深入Hadoop HDFS(二)
1. hdfs架构简介
1.1 hdfs架构挑战
1.2 架构简介
1.3 文件系统命名空间File System Namespace
1.4 数据复制
1.5 元数据持久化
1.6 信息交换协议
2. hdfs数据可访问性
2.1 web interface
2.2 shell command
<1>. hdfs架构简介
1.1 hdfs架构挑战
hdfs和大多数现有的分布式文件系统存在很多类似特点,但是又具有自己一些特性:具有很高的容错性highly fault-tolerant,较高的数据吞吐量high throughput等。为了满足上面的特性,hdfs将不得不解决下面的一些棘手问题:
1. 硬件错误:在一个 hdfs系统中可能保存大量的服务器,那么每个服务器均存在硬件故障的可能性,那么hdfs需要保证能够自动检测到某个服务器错误,同时能够自动恢复。这个目标是hdfs架构的首要解决的问题。
2. 流式的数据访问Streaming Data Access:hdfs需要向应用程序提供流式的数据访问。
3. 大文件支持:在hdfs上存储的文件可能是在G级别或者是T级别的,这样hdfs需要能够对大文件支持。同时需要支持在一个实例中存储大量的文件(It should support tens of millions of files in a single instance)。
4. 数据一致性保证:hdfs需要能够支持“write-once-read-many access” 模型。
面对上面的架构需求,我们来看看hdfs是如何满足上面的架构需求的。
1.2 架构简介
hdfs采用的是master/slave模型,一个hdfs cluster包含一个NameNode和一些列的DataNode,其中NameNode充当的是master的角色,主要负责管理hdfs文件系统,接受来自客户端的请求;DataNode主要是用来存储数据文件,hdfs将一个文件分割成一个多这是多个的block,这些block可能存储在一个DataNode上或者是多个DataNode上。
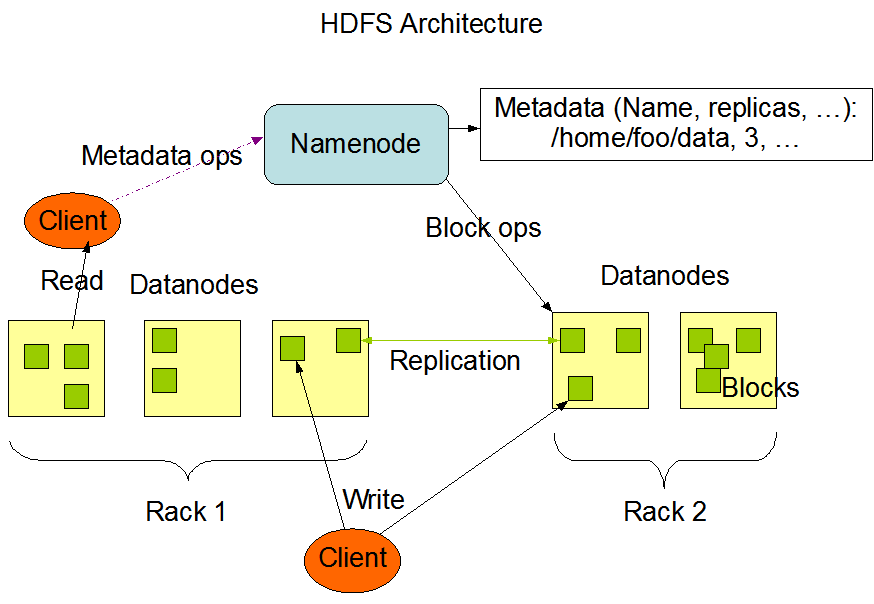
基于上面的架构需求,hadoop采用了这种master/slave的架构,具体来说私有一下的几部分组成:
1. NameNode:基本上等同于Master的地位,复制控制底层文件的io操作,处理mapreduce任务等。
2. DataNode: 在slave机器上运行,负责实际的底层的文件的读写。如果客户端client程序发起了读hdfs上的文件的命令的话,那么首先将这些文件分成所谓的block,然后NameNode将告知client这些block数据是存储在那些DataNode上的,之后,client将直接和DataNode交互。
3. Secondary NameNode:该部分主要是定时对NameNode进行数据snapshots进行备份,这样尽量降低NameNode崩溃之后,导致数据的丢失。
4. JobTracker:该部分相当于在client program和hadoop之间的桥梁,在整个的hadoop系统中仅仅存在一个JobTracker的实例。

