HDFS符号链接和硬链接
前言
初看这个标题,可能很多人会心生疑问:符号链接和硬链接是什么意思?这些概念不是在Linux操作系统下才有的嘛,HDFS目前也有?当然大家可能还会有其他疑问,没关系,在后面的内容讲述中答案会一一揭晓。归纳起来一句话:不管是符号链接还是硬链接,它们本质上都是一种快捷的链接方式。熟悉Linux系统的同学应该都知道在Linux文件系统下有硬链接和软链接的概念,而HDFS同样作为一套文件系统,它也能支持文件链接的形式。本文所讲述的主题正是HDFS下的文件链接操作。
相关背景:Linux软链接和硬链接
在讲述HDFS下的文件链接内容之前,有必要了解一下相关内容:Linux软链接和硬链接。因为HDFS文件链接的原理设计基本与此相似。Linux软链接和硬链接分别代表着2种截然不同的连接形式,它们在作用上也存在部分微妙的差异。
软链接
软链接又被称为符号链接,英文名称soft link或symbolic link(HDFS内采用的软链接名称就是symbolic link,简称symlink)。就个人感觉而言,软链接在实际工作中用得频率会略高于硬链接。一句话简单地概括软链接的作用:
软链接其实就是文件的一个快捷方式,软链接删除了,其指向的真实文件并不会受到影响。
所以在实际的工作中,我们一般会把依赖资源包的路径用软链接的方式引用,这样的话资源包的路径可以一直保持不变,而其所指向的真实资源包可以根据使用场景进行任意变化。
硬链接
硬链接,英文名称为hard link。它的一个主要目的在于文件的共享。文件的硬链接创建出来之后,它具有如下的特点:
硬链接相当于文件的一个别名。它指向的是一个文件inode的引用地址,而非软链接中的文件路径指向。所以对于硬链接中的文件做修改会影响到其所指向的真实文件,当对硬链接做删除动作后,如果其所指向的文件inode当前没有被外部引用的话,则原文件会被删除,否则原文件不会被删除。
上面的意思通俗地解释就是说,当真实文件或此文件的硬链接有一个存在的情况下,对文件执行删除操作,文件不会被真正删除。当只剩下一个文件inode引用的情况下,删除操作才能生效。
HDFS符号链接(软链接)与硬链接概述
了解完Linux下的软链接与硬链接的概念后,我们将进入本文的主题:HDFS下的符号链接与硬链接。
Hadoop社区在HDFS-245(Create symbolic links in HDFS)中优先对符号链接功能进行了实现。符号链接另外一部分的工作在HADOOP-6421(Symbolic links)中,此部分是HADOOP-COMMON模块相关的底层代码改动。在硬链接方面,社区目前有相关的JIRA:HDFS-3370(HDFS hardlink),但是社区目前并没有在跟进,只有初始的设计文档。所以本文准备讲述的HDFS硬链接将会是一个设计模型,并未真正实现,这点需要注意。
鉴于目前HDFS的硬链接功能并未真正实现,所以本文的主讲内容还是符号链接的功能,硬链接功能将给出大致设计模型。
HDFS符号链接(软链接)
HDFS符号链接,在HDFS中称之为symbolic link,在下文的讲述中此名称都将会简称为symlink。与Linux文件系统中的软链接概念一样,HDFS符号链接也是相当于给目标文件新建一个自定义路径,这个自定义路径实质指向目标文件。所以在这里HDFS符号链接中做的最重要的事情就是路径的解析。而且这个解析还有可能是嵌套的,符号链接中指向的是另外一个符号链接。下面来学习HDFS符号链接的主要原理实现。
HDFS符号链接原理
HDFS符号链接功能的实现主要分为2个部分:一个是对现有文件符号链接的添加,另外一个则是符号链接的解析过程。
对现有文件符号链接的添加在HDFS中的实现就是添加一个新的INode对象在NameNode中,只是这个INode对象是Symlink类型的,叫做INodeSymlink。此对象内部会包含一个实际指向的target地址。
而符号链接的解析过程则会略微复杂一些,HDFS并不是直接在NameNode最终处理方法的地方做解析的,而是在前面一层FileContext类上做解析的,然后将解析好后的路径再传到HDFS中做处理。换句话说,客户端需要通过FileContext上下文对象来操作符号链接相关的操作,如果直接用FileSystem的API来操作的话,会抛出解析异常的错误。
HDFS符号链接核心代码实现
此部分我们将通过部分代码的跟踪来学习HDFS符号链接的实现过程。
同样首先是创建符号链接的过程,我们直接进入到最终的服务端处理方法,FSNamesystem的createSymlink方法。
*// 为目标文件创建一个符号链接
void createSymlink(String target, String link,
PermissionStatus dirPerms, boolean createParent, boolean logRetryCache)
throws IOException {
if (!FileSystem.areSymlinksEnabled()) {
throw new UnsupportedOperationException("Symlinks not supported");
}
HdfsFileStatus auditStat = null;
writeLock();
try {
checkOperation(OperationCategory.WRITE);
checkNameNodeSafeMode("Cannot create symlink " + link);
// 此处进入创建软链接实际操作
auditStat = FSDirSymlinkOp.createSymlinkInt(this, target, link, dirPerms,
createParent, logRetryCache);
...我们继续进入FSDirSymlinkOp的createSymlinkInt方法,
static HdfsFileStatus createSymlinkInt(
FSNamesystem fsn, String target, final String linkArg,
PermissionStatus dirPerms, boolean createParent, boolean logRetryCache)
