e);
//出错,打印出错信息
}
Socket socket=null;
try{
socket=server.accept();
//使用accept()阻塞等待客户请求,有客户
//请求到来则产生一个Socket对象,并继续执行
System.out.println("客户端成功连接...");
}catch(Exception e) {
System.out.println("Error."+e);
//出错,打印出错信息
}
String line;
BufferedReader is=new BufferedReader(new InputStreamReader(socket.getInputStream()));
//由Socket对象得到输入流,并构造相应的BufferedReader对象
PrintWriter os = new PrintWriter(socket.getOutputStream());
//由Socket对象得到输出流,并构造PrintWriter对象
BufferedReader sin=new BufferedReader(new InputStreamReader(System.in));
//由系统标准输入设备构造BufferedReader对象
System.out.println("Client:"+is.readLine());
//在标准输出上打印从客户端读入的字符串
line=sin.readLine();
//从标准输入读入一字符串
while(!line.equals("bye")){
//如果该字符串为 "bye",则停止循环
os.println(line);
//向客户端输出该字符串
os.flush();
//刷新输出流,使Client马上收到该字符串
System.out.println("Server:"+line);
//在系统标准输出上打印读入的字符串
System.out.println("Client:"+is.readLine());
//从Client读入一字符串,并打印到标准输出上
line=sin.readLine();
//从系统标准输入读入一字符串
} //继续循环
os.close(); //关闭Socket输出流
is.close(); //关闭Socket输入流
socket.close(); //关闭Socket
server.close(); //关闭ServerSocket
}catch(Exception e){
System.out.println("Error:"+e);
//出错,打印出错信息
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
详见:http://www.cnblogs.com/linzheng/archive/2011/01/23/1942328.html
2.3.3 Http
HTTP协议是无状态的,同一个客户端的这次请求和上次请求是没有对应关系,对http服务器来说,它并不知道这两个请求来自同一个客户端。 为了解决这个问题, Web程序引入了Cookie机制来维护状态.
Http响应
在接收和解释请求消息后,服务器返回一个HTTP响应消息。
HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文
1、状态行格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
其中,HTTP-Version表示服务器HTTP协议的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
eg:HTTP/1.1 200 OK (CRLF)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2、响应报头
3、响应正文就是服务器返回的资源的内容
详见:(1)http://www.cnblogs.com/li0803/archive/2008/11/03/1324746.html
(2)http://kb.cnblogs.com/page/130970/#statelesshttp
(3)http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386832653051fd44e44e4f9e4ed08f3e5a5ab550358d000
4、什么是线程?java线程池运行过程及实践(Executors)
一个进程包括多个线程,但是这些线程是共同享有进程占有的资源和地址空间的。
进程是操作系统进行资源分配的基本单位,而线程是操作系统进行调度的基本单位。
进程可能包括多个线程。
好文:http://www.oschina.net/question/565065_86540
2.4.1 Volatile
线程的工作内存中保存了被该线程使用到的变量的主内存的副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量(包括volatile的底层实现)。
这里的主内存、工作内存和Java堆栈、方法区不是一个层次内存划分,基本上没有关系。
如果要勉强对应:主内存对应Java堆中对象实例数据部分,工作内存对应于虚拟机栈中部分区域。
从更低层次来说,主内存就直接对应物理硬件内存,而为了优化,工作内存优先储存于寄存器和高速缓存中。
volatile可以说是Java虚拟机提供的最轻量级的同步机制。
当一个变量定义为volatile以后,它将具备两种属性:
(1)保证此变量对所有线程的可见性
volatile的错误用法:
package MultiThread;
/** * Created by hupo.wh on 2016/7/8. */
public class VolatileTest {
private static final int THREAD_NUM =20;
public static volatile int race= 0;
public static void increase(){
race++ ;
}
public static void main(String[] args) {
Thread[] threads = new Thread[THREAD_NUM];
for (int i = 0; i < THREAD_NUM; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for(int i=0;i<10000;i++){
//System.out.println("race == "+race);
increase();
}
}
});
threads[i].start();
}
while(Thread.activeCount()>2){
Thread.yield();
}
System.out.println(race);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
输出的正确答案应该是200000,但是每次输出都小于200000,并发失败的问题在于increase()方法。用javap发编译看一下发现就increase()方法在Class中文件有四条字节码组成。
volatile变量只能保证可见性,当不符合一下规则是还是使用synchronized或java.util.concurrent中的原子类。
1.运算结果并不依赖变量的当前值,或者能够确保单一的线程修改变量的
2.变量不需要与其他的状态变量共同参与不变约束。
正确用法:
package MultiThread;
/** * Created by hupo.wh on 2016/7/8. */
public class VolatileShutdown {
volatile boolean shutdownRequested;
public void shutdown() {
shutdownRequested = true;
}
public void doWork() {
while (!shutdownRequested) {
//do stuff
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
(2)使用volatile变量的第二个语义是禁止指令重排序优化
2.4.2 原子性、可见性与有序性
(1)原子性
保证read、load、assign、use、store和write操作是原子的
(2)可见性
当一个线程修改了共享变量的值,其他线程可以立即得知这个修改
(3)有序性
本线程观察,所有的操作都是有序的,如果在一个线程中观察另一个线程,所有操作都是无序的(指令重排序和工作内存与主内存同步延迟)。
2.4.3 Lock vs Synchronized
Synchronized关键字经过编译以后,会在同步块前后分别形成monitorenter和monitorexit这两个字节码指令。Synchronized 使用详见:http://blog.csdn.net/luoweifu/article/details/46613015
主要相同点:lock能完成synchronized所实现的所有功能
主要不同点:lock有比synchronized更精确的线程语义和更好的性能.synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放.
