E-COM-NET
首页
在线工具
Layui镜像站
SUI文档
联系我们
推荐频道
Java
PHP
C++
C
C#
Python
Ruby
go语言
Scala
Servlet
Vue
MySQL
NoSQL
Redis
CSS
Oracle
SQL Server
DB2
HBase
Http
HTML5
Spring
Ajax
Jquery
JavaScript
Json
XML
NodeJs
mybatis
Hibernate
算法
设计模式
shell
数据结构
大数据
JS
消息中间件
正则表达式
Tomcat
SQL
Nginx
Shiro
Maven
Linux
scrapy框架学习
scrapy
-redis分布式集群redis配置
#----------------------------------------Redis单机模式-------------------------------------#Redis单机地址REDIS_HOST="172.25.2.25"REDIS_PORT=6379#REDIS单机模式配置参数REDIS_PARAMS={"password":"xxxx","db":0}#----------
沫明
·
2023-10-15 15:12
python爬虫开发数据库设计_基于python开源爬虫框架
scrapy
的租房信息爬取系统毕业论文+任务书+外文翻译及原文+答辩PPT+项目源码及数据库...
本文以此为研究方向,设计并实现了一个基于python开源爬虫框架
scrapy
的租房信息爬取系统,爬取互联网上多个含有
weixin_39945792
·
2023-10-15 10:19
python爬虫开发数据库设计
基于djang、vue、
scrapy
-redis、高德地图的豆瓣租房租房信息爬取、存储、可视化综合项目
1、
scrapy
-redis部分这里主要是用分布式爬虫爬取所有的豆瓣租房信息,然后去重、存数据库(MySQL)。
haeasringnar
·
2023-10-15 10:14
Python
Django
Vue
Redis
Scrapy
vue
django
mysql
python
计算机毕业设计python+
scrapy
下的租房信息爬取与数据展示工具的设计与实现
运行环境环境:python3.6.0Anacondacustom64bit4.3.0Pycharmx64专业版2018.1.2Webstromx64专业版2018.1.3
scrapy
1.3.3MongoDB3.6Django2.0.5SemanticUI2.2.4chrome56.0.2924.87
QQ1039692211
·
2023-10-15 10:41
python
计算机毕业设计
python
django
爬虫
Python实现简易采集爬虫
在Python中,我们可以通过一些库(如Requests、BeautifulSoup、
Scrapy
等)轻松实现一个简易的采集爬虫。本文将从多个方面详细阐述Python实现简易采集爬虫的方法。
很酷的站长
·
2023-10-15 09:58
编程笔记
python
爬虫
开发语言
SpringSecurity安全
框架学习
笔记 - 数据库的验证与授权
SpringSecurity安全
框架学习
笔记-数据库的验证与授权前言笔记环境关系数据库用户表角色表SQL命令组流程实体类Mapper服务类实现类SecurityConfig效果总结结束语前言今日爆肝两章
Marinda_Speed
·
2023-10-15 06:20
Spring
Security
java
SpringBoot
数据库
安全
学习
2019-01-25百度图片spider
import
scrapy
importrefrom..itemsimportBaiduspiderItemclassBaiduSpider(
scrapy
.Spider):name='baidu'#allowed_domains
太阳出来我爬山坡
·
2023-10-15 05:11
Spring
框架学习
- Spring与SpringMVC整合
框架整合web项目中Spring和SpringMVC框架启动在web项目中,都会出现SpringMVC和Spring框架的整合;Web项目中SpringMVC框架的启动是通过前端控制器DispatcherServlet来实现的;而Spring框架的启动则是通过ContextLoaderListener监听器来实现的;Web项目中SpringMVC框架启动:springmvcorg.springfr
做一件事就好
·
2023-10-15 01:29
开发框架专栏
spring
mvc
java
OpenGL ES之GLKit
框架学习
一:GLKit框架概述1:GLKit框架的设计⽬标是为了简化基于OpenGL/OpenGLES的应用开发。它的出现加快OpenGLES或OpenGL应用程序开发。使用数学库,背景纹理加载,预先创建的着⾊器效果,以及标准视图和视图控制器来实现渲染循环。2:GLKit框架提供了功能和类,可以减少创建新的基于着⾊器的应用程序所需的⼯作量,或者⽀持依赖早期版本的OpenGLES或OpenGL提供的固定函数
懿轩加油
·
2023-10-14 18:01
ajax请求模拟referer,用头和请求负载模拟AJAX请求
在classMySpider(
scrapy
.Spider):name='kralilanspider'allowed_domains=['kralilan.com
爱探索发现
·
2023-10-14 18:19
ajax请求模拟referer
scrapy
个