throws IOException {
FSDirectory fsd = fsn.getFSDirectory();
String link = linkArg;
// 检验符号链接的名称
if (!DFSUtil.isValidName(link)) {
throw new InvalidPathException("Invalid link name: " + link);
}
if (FSDirectory.isReservedName(target) || target.isEmpty()
|| FSDirectory.isExactReservedName(target)) {
throw new InvalidPathException("Invalid target name: " + target);
}
if (NameNode.stateChangeLog.isDebugEnabled()) {
NameNode.stateChangeLog.debug("DIR* NameSystem.createSymlink: target="
+ target + " link=" + link);
}
FSPermissionChecker pc = fsn.getPermissionChecker();
INodesInPath iip;
fsd.writeLock();
try {
// 解析得到符号链接的路径对象
iip = fsd.resolvePathForWrite(pc, link, false);
link = iip.getPath();
...
// 将此符号链接对象加入到NameNode元数据中
addSymlink(fsd, link, iip, target, dirPerms, createParent, logRetryCache);
...我们继续进入addSymlink方法,
private static INodeSymlink addSymlink(FSDirectory fsd, String path,
INodesInPath iip, String target, PermissionStatus dirPerms,
boolean createParent, boolean logRetryCache) throws IOException {
final long mtime = now();
final INodesInPath parent;
// 获取目标符号链接的父亲对象
if (createParent) {
// 如果需要创建父亲对象,则进行创建父目录操作方法
parent = FSDirMkdirOp.createAncestorDirectories(fsd, iip, dirPerms);
if (parent == null) {
return null;
}
} else {
parent = iip.getParentINodesInPath();
}
final String userName = dirPerms.getUserName();
long id = fsd.allocateNewInodeId();
PermissionStatus perm = new PermissionStatus(
userName, null, FsPermission.getDefault());
// 加入符号链接类型的INode对象到父对象中
INodeSymlink newNode = unprotectedAddSymlink(fsd, parent,
iip.getLastLocalName(), id, target, mtime, mtime, perm);
...最后调用到加入NameNode命名空间方法,
static INodeSymlink unprotectedAddSymlink(FSDirectory fsd, INodesInPath iip,
byte[] localName, long id, String target, long mtime, long atime,
PermissionStatus perm)
throws UnresolvedLinkException, QuotaExceededException {
assert fsd.hasWriteLock();
// 新建符号链接类型的INode对象
final INodeSymlink symlink = new INodeSymlink(id, null, perm, mtime, atime,
target);
symlink.setLocalName(localName);
// 将符号链接对象加入到最终路径对应的上一级父目录下
return fsd.addINode(iip, symlink, perm.getPermission()) != null ?
symlink : null;
}至此,添加软链接操作正式完毕,与普通HDFS文件INode对象的添加过程类似。
接下来我们来看另外一个部分的内容:HDFS符号链接的路径解析过程。这个过程是本文的一个重点。在没有学习HDFS符号链接源代码之前,本人一直以为HDFS把符号链接的解析过程放在了NameNode的处理方法中,但最终结果表明,事实并不是这样的。
假设我们直接以HDFS文件的符号链接进行读写操作,究竟会发生什么事情呢?这里我们以setReplication设置副本数操作为例。
首先通过DFSClient端执行setReplication方法,
*// 为指定的文件进行副本数的设置,假设我们这里传入的src路径是一个符号链接,而非真实文件地址
public boolean setReplication(String src, short replication)
throws IOException {
checkOpen();
try (TraceScope ignored = newPathTraceScope("setReplication", src)) {
// 向服务端发起设置副本数操作请求
return namenode.setReplication(src, replication);
} catch (RemoteException re) {
...