1、ReentrantLock 拥有Synchronized相同的并发性和内存语义,此外还多了 锁投票,定时锁等候和中断锁等候
线程A和B都要获取对象O的锁定,假设A获取了对象O锁,B将等待A释放对O的锁定,
如果使用 synchronized ,如果A不释放,B将一直等下去,不能被中断
如果 使用ReentrantLock,如果A不释放,可以使B在等待了足够长的时间以后,中断等待,而干别的事情
ReentrantLock获取锁定与三种方式:
a) lock(), 如果获取了锁立即返回,如果别的线程持有锁,当前线程则一直处于休眠状态,直到获取锁
b) tryLock(), 如果获取了锁立即返回true,如果别的线程正持有锁,立即返回false;
c)tryLock(long timeout,TimeUnit unit), 如果获取了锁定立即返回true,如果别的线程正持有锁,会等待参数给定的时间,在等待的过程中,如果获取了锁定,就返回true,如果等待超时,返回false;
d) lockInterruptibly:如果获取了锁定立即返回,如果没有获取锁定,当前线程处于休眠状态,直到或者锁定,或者当前线程被别的线程中断
2、synchronized是在JVM层面上实现的,不但可以通过一些监控工具监控synchronized的锁定,而且在代码执行时出现异常,JVM会自动释放锁定,但是使用Lock则不行,lock是通过代码实现的,要保证锁定一定会被释放,就必须将unLock()放到finally{}中
3、在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
2.4.4 threadlocal
ThreadLocal 不是用于解决共享变量的问题的,不是为了协调线程同步而存在,而是为了方便每个线程处理自己的状态而引入的一个机制,理解这点对正确使用ThreadLocal至关重要。
我们先看一个简单的例子:
public class ThreadLocalTest {
//创建一个Integer型的线程本地变量
public static final ThreadLocal<Integer> local = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return 0;
}
};
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[5];
for (int j = 0; j < 5; j++) {
threads[j] = new Thread(new Runnable() {
@Override
public void run() {
//获取当前线程的本地变量,然后累加5次
int num = local.get();
for (int i = 0; i < 5; i++) {
num++;
}
//重新设置累加后的本地变量
local.set(num);
System.out.println(Thread.currentThread().getName() + " : "+ local.get());
}
}, "Thread-" + j);
}
for (Thread thread : threads) {
thread.start();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
运行后结果:
Thread-0 : 5
Thread-4 : 5
Thread-2 : 5
Thread-1 : 5
Thread-3 : 5
我们看到,每个线程累加后的结果都是5,各个线程处理自己的本地变量值,线程之间互不影响。
详见:http://my.oschina.net/clopopo/blog/149368
2.4.5 java线程池 Executor框架
要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,很有可能配置的线程池不是较优的,因此在Executors类里面提供了一些静态工厂,生成一些常用的线程池。
(1)newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
MyThread.java
package threadpool;
/** * Created by hupo.wh on 2016/7/2. */
public class WhThread extends Thread{
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "正在执行...");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
TestSingleThreadExecutor.java
package threadpool;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/** * Created by hupo.wh on 2016/7/3. */
public class TestSingleThreadExecutor {
public static void main(String[] args) {
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors. newSingleThreadExecutor();
//创建实现了Runnable接口对象,Thread对象当然也实现了Runnable接口
Thread t1 = new WhThread();
Thread t2 = new WhThread();
Thread t3 = new WhThread();
Thread t4 = new WhThread();
Thread t5 = new WhThread();
//将线程放入池中进行执行
pool.execute(t1);
pool.execute(t2);
pool.execute(t3);
pool.execute(t4);
pool.execute(t5);
//关闭线程池
pool.shutdown();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
输出结果:
pool-1-thread-1正在执行…
pool-1-thread-1正在执行…
pool-1-thread-1正在执行…
pool-1-thread-1正在执行…
pool-1-thread-1正在执行…
(2)newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors.newFixedThreadPool(2);
- 1
- 2
(3)newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors.newCachedThreadPool();
- 1
- 2
(4)newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
package threadpool;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/** * Created by hupo.wh on 2016/7/3. */
public class TestSingleThreadExecutor {
public static void main(String[] args) {
ScheduledThreadPoolExecutor exec = new ScheduledThreadPoolExecutor(1);
exec.scheduleAtFixedRate(new Runnable() {//每隔一段时间就触发异常
@Override
public void run() {
System.out.println("================");
throw new RuntimeException();
}
}, 1000, 5000, TimeUnit.MILLISECONDS);
exec.scheduleAtFixedRate(new Runnable() {//每隔一段时间打印系统时间,证明两者是互不影响的
@Override
public void run() {
System.out.println(System.nanoTime());
}
}, 1000, 2000, TimeUnit.MILLISECONDS);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
ThreadPoolExecutor构造函数
jvm本身提供的concurrent并发包,提供了高性能稳定方便的线程池,可以直接使用。
ThreadPoolExecutor是核心类,都是由它与3种Queue结合衍生出来的。
BlockingQueue + LinkedBlockingQueue + SynchronousQueue
ThreadPoolExecutor的完整构造方法的签名是:
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) .