5. TaskTracker:TaskTracker主要是负责的是每个具体的任务task,如下:

1.3 文件系统命名空间File System Namespace
hdfs支持传统文件系统的目录结构,应用程序能够创佳目录directory,在这些目录中存储文件,创建文件,移动文件remove file,重命名文件,但是不支持硬链接和软连接。
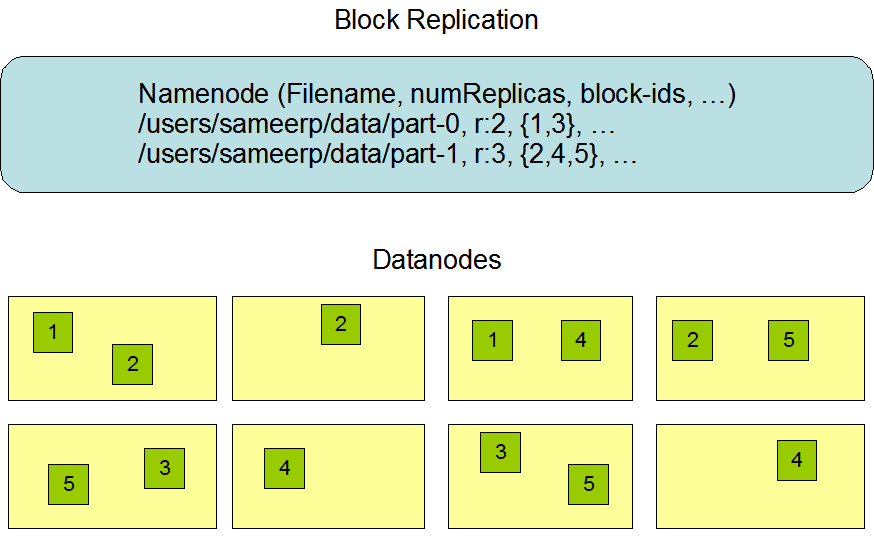
1.4 数据复制Data Replication
hdfs将一个发文件分割成block,然后将这些block存储到不同的DataNode中,那么如何保证如果一个DataNode死掉,保证数据的完整性,通常的技术就是进行数据的备份,hdfs同样使用的是这一策略。
1.5 元数据持久化
hdfs使用日志机制将对文件系统的操作全部存储在一个日志文件中,同时将整个文件系统信息(the mapping of blocks to files and file system properties)映射成一个FsImage文件,该文件存储在NameNode主机的本地文件系统上。同时FsImage和Log支持multiple copies,这些hdfs保证这些备份文件的一致性。
1.6 信息交换协议
上面讲到“DataNode向NameNode发送Heartbeat和Blockreport”,这其中显然涉及到协议的问题,hdfs communication协议是构建在tcp/ip协议上的。客户端通过ClientProtocol协议和NameNode交换信息,NameNode通过DataNode Procotol协议和DataNode交换信息。
<2>. 数据可访问性
2.1 web interface
hdfs可以使用web页面来查看hdfs中文件系统中的目录http://localhost:50075:

2.2 shell command
1. 创建目录
2. 删除目录
3. 上传文件
4. 查看文件
5. 删除文件
//------------------------------------------
最后更新时间:2011-6-1 儿童节啊

作者:许强
1. 本博客中的文章均是个人在学习和项目开发中总结。其中难免存在不足之处 ,欢迎留言指正。 2. 本文版权归作者和博客园共有,转载时,请保留本文链接。