}
}我们直接进入FSNamesystem的相应处理方法,
boolean setReplication(final String src, final short replication)
throws IOException {
boolean success = false;
checkOperation(OperationCategory.WRITE);
writeLock();
try {
checkOperation(OperationCategory.WRITE);
checkNameNodeSafeMode("Cannot set replication for " + src);
// 调用真正设置副本数方法
success = FSDirAttrOp.setReplication(dir, blockManager, src, replication);
} catch (AccessControlException e) {
logAuditEvent(false, "setReplication", src);
throw e;
} finally {
writeUnlock();
}
...
return success;
}这里进入FSDirAttrOp的setReplication方法,
static boolean setReplication(
FSDirectory fsd, BlockManager bm, String src, final short replication)
throws IOException {
bm.verifyReplication(src, replication, null);
final boolean isFile;
FSPermissionChecker pc = fsd.getPermissionChecker();
fsd.writeLock();
try {
// 解析此路径得到INode路径对象
final INodesInPath iip = fsd.resolvePathForWrite(pc, src);
if (fsd.isPermissionEnabled()) {
fsd.checkPathAccess(pc, iip, FsAction.WRITE);
}
// 对此路径进行副本的设置
final BlockInfo[] blocks = unprotectedSetReplication(fsd, iip,
replication);
...至少从目前来看,我们还没看到解析符号链接的操作,我们继续进入设置副本的进一步操作:unprotectedSetReplication方法。
static BlockInfo[] unprotectedSetReplication(
FSDirectory fsd, INodesInPath iip, short replication)
throws QuotaExceededException, UnresolvedLinkException,
SnapshotAccessControlException, UnsupportedActionException {
assert fsd.hasWriteLock();
final BlockManager bm = fsd.getBlockManager();
// 获取路径对象的最后一个节点,也就是最终需要设置副本的文件INode对象
final INode inode = iip.getLastINode();
if (inode == null || !inode.isFile() || inode.asFile().isStriped()) {
// TODO we do not support replication on stripe layout files yet
return null;
}
// 得到此INodeFile对象
INodeFile file = inode.asFile();
// Make sure the directory has sufficient quotas
short oldBR = file.getPreferredBlockReplication();
long size = file.computeFileSize(true, true);
// Ensure the quota does not exceed
if (oldBR < replication) {
fsd.updateCount(iip, 0L, size, oldBR, replication, true);
}
// 对象文件对象进行副本数的设置
file.setFileReplication(replication, iip.getLatestSnapshotId());
short targetReplication = (short) Math.max(
replication, file.getPreferredBlockReplication());
...
return file.getBlocks();
}在此方法中,HDFS直接从路径对象中取出文件INode对象,然后对其进行副本数的设置,从中并没有对符号链接进行解析的操作。我们重新把目光回到之前FSDirAttrOp的setReplication方法,在此方法中的fsd.resolvePathForWrite操作是否会有这样的解析动作呢,从方法名上看也确实包含了解析的单词。这里进入FSDirectory的resolvePathForWrite方法,
INodesInPath resolvePathForWrite(FSPermissionChecker pc, String src)
throws UnresolvedLinkException, FileNotFoundException,
AccessControlException {
// 此处调用同名方法,这里的第三个布尔参数代表解析到符号链接的INode对象时是否抛出异常
return resolvePathForWrite(pc, src, true);
}此方法中间会调用层层方法,最终调用INodesInPath类内部的resolve方法。此方法执行过程如下,
static INodesInPath resolve(final INodeDirectory startingDir,
final byte[][] components, final boolean isRaw,
final boolean resolveLink) throws UnresolvedLinkException {
Preconditions.checkArgument(startingDir.compareTo(components[0]) == 0);
INode curNode = startingDir;
int count = 0;
int inodeNum = 0;
INode[] inodes = new INode[components.length];
boolean isSnapshot = false;
int snapshotId = CURRENT_STATE_ID;
while (count < components.length && curNode != null) {
final boolean lastComp = (count == components.length - 1);
inodes[inodeNum++] = curNode;
final boolean isRef = curNode.isReference();
final boolean isDir = curNode.isDirectory();
final INodeDirectory dir = isDir? curNode.asDirectory(): null;
if (!isRef && isDir && dir.isWithSnapshot()) {
...