- 1
corePoolSize - 池中所保存的线程数,包括空闲线程。
maximumPoolSize-池中允许的最大线程数。
keepAliveTime - 当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
unit - keepAliveTime 参数的时间单位。
workQueue - 执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务。
threadFactory - 执行程序创建新线程时使用的工厂。
handler - 由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序。
ThreadPoolExecutor是Executors类的底层实现。
在JDK帮助文档中,有如此一段话:
“强烈建议程序员使用较为方便的Executors工厂方法Executors.newCachedThreadPool()(无界线程池,可以进行自动线程回收)、Executors.newFixedThreadPool(int)(固定大小线程池)Executors.newSingleThreadExecutor()(单个后台线程)
线程池实现原理
先从 BlockingQueue<Runnable> workQueue 这个入参开始说起。在JDK中,其实已经说得很清楚了,一共有三种类型的queue。
所有BlockingQueue 都可用于传输和保持提交的任务。可以使用此队列与池大小进行交互:
(1)如果运行的线程少于 corePoolSize,则 Executor始终首选添加新的线程,而不进行排队。(如果当前运行的线程小于corePoolSize,则任务根本不会存放,添加到queue中,而是直接抄家伙(thread)开始运行)
(2)如果运行的线程等于或多于 corePoolSize,则 Executor始终首选将请求加入队列,而不添加新的线程。
(3)如果无法将请求加入队列,则创建新的线程,除非创建此线程超出maximumPoolSize,在这种情况下,任务将被拒绝。
线程的状态有 new、runnable、running、waiting、timed_waiting、blocked、dead 一旦线程调用了start 方法,线程就转到Runnable 状态,注意,如果线程处于Runnable状态,它也有可能不在运行,这是因为还有优先级和调度问题。
排队策略
排队有三种通用策略:
(1)直接提交。工作队列的默认选项是 SynchronousQueue,ExecutorService newCachedThreadPool():无界线程池,可以进行自动线程回收,所以我们可以发现maximumPoolSize为big big。
(2)无界队列。使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
(3)有界队列。当使用有限的 maximumPoolSizes时,有界队列(如 ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
keepAliveTime
jdk中的解释是:当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
有点拗口,其实这个不难理解,在使用了“池”的应用中,大多都有类似的参数需要配置。比如数据库连接池,DBCP中的maxIdle,minIdle参数。
什么意思?接着上面的解释,后来向老板派来的工人始终是“借来的”,俗话说“有借就有还”,但这里的问题就是什么时候还了,如果借来的工人刚完成一个任务就还回去,后来发现任务还有,那岂不是又要去借?这一来一往,老板肯定头也大死了。
合理的策略:既然借了,那就多借一会儿。直到“某一段”时间后,发现再也用不到这些工人时,便可以还回去了。这里的某一段时间便是keepAliveTime的含义,TimeUnit为keepAliveTime值的度量。
详参:http://www.oschina.net/question/565065_86540
5、java反射机制实践
详见:http://blog.csdn.net/scythe666/article/details/51704809
反射可以拿到一个类所有的方法和属性,包括父类和接口。
package classloader;
import java.lang.reflect.Method;
/** * Created by hupo.wh on 2016/7/7. */
public class App3 {
private final static int size = 12;
public static void main(String args[]) throws ClassNotFoundException {
//System.out.println(size);
Class clazz = Class.forName("classloader.Child");
Method[] methods = clazz.getMethods();
for (int i=0;i<methods.length;++i) {
System.out.println(methods[i]);
}
}
}
interface Test{
int te = 0;
public void te();
}
abstract class Parent {
int pa;
public void pa() {
System.out.println("this is parent");
}
}
class Child extends Parent implements Test{
int ch;
public void ch() {
System.out.println("this is child");
}
@Override
public void te() {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
输出:
public void classloader.Child.ch()
public void classloader.Child.te()
public void classloader.Parent.pa()
public final void java.lang.Object.wait() throws java.lang.InterruptedException
public final void java.lang.Object.wait(long,int) throws java.lang.InterruptedException
public final native void java.lang.Object.wait(long) throws java.lang.InterruptedException
public boolean java.lang.Object.equals(java.lang.Object)
public java.lang.String java.lang.Object.toString()
public native int java.lang.Object.hashCode()
public final native java.lang.Class java.lang.Object.getClass()
public final native void java.lang.Object.notify()
public final native void java.lang.Object.notifyAll()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
三、设计模式
1、单例模式
//懒汉式单例类.在第一次调用的时候实例化自己
public class Singleton {
private Singleton() {}
private static Singleton single=null;
//静态工厂方法
public static Singleton getInstance() {
if (single == null) {
single = new Singleton();
}
