Ubuntu16.04安装Hadoop2.6+Spark1.6+开发实例
Ubuntu16.04安装Hadoop2.6+Spark1.6,并安装python开发工具Jupyter notebook,通过pyspark测试一个实例,調通整个Spark+hadoop伪分布式开发环境。
主要内容:配置root用户,配置Hadoop,Spark环境变量,Hadoop伪分布式安装并测试实例,spark安装并通过Jupter notebook进行开发实例,配置Jupter notebook兼容Python2和python3双内核共存开发。
默认已经正确安装了JDK,并设置了JAVA_HOME(安装JDK教程较多,不再赘述)
1.配置环境变量
1.0 配置SSH
ssh免密匙登录
sudo apt-get install ssh
sudo apt-get install rsync
ssh-keygen -t rsa //一路回车就好
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh localhost //不需要输入密码时即成功1.1.进入root用户
1.1.1 root用户初始为禁止登陆,通过重新设置密码达到root可登陆目的。
sudo passwd //回车输入新的root账户密码两次
su //以root登录 执行设计opt的文件
在本用户(root用户和普通用户)下
ls -a1.1.2.为了使得当前user如wxl(wangxiaolei)用户的变量在root用户中也能生效,需要修改root用户下的.bashrc文件。方法如下。
suvim ~/.bashrc
#增加内容
source /etc/profile重新启动terminal/终端
1.2.配置当前用户中hadoop和spark的环境变量(有的开发人员习惯先创建一个Hadoop新用户来做,其实这个是可有可无的)
vim /etc/profile.d/spark.sh
export SPARK_HOME="/opt/spark"
export PATH="$SPARK_HOME/bin:$PATH"
export PYTHONPATH="$SPARK_HOME/python"vim /etc/profile.d/hadoopsnc.sh (hadoop Single node cluster)
export HADOOP_HOME/opt/hadoop
export CLASSPATH=".:$JAVA_HOME/lib:$CLASSPATH"
export PATH="$JAVA_HOME/:$HADOOP_HOME/bin:$PATH"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native1.3.解决localhost: Error: JAVA_HOME is not set and could not be found.
修改/opt/hadoop/etc/hadoop/hadoop-env.sh
vim /opt/hadoop/etc/hadoop/hadoop-env.sh
#增加
export JAVA_HOME=/opt/java2.安装Hadoop。在单机情景下,可以单例也可以伪分布式安装。本次详细介绍了伪分布式安装。
2.0.Hadoop单机模式
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output 'dfs[a-z.]+'结果如图
cat output/*Tip:再次运行例子时候需要手动删除output文件,否则报错
删除output文件
rm -rf output2.1.伪分布式模式
进入hadoop解压路径中
cd /opt/hadoop2.2.源码修改
vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
2.3.初始化节点
Tip 如果出错,可以删除生成的文件在/tem路径下
rm -rf /tmp/hadoop-wxl注意:因为format在/tmp目录下,所以每次重启机器这些文件会丢失,所以。。。每次开机都需要format一次。
初始化namenode
bin/hdfs namenode -format![]()
2.4.启动hdfs
sbin/start-dfs.sh查看是否正常启动
jps
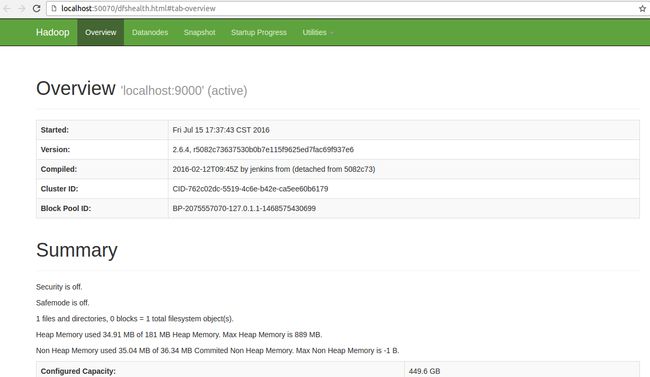
若启动成功,访问web端http://localhost:50070
2.5.YARN 的伪分布式
2.5.1.源码修改
创建一个mapred-site.xml,这里采用源文件备份的mapred-site.xml。
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xmlvim etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>vim etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>2.5.2开启YARN
sbin/start-yarn.sh查看是否全部正常启动命令jps,如图

也可以在web端查看,地址http://localhost:8088/cluster
2.6.运行例子:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output 'dfs[a-z.]+'
bin/hdfs dfs -get output output
bin/hdfs dfs -cat output/*
2.7.关闭YARN/dfs
sbin/stop-dfs.sh
sbin/stop-yarn.sh3.安装spark
3.1.解压,移动到/opt路径下
cd /home/wxl/Downloads
tar -zxf spark-1.6.2-bin-hadoop2.6.tgz
sudo mv spark-1.6.2-bin-hadoop2.6 /opt/spark在/opt/spark/conf的文件,将spark-env.sh.template复制为spark-env.sh
增加
export JAVA_HOME=/opt/java即可。
可以看到spark配置比较简单,只需要解压,放置指定路径皆可。
3.2.通过小例子的shell测试
3.2.1.开启pyspark
./bin/pyspark3.2.2.pyspark在shell中开发
lines =sc.textFile("README.md")
lines.count()
lines.first()
exit() #或者ctrl+c可以看到每次shell打印一堆info信息,为了较少信息输出,建立log机制
cp conf/log4j.properties.template conf/log4j.properties
将log4j.properties文件中的log4j.rootCategory=INFO, console
修改为 log4j.rootCategory=WARN, console

3.3.pyspark在jupyter notebook 中开发
启动Spark 1.6 的开发工具 jupyter notebook
IPYTHON_OPTS="notebook" /opt/spark/bin/pysparkTip:如果是spark 2.0+版本运行以下启动jupyter notebook命令(更新于20160825)
PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS='notebook' /opt/spark-2.0.0-bin-hadoop2.7/bin/pyspark

输入测试例子,shift+enter是运行本单元格并且建立新行,依次输入
lines =sc.textFile("README.md")
lines.count()
lines.first()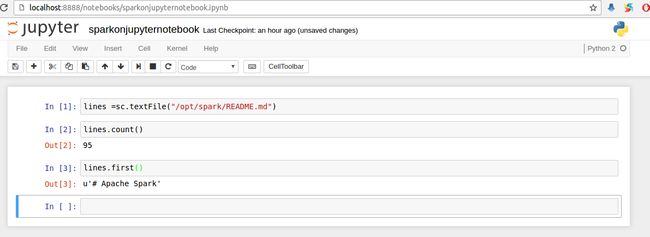
至此,整个环境搭建和开发过程总结完毕,愉快的开发吧!
注意:Spark支持的python版本是python2.7.x,也支持python3.4+。但是在开发程序时候,朋友请保证注意pyhton版本,如果程序和使用内核不同的话,jupyter notebook内核则会报错。