} else if (isRef && isDir && !lastComp) {
...
}
// 如果当前INode是符号链接类型并且当前需要抛出符号链接异常或当前不是最后一个INode对象时,
// 都抛出异常
if (curNode.isSymlink() && (!lastComp || resolveLink)) {
final String path = constructPath(components, 0, components.length);
final String preceding = constructPath(components, 0, count);
final String remainder =
constructPath(components, count + 1, components.length);
// 获取符号链接地址
final String link = DFSUtil.bytes2String(components[count]);
// 获取符号链接真实指向地址
final String target = curNode.asSymlink().getSymlinkString();
if (LOG.isDebugEnabled()) {
LOG.debug("UnresolvedPathException " +
" path: " + path + " preceding: " + preceding +
" count: " + count + " link: " + link + " target: " + target +
" remainder: " + remainder);
}
// 抛出无法解析异常
throw new UnresolvedPathException(path, preceding, remainder, target);
}
...
return new INodesInPath(inodes, components, isRaw, isSnapshot, snapshotId);
}从上面的操作方法中,我们可以得出两个结论:
- 第一点,HDFS符号链接的解析逻辑并不是实现在NameNode服务端的处理代码中。
- 第二点,NameNode服务端中解析符号链接的目的在于帮助抛出解析异常信息,以此告诉用户当前处理的路径是一个符号链接地址。
那么这部分的解析逻辑到底发生在了什么地方呢?这个答案我们可以从符号链接的单元测试实例中进行寻找,范例代码如下(同样以设置副本数操作为例):
@Test
/** setReplication affects the target not the link */
public void testSetReplication() throws IOException {
Path file = new Path(testBaseDir1(), "file");
Path link = new Path(testBaseDir1(), "linkToFile");
createAndWriteFile(file);
fc.createSymlink(file, link, false);
// 此处通过fc对象进行设置,fc指的是文件上下文对象
fc.setReplication(link, (short)2);
assertEquals(0, fc.getFileLinkStatus(link).getReplication());
assertEquals(2, fc.getFileStatus(link).getReplication());
assertEquals(2, fc.getFileStatus(file).getReplication());
}上面符号链接的设置副本操作是通过fc对象进行的,fc对象的意思是文件上下文,此对象的初始化操作如下:
@BeforeClass
public static void testSetUp() throws Exception {
Configuration conf = new HdfsConfiguration();
conf.setBoolean(DFSConfigKeys.DFS_PERMISSIONS_ENABLED_KEY, true);
conf.set(FsPermission.UMASK_LABEL, "000");
cluster = new MiniDFSCluster(conf, 1, true, null);
// 测试实例初始化操作中,得到文件上下文对象
fc = FileContext.getFileContext(cluster.getURI());
}至此,这也就是为什么我们不能直接用FileSystem对象进行符号链接相关操作执行的原因。
下面我们来聊聊FileContext到底是如何帮助用户完成符号链接的解析过程的。比如说,现在我已经初始化好了一个FileContext对象,然后调用了setReplication操作,接着会触发到下面的方法,
public boolean setReplication(final Path f, final short replication)
throws AccessControlException, FileNotFoundException,
IOException {
final Path absF = fixRelativePart(f);
// 调用解析器对象进行解析
return new FSLinkResolver<Boolean>() {
@Override
public Boolean next(final AbstractFileSystem fs, final Path p)
throws IOException, UnresolvedLinkException {
// next方法执行时,p已经代表了目标真实文件地址
return fs.setReplication(p, replication);
}
}.resolve(this, absF);
}所以以上的实现关键点在于FSLinkResolver的解析过程。我们进入此类,解析过程如下:
public T resolve(final FileContext fc, final Path path) throws IOException {
int count = 0;
T in = null;
Path p = path;
// 获取初始文件系统
AbstractFileSystem fs = fc.getFSofPath(p);
// 进行循环解析,直到所有的符号链接地址都被解析成功
for (boolean isLink = true; isLink;) {
try {
// 如果当前的路径解析成功,则更新标记为false,跳出循环,代表当前路径已解析成功
in = next(fs, p);
isLink = false;
} catch (UnresolvedLinkException e) {
...