return single;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
线程安全+懒加载实现:
public class TestSingleton {
private TestSingleton() {}
private static class SingletonHolder {
static TestSingleton testSingleton = new TestSingleton();
}
public TestSingleton getInstance() {
return SingletonHolder.testSingleton;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
详见:http://blog.csdn.net/jason0539/article/details/23297037
2、原型模式
类图:
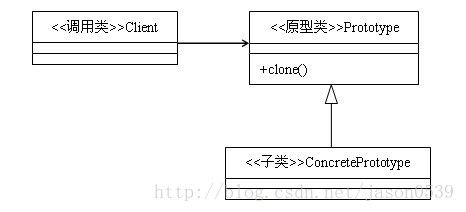
原型模式主要用于对象的复制,它的核心是就是类图中的原型类Prototype。Prototype类需要具备以下两个条件:
(1)实现Cloneable接口。在java语言有一个Cloneable接口,它的作用只有一个,就是在运行时通知虚拟机可以安全地在实现了此接口的类上使用clone方法。在java虚拟机中,只有实现了这个接口的类才可以被拷贝,否则在运行时会抛出CloneNotSupportedException异常。
(2)重写Object类中的clone方法。Java中,所有类的父类都是Object类,Object类中有一个clone方法,作用是返回对象的一个拷贝,但是其作用域protected类型的,一般的类无法调用,因此,Prototype类需要将clone方法的作用域修改为public类型。
原型模式是一种比较简单的模式,也非常容易理解,实现一个接口,重写一个方法即完成了原型模式。在实际应用中,原型模式很少单独出现。经常与其他模式混用,他的原型类Prototype也常用抽象类来替代。
class Prototype implements Cloneable {
public Prototype clone(){
Prototype prototype = null;
try{
prototype = (Prototype)super.clone();
}catch(CloneNotSupportedException e){
e.printStackTrace();
}
return prototype;
}
}
class ConcretePrototype extends Prototype{
public void show(){
System.out.println("原型模式实现类");
}
}
public class Client {
public static void main(String[] args){
ConcretePrototype cp = new ConcretePrototype();
for(int i=0; i< 10; i++){
ConcretePrototype clonecp = (ConcretePrototype)cp.clone();
clonecp.show();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
详见:http://blog.csdn.net/jason0539/article/details/23158081
3、动态代理模式
一般的设计模式中的代理模式指的是静态代理,但是Java实现了动态代理
静态代理的每一个代理类只能为一个或一组接口服务,这样一来程序开发中必然会产生过多的代理,而且,所有的代理操作除了调用的方法不一样之外,其他的操作都一样,则此时肯定是重复代码。解决这一问题最好的做法是可以通过一个代理类完成全部的代理功能,那么此时就必须使用动态代理完成。
来看一下动态代理:
JDK动态代理中包含一个类和一个接口:
InvocationHandler接口:
public interface InvocationHandler {
public Object invoke(Object proxy,Method method,Object[] args) throws Throwable;
}
- 1
- 2
- 3
参数说明:
Object proxy:指被代理的对象。
Method method:要调用的方法 Object[] args:方法调用时所需要的参数
- 1
- 2
- 3
可以将InvocationHandler接口的子类想象成一个代理的最终操作类,替换掉ProxySubject。
Proxy类:
Proxy类是专门完成代理的操作类,可以通过此类为一个或多个接口动态地生成实现类,此类提供了如下的操作方法:
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces,
InvocationHandler h) throws IllegalArgumentException
- 1
- 2
参数说明:
ClassLoader loader:类加载器
Class<?>[] interfaces:得到全部的接口 InvocationHandler h:得到InvocationHandler接口的子类实例
- 1
- 2
- 3
Ps:类加载器
在Proxy类中的newProxyInstance()方法中需要一个ClassLoader类的实例,ClassLoader实际上对应的是类加载器,在Java中主要有一下三种类加载器;
Booststrap ClassLoader:此加载器采用C++编写,一般开发中是看不到的;
Extendsion ClassLoader:用来进行扩展类的加载,一般对应的是jre\lib\ext目录中的类;
AppClassLoader:(默认)加载classpath指定的类,是最常使用的是一种加载器。
动态代理
与静态代理类对照的是动态代理类,动态代理类的字节码在程序运行时由Java反射机制动态生成,无需程序员手工编写它的源代码。动态代理类不仅简化了编程工作,而且提高了软件系统的可扩展性,因为Java 反射机制可以生成任意类型的动态代理类。java.lang.reflect 包中的Proxy类和InvocationHandler 接口提供了生成动态代理类的能力。
/////BookFacade.java
package jdkproxy;
/** * Created by hupo.wh on 2016/7/4. */
public interface BookFacade {
public void addBook();
public void sayHello();
}
/////BookFacadeImpl.java
package jdkproxy;
/** * Created by hupo.wh on 2016/7/4. */
public class BookFacadeImpl implements BookFacade {
@Override
public void addBook() {
System.out.println("增加图书方法...");
}
public void sayHello(){
System.out.println("Hello");
}
}
/////BookFacadeProxy.java
package jdkproxy;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
/** * jdk动态代理类 * Created by hupo.wh on 2016/7/4. */
public class BookFacadeProxy implements InvocationHandler {
private Object target;
/** * 绑定委托对象并返回一个代理类 * @param target * @return */
public Object bind(Object target) {
this.target = target;
//取得代理对象
return Proxy.newProxyInstance(target.getClass().getClassLoader(),
