整理系列-20161111-Spark学习周记_2
刚才那篇有bug呀,一按删除键/回车键就闪退。我可以上报CSDN技术组吗?估计是遇到EOF了(我猜)。
2016.02.07
- Eclipse在Linux中的使用:
前后台切换:
(1) Eclipse &
(2) 已经在前台执行的程序,可以先ctrl+z,再bg %num(作业编号)
(3)Jobs 可以知道后台运行的程序,将后台job切换到前台fg %1(即回到前台) - 安装插件:
hadoop2x-eclipse-plugin.zip\release复制到$(eclipse_home)\plugin - 使用ant插件:
<project name=”hadoopdemo2” basedir=”.” default=”package”>
<target name=”prepare”>
<delete dir=”${basedir}/build/classes”/>
<mkdir dir=”${basedir}/build/classes”/>
</target>
<path id=”path1”>
<fileset dir=”${basedir}/lib”>
<include name=”*.jar”/>
</fileset>
</path>
<target name=”compile” depends=”prepare”>
<javac includeantruntime=”true” srcdir=”${basedir}/src” destdir=”${basedir}/build/classes” classpathref=”path1”/>
</target>
<target name=”package” depends=”compile”>
<jar destfile=”${base}/lib/My,jar” basedir=”${basedir}/build/classes”/>
</target>
</project>//validate out dir existsConfiguration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path(“/hadoop/it/out”);
if(fs.exists(path)){
fs.delete(path, true);
}
path = new Path(“/tmp”);
if(fs.exists(path)){
fs.delete(path, true);
}2016.02.15
项目中遇到的问题
U盘挂载
fdisk -l # 查看U盘目录
sudo mount -t # vfat /dev/sdb1 /mnt/usb 挂载目录
umount /dev/sdb1 # 卸载Hadoop & Spark安装过程
- 官网下载
- **mv**至 ~/Downloads
- 在/usr/soft下**tar -zxvf**
- /etc/environment 添加**JAVA_HOME** **/ HADOOP_INSTALL /** **SPARK_HOME** / **PATH**
- **cd /etc**; **source environment**或者**sudo reboot**
- **spark-shell --master local[4]**
Spark无法启动
- 问题:

- 原因分析:
JAVA内存泄露
- 解决方案:
将虚拟机内存调大至2G,再重试
- 最终效果:

完美解决!
各种不同的模式实践:
A)重要的四个文件:(重要的事情说两遍!!)
(1) Core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost</value>
</property>
</configuration>(2) Hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>(3) Mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(4) Yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce-shuffle</value>
</property>
</configuration>B)安装ssh
sudo apt-get install ssh
sudo apt-get search sshC)生成非对称加密
ssh-keygen -t rsa -P ‘’ -f ~/.ssh/id_rsaD)生成授权文件
cat id_rsa.pub >> authorized_keysE)登录localhost
ssh localhost于是终于把之前计算机系统结构上讲的那些ssh内容又复习了一遍,and终于看懂了每个option的实际含义,感动!
F)格式化hdfs文件系统
Hadoop namenode -format然后!!出现了神级报错!!

检查path发现了致命伤!
HADOOP_INSTAL**L下的**bin和sbin都要添加到path中去。


完美!
然而namenode挂了!
namenode:
resource manager:
关闭时的报错:
在独立模式转换为伪分布模式的过程中忘记格式化了!!打脸了!!
「整理感想:好了,这段我也不知道发生了什么。。==我记得后面有正常的整理版本。。实在看不明白。」

Happy ending!
感谢:
chillon_m.hadoop伪分布式安装.2016.02.15
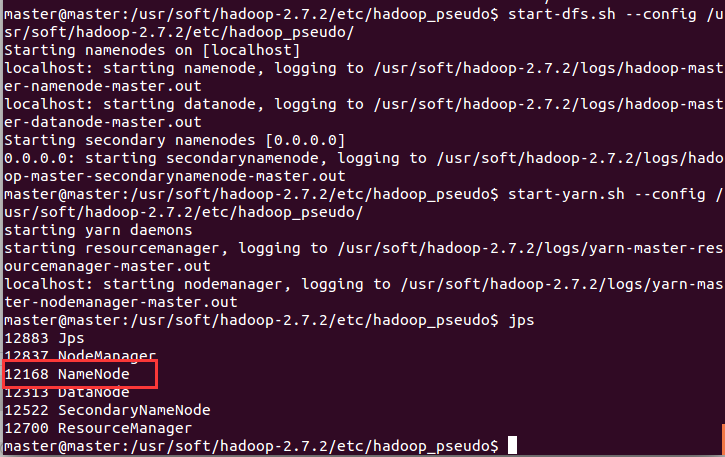
G)利用hadoop_pseudo中的配置文件启动:
start-dfs.sh --config $HADOOP_INSTALL/etc/hadoop_pseudo/
start-yarn.sh --config $HADOOP_INSTALL/etc/hadoop_pseudo/H)查看效果:
jps- Namenode:http://localhost:50070
- Resource manager:http://localhost:8088
I)查看文件:
出错了!这是本地的文件系统?
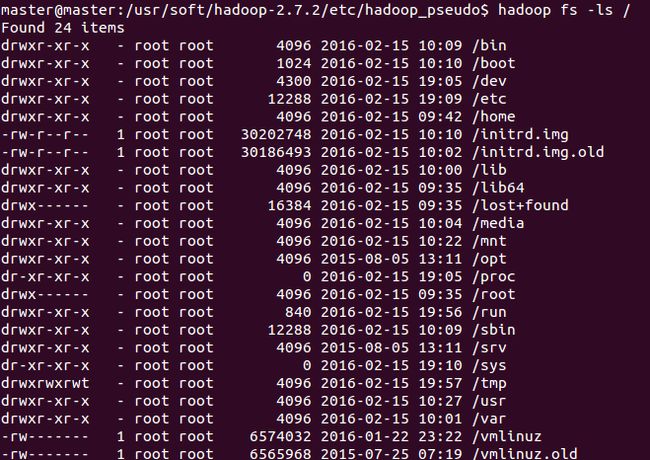
这样才对!所以,
export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop_pseudo\
之后的文件操作就和Linux下的相同了!
Hadoop fs -ls /
Hadoop fs -mkdir usr