// 否则出现符号链接时,解析当前第一层符号链接地址,fs.getLinkTarget(p)会获取当前符号链接地址所指向的真实地址
p = qualifySymlinkTarget(fs.getUri(), p, fs.getLinkTarget(p));
fs = fc.getFSofPath(p);
// 然后用新的路径和文件系统对象进行下一次的操作执行
}
}
return in;
}fs.getLinkTarget(p)操作方法的实现,大家可以从DistributedFileSystem中查看其具体实现。
所以,HDFS符号链接的总过程调用如下图所示:
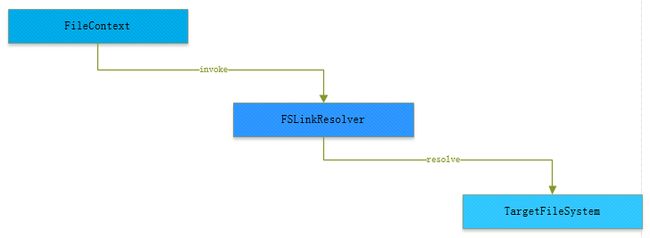
图 1-1 HDFS符号链接解析过程
HDFS硬链接的原型设计
鉴于前面花了大量的篇幅介绍了HDFS符号链接(软链接)的内容,最后简单介绍介绍HDFS硬链接的内容。因为此功能目前在HDFS中并未实现,只有原型设计,所以这里也将只会介绍社区上对于此功能的一个设计。
HDFS硬链接的一个核心使用点在于它可以在无需拷贝真实数据的情况下,实现数据的共享。为了实现这样的功能,在HDFS-3370中的设计文档中,设计者引入了INodeHardLinkFile对象来代表当前的一个硬链接。这些对象共享HardLinkFileInfo对象。在HardLinkFileInfo对象中,会保持有当前的引用计数值,表示当前引用此文件的硬链接数,与Linux操作系统中的硬链接类似。
下面通过图形展示的方式大致介绍一下HDFS硬链接的原型设计:
首先,假设当前存在一个已存在的文件File1,如图1-2。
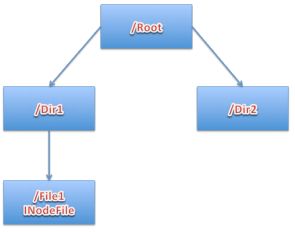
图 1-2 HDFS初始文件
此时对文件File1创建一个硬链接,同时名称也为File1不变,File1的INodeFile对象将会转化为INodeHardLinkFile对象,同时引用计数为1,此过程见图1-3。

图 1-3 HDFS硬链接的创建
在此基础上,如果还要对此文件进行硬链接的创建,即为INodeHardLinkFile的再次创建,但是引用的HarLinkFileInfo还是同一个对象,HarLinkFileInfo引用计数此时递增 2,此过程见图1-4。
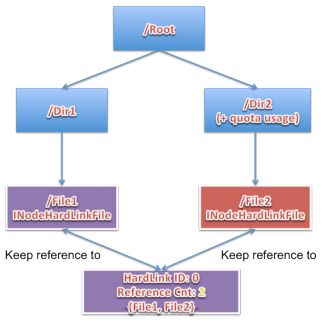
图 1-4 HDFS硬链接的再创建
这个于Linux硬链接中的文件inode引用原理是完全一致的。当个别文件硬链接对象的删除将不会删除其真实的数据,除非硬链接文件当前没有其他的引用对象了。
此设计文档的作者是来自于Facebook的某位工程师,本人估测此功能在Facebook内部已经早已实现,HDFS硬链接更多设计细节,可以阅读参考资料中的链接地址。
参考资料
[1].https://issues.apache.org/jira/browse/HDFS-245
[2].https://issues.apache.org/jira/browse/HDFS-3370
[3].https://issues.apache.org/jira/browse/HADOOP-6421
[4].https://issues.apache.org/jira/secure/attachment/12526189/HDFS-HardLink.pdf