target.getClass().getInterfaces(), this); //要绑定接口(这是一个缺陷,cglib弥补了这一缺陷)
}
@Override
/** * 调用方法,自动调用 */
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
Object result=null;
System.out.println("事物开始");
//执行方法
result=method.invoke(target, args);
System.out.println("事物结束");
return result;
}
}
/////App1.java
package jdkproxy;
/** * Created by hupo.wh on 2016/7/4. */
public class App1 {
public static void main(String[] args) {
BookFacadeProxy proxy = new BookFacadeProxy();
BookFacade bookProxy = (BookFacade) proxy.bind(new BookFacadeImpl());
bookProxy.addBook();
bookProxy.sayHello();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
但是,JDK的动态代理依靠接口实现,如果有些类并没有实现接口,则不能使用JDK代理,这就要使用cglib动态代理了。
Cglib动态代理
JDK的动态代理机制只能代理实现了接口的类,而不能实现接口的类就不能实现JDK的动态代理,cglib是针对类来实现代理的,他的原理是对指定的目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对final修饰的类进行代理。
详见:http://www.cnblogs.com/jqyp/archive/2010/08/20/1805041.html
四、Spring
1、什么是IOC
IOC(inverse of controll)控制反转(控制权反转),就是把创建对象(bean),和维护对象(bean)的关系和权力从程序中转移到spring的容器(applicationContext.xml),而程序本身不再关心、维护对象创建和关系
2、什么是AOP
aop( aspect oriented programming ) 面向切面(方面)编程,是对所有对象或者是一类对象编程,核心是( 在不增加代码的基础上, 还增加新功能 ),aop实现原理是代理。
面向切面 spring( ->aop) 面向n多对象编程,面向一批对象编程
交叉点,交叉功能放入的过程叫做织入
使用比较底层的ProxyFactoryBean编程说明:
步骤:
1. 定义接口
2. 编写对象(被代理对象=目标对象)
3. 编写通知(前置通知目标方法调用前调用)
4. 在beans.xml文件配置
4.1 配置 被代理对象=目标对象
4.2 配置通知
4.3 配置代理对象 是 ProxyFactoryBean的对象实例
4.3.1 代理接口集
4.3.2 织入通知
4.3.3 配置被代理对象
1.切面(aspect):要实现的交叉功能,是系统模块化的一个切面或领域。如日志记录。
2.连接点:应用程序执行过程中插入切面的地点,可以是方法调用,异常抛出,或者要修改的
字段。
3.通知:切面的实际实现,他通知系统新的行为。如在日志通知包含了实
现日志功能的代码,如向日志文件写日志。通知在连接点插入到应用系统中。
4.切入点:定义了通知应该应用在哪些连接点,通知可以应用到AOP框架支持的任何连接点。
5.引入:为类添加新方法和属性。
6.目标对象:被通知的对象。既可以是你编写的类也可以是第三方类。
7.代理:将通知应用到目标对象后创建的对象,应用系统的其他部分不用为了支持代理对象而
改变。
8.织入:将切面应用到目标对象从而创建一个新代理对象的过程。织入发生在目标
对象生命周期的多个点上:
编译期:切面在目标对象编译时织入.这需要一个特殊的编译器.
类装载期:切面在目标对象被载入JVM时织入.这需要一个特殊的类载入器.
运行期:切面在应用系统运行时织入.
提问? 说spring的aop中,当你通过代理对象去实现aop的时候,获取的ProxyFactoryBean是什么类型?
答: 返回的是一个代理对象,如果目标对象实现了接口,则spring使用jdk 动态代理技术,如果目标对象没有实现接口,则spring使用CGLIB技术.
详见:http://blog.csdn.net/scythe666/article/details/51727234
3、spring事务管理
事务指的是逻辑上的一组操作,这组操作要么全部成功,要么全部失败。
一般的事务指的都是数据库事务,但是广义事务的定义不局限于数据库事务。
事务有4大特性,即 ACID。
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。一个支持事务(Transaction)的数据库,必需要具有这四种特性,否则在事务过程(Transaction processing)当中无法保证数据的正确性,交易过程极可能达不到交易方的要求。
1、原子性
事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
2、一致性
事务前后数据的完整性必须保证一致
比如还是刚刚A给B转账的例子,那么A给B转账结束后,总金额不变。
3、隔离性
多个用户并发访问数据库时,一个用户的事务不能被其他用户的事务所干扰,多个并发事务之间数据要互相隔离。
隔离性非常重要,如果不考虑隔离性,就可能发生:脏读、不可重复读、幻读的问题
(1)脏读
一个事务读取了另一个事务改写但还未提交的数据,如果这些数据被回滚,则读到的数据无效。

(2)不可重复读
在同一事务中,多次读取同一数据返回的结果不同。

(3)幻读
一个事务读取了几行记录后,另一个事务插入一些记录。后来的查询中,第一个事务就会发现有些原来没有的记录。

当然,这些问题是有办法避免的,有隔离级别来限制,后面做解释。
4、持久性
一个事务一旦提交,它对数据库中的数据的改变就是永久性的,即使数据库发生故障也不应该对其有任何影响
事务的隔离级别(4种)
事务的隔离级别是为了防止脏读、不可重复读、幻读问题的发生,具体分成四种,如下:
Spring有一个default隔离级别,底层数据库用的哪个隔离级别,spring就用什么隔离级别
MySQL用的是repeatable_read
Oracle用的是read_committed
有一个更加直观的表格如下:
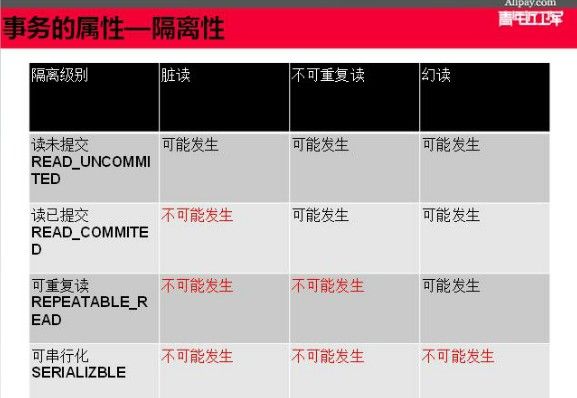
spring中的事务隔离级别配置如下:
4.3.1 模板事务跟标注事务的区别及运理原理
(1)编程式事务

applicationContext.xml
<?xml version="1.0" encoding="utf-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
<!-- 引入 外部属性文件-->
<context:property-placeholder location="classpath:jdbc.properties"/>
<!-- 配置c3p0连接池 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClass}" />
<property name="jdbcUrl" value="${jdbc.url}" />
<property name="user" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>
<!-- 配置业务层类 -->
<bean id="accountService" class="com.wanghubill.AccountServiceImpl">
<property name="accoutDao" ref="accountDao" />
<!-- 注入事务管理的模板 -->
<property name="transactionTemplate" ref="transactionTemplate" />
</bean>
<!-- 配置DAO类 -->
<bean id="accountDao" class="com.wanghubill.AccoutDaoImpl">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 配置事务管理类 -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 配置事务管理的模板:spring为了简化事务管理的代码而提供的类 -->
<bean id="transactionTemplate" class="org.springframework.transaction.support.TransactionTemplate" >
<property name="transactionManager" ref="transactionManager" />
</bean>
</beans>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
AccountService.java
package com.wanghubill;
/** * @author hupo.wh * */
public interface AccountService {
/** * * @param out * @param in * @param money */
public void transfer(String out, String in, Double money);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
AccountServiceImpl.java
package com.wanghubill;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.TransactionCallback;
import org.springframework.transaction.support.TransactionCallbackWithoutResult;
import org.springframework.transaction.support.TransactionTemplate;
/** * @author hupo.wh * */
public class AccountServiceImpl implements AccountService {
private AccountDao accoutDao;
public void setTransactionTemplate(TransactionTemplate transactionTemplate) {
this.transactionTemplate = transactionTemplate;
}
//注入事务管理的模板
private TransactionTemplate transactionTemplate;
public void setAccoutDao(AccountDao accoutDao) {
this.accoutDao = accoutDao;
}
public void transfer(final String out, final String in, final Double money) {
System.out.println("enter transfer()");
// accoutDao.outMoney(out, money);
// //int i=1/0;
// accoutDao.inMoney(in, money);
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus transactionStatus) {
accoutDao.outMoney(out, money);
int i=1/0;
accoutDao.inMoney(in, money);
}
});
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
AccountDao.java
package com.wanghubill;
/** * @author hupo.wh * */
public interface AccountDao {
void outMoney(String out, Double money);
void inMoney(String in, Double money);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
AccoutDaoImpl.java
package com.wanghubill;
import org.springframework.jdbc.core.support.JdbcDaoSupport;
public class AccoutDaoImpl extends JdbcDaoSupport implements AccountDao {
public void outMoney(String out, Double money) {
String sql = "update account set money = money - ? where name = ?";
this.getJdbcTemplate().update(sql,money,out);
}
public void inMoney(String in, Double money) {
String sql = "update account set money = money + ? where name = ?";
this.getJdbcTemplate().update(sql,money,in);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(2)声明式事务1:基于TransactionProxyFactoryBean的方式
因为声明式事务管理都是非侵入性的(不用修改原代码),只用配置,所以就不帖源代码了
<?xml version="1.0" encoding="utf-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
<!-- 引入 外部属性文件-->
<context:property-placeholder location="classpath:jdbc.properties"/>
<!-- 配置c3p0连接池 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClass}" />
<property name="jdbcUrl" value="${jdbc.url}" />
<property name="user" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>
<!-- 配置业务层类 -->
<bean id="accountService" class="com.wanghubill.xml1tfb.AccountServiceImpl">
<property name="accountDao" ref="accountDao" />
</bean>
<!-- 配置DAO类 -->
<bean id="accountDao" class="com.wanghubill.xml1tfb.AccoutDaoImpl">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 配置事务管理类 -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 配置业务层代理 -->
<bean id="accountServiceProxy" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean" >
<!-- 配置目标对象(增强对象) -->
<property name="target" ref="accountService" />
<!-- 注入事务管理器 -->
<property name="transactionManager" ref="transactionManager" />
<!-- 注入事务属性 -->
<property name="transactionAttributes" >
<props>
<prop key="transfer">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
</beans>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
(3)声明式事务2:基于AspectJ的XML方式
<?xml version="1.0" encoding="utf-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
<!-- 引入 外部属性文件-->
<context:property-placeholder location="classpath:jdbc.properties"/>
<!-- 配置c3p0连接池 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClass}" />
<property name="jdbcUrl" value="${jdbc.url}" />
<property name="user" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>
<!-- 配置业务层类 -->
<bean id="accountService" class="com.wanghubill.xml2aspectj.AccountServiceImpl">
<property name="accountDao" ref="accountDao" />
</bean>
<!-- 配置DAO类 -->
<bean id="accountDao" class="com.wanghubill.xml2aspectj.AccoutDaoImpl">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 配置事务管理类 -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 配置事务的通知(事务的增强) -->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<!-- 哪些方法需要执行事务,怎么执行 -->
<tx:attributes>
<tx:method name="transfer" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- 配置切面 -->
<aop:config>
<!-- 配置切入点 -->
<!-- execution(* com.wanghubill.xml2aspectjaspectj.AccountService+.*(..)) -->
<!-- execution(任意返回值 代理类+子类.*任意方法(..任意参数)) -->
<aop:pointcut id="pointcut1" expression="execution(* com.wanghubill.xml2aspectj.AccountService+.*(..))" />
<!-- 配置切面 -->
<!-- 对pointcut1配置txAdvice增强 -->
<aop:advisor advice-ref="txAdvice" pointcut-ref="pointcut1" />
</aop:config>
</beans>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
(4)声明式事务3:基于注解的方式
基于注解的方式,配置十分简单,只需在业务层需要事务的类上面打上注解
/////AccountServiceImpl.java
package com.wanghubill.xml3notation;
import org.springframework.transaction.annotation.Transactional;
/** * @author hupo.wh * */
@Transactional
public class AccountServiceImpl implements AccountService {
private AccountDao accountDao;
public void setAccountDao(AccountDao accountDao) {
this.accountDao = accountDao;
}
public void transfer(final String out, final String in, final Double money) {
System.out.println("enter transfer()");
accountDao.outMoney(out, money);
//int i=1/0;
accountDao.inMoney(in, money);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
<?xml version="1.0" encoding="utf-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
<!-- 引入 外部属性文件-->
<context:property-placeholder location="classpath:jdbc.properties"/>
<!-- 配置c3p0连接池 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="${jdbc.driverClass}" />
<property name="jdbcUrl" value="${jdbc.url}" />
<property name="user" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>
<!-- 配置业务层类 -->
<bean id="accountService" class="com.wanghubill.xml3notation.AccountServiceImpl">
<property name="accountDao" ref="accountDao" />
</bean>
<!-- 配置DAO类 -->
<bean id="accountDao" class="com.wanghubill.xml3notation.AccoutDaoImpl">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 配置事务管理类 -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- 开启注解事务 -->
<tx:annotation-driven transaction-manager="transactionManager" />
</beans>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
小结
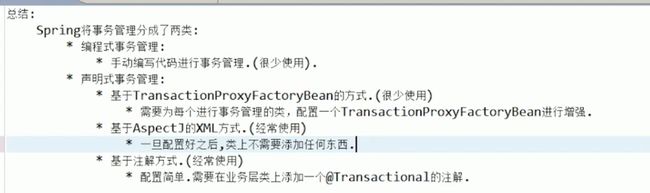
注解和声明对比:
注解简单
声明是非侵入式
感悟:但是本质都是告诉框架,哪些类需要被代理来执行事务。
4.3.2 什么是事务的传播机制
首先要清楚的是:事务是因为有业务需求,才产生的一种机制。
所以事务的配置应该安放在业务层
比如转钱的例子:
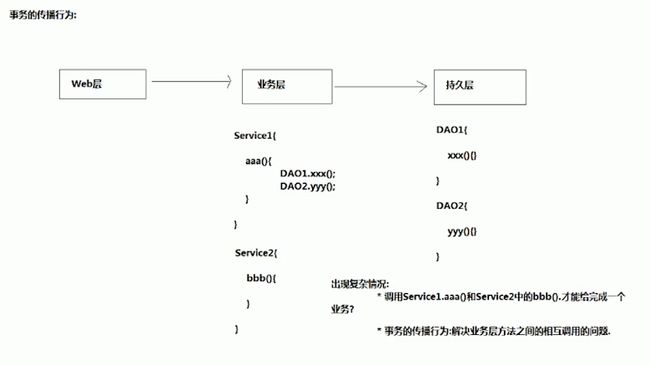
如果aaa()和 bbb()方法需要用事务来解决,应该如何处理他们之间的关系呢?
这就需要用事务的传播行为来定义了
事务的传播行为详见下表:
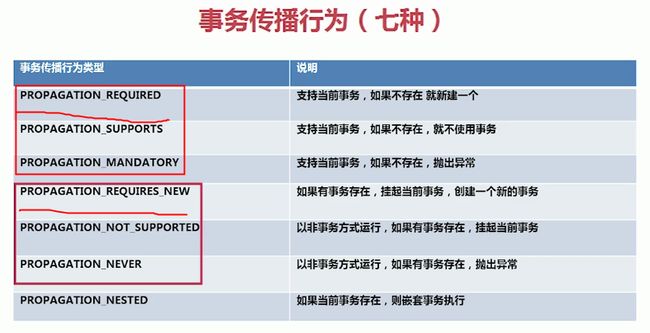
其实这7种行为看起来很多,但是实则可以就分为3类:
(1)第一类 required:在当前事务中解决问题
(2)第二类 requires_new:挂起当前事务,简单来说就是隔离
思考:
为什么取流水号和打印日志需要用requires_new?
这主要有两个原因:
① 为了取号速度,取号是事务的第一步,因为如果不新建一个事务,取号需要加锁,如果这个事务比较长,就需要一直占着锁,这样就很慢。
② 既然是隔离,就是说取号和真正的事务处理不发生影响。这个原因也造成了一个结果,流水号有“作废”机制,也就是说万一发生异常,这个流水号也生成了,后面的会跳号。事务间就没有依赖关系了,会产生四种情况
(3)第三类 nested:嵌套事务
也就是说:
Required 操作在同一个事务里面
New aaa() 和 bbb() 不在一个事务中

spring的事务传播配置如下:

详见:http://blog.csdn.net/scythe666/article/details/51790655
spring的事务真正处理事务的是事务管理器。
五、数据库
1、锁机制
5.1.1 锁的作用是什么
数据库是一个多用户的共享资源。当多个用户并发的存取数据时,在数据库中就会产生多个事务同时存取同一数据的情况。若对并发操作不加控制就可能会读取和存储不正确的数据,破坏数据库一致性。
加锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更新操作。
基本锁类型包括行级锁和表级锁。
表级:直接锁定整张表,在你锁定期间,其它进程无法对该表进行写操作。如果你是写锁,则其它进程则读也不允许
行级:仅对指定的记录进行加锁,这样其它进程还是可以对同一个表中的其它记录进行操作。
页级:表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
5.1.2 什么是乐观锁,什么是悲观锁,怎么实现
乐观锁
相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。如一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进行修改时(如更改用户帐户余额),如果采用悲观锁机制,也就意味着整个操作过程中(从操作员读出数据、开始修改直至提交修改结果的全过程,甚至还包括操作 员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对几百上千个并发,这样的情况将导致怎样的后果。乐观锁机制在一定程度上解决了这个问题。乐观锁大多是基于数据版本 (Version)记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个“version”字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
悲观锁
正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定 状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。比如在使用select字句的时候加上for update,那么直到字句的事务结束为止,任何应用都无修改select出来的记录。
5.1.3 关于信号量 Semaphore
http://iaspecwang.iteye.com/blog/1931031
补充:信号量初始化为1(binary semaphore),而不用lock
jdk文档有如下一段话:
A semaphore initialized to one, and which is used such that it only has at most one permit available, can serve as a mutual exclusion lock. This is more commonly known as a binary semaphore, because it only has two states: one permit available, or zero permits available. When used in this way, the binary semaphore has the property (unlike many Lock implementations), that the “lock” can be released by a thread other than the owner (as semaphores have no notion of ownership). This can be useful in some specialized contexts, such as deadlock recovery.
将信号量初始化为1,使得它在使用时最多只有一个可用的许可,从而可用作一个相互排斥的锁。这通常也称为二进制信号量,因为它只能有两种状态:一个可用的许可,或零个可用的许可。按此方式使用时,二进制信号量具有某种属性(与很多 Lock 实现不同),即可以由线程释放“锁”,而不是由所有者(因为信号量没有所有权的概念)。在某些专门的上下文(如死锁恢复)中这会很有用。
2、索引
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。
聚集索引: InnoDB使用B+Tree作为索引结构,主索引的叶节点包含了完整的数据记录。这种索引叫做聚集索引。InnoDB的辅助索引data域存储相应记录主键的值。换句话说,InnoDB的所有辅助索引都引用主键作为data域。
非聚集索引: MyISAM也采用B+Tree作为索引结构,但其data域保存数据记录的地址,因此,MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
5.2.1 联合索引
联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c)。 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。两个或更多个列上的索引被称作复合索引。
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引 不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知 道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
参考:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
5.2.2 sql执行计划
一个SQL语句表示你所想要得到的但是并没有告诉Server如何去做。 例如, 利用一个SQL语句, 你可能要Server取出所有住在Prague的客户。 当Server收到的这条SQL的时候, 第一件事情并不是解析它。 如果这条SQL没有语法错误, Server才会继续工作。 Server会决定最好的计算方式。 Server会选择, 是读整个客户表好呢, 还是利用索引会比较快些。 Server会比较所有可能方法所耗费的资源。 最终SQL语句被物理性执行的方法被称做执行计划或者是查询计划。
一个执行计划右若干基本操作组成。 例如, 遍历整张表, 利用索引, 执行一个嵌套循环或Hash连接等等。 我们将在这一系列的文章里详细讨论。 所有的基本操作都有一个输出: 结果集。 有些, 象嵌套循环, 有一个输入。 其他的, 象Hash连接, 有两个输入。 每个输入应与其它基本操作的的输出想连接。 这也就是为什么一个执行可以被看做是一个数的原因: 信息从树叶流向树根。 在文章的下面部分有很多诸如此类的例子。
负责处理或计算最优的执行计划的DB Server组件叫优化器。 优化器是建立在其所在的DB资源的基础上而进行工作的。
说白了就是数据库服务器在执行sql语句之前会制定几套执行计划,看那个机会消耗的系统资源少,就是用那套计划。
—END—
参考资料
[1] 《深入理解Java虚拟机》周志明 著. 机械工业出版社
[2] 文中提到的博客和链接
转载出处
http://blog.csdn.net/scythe666/article/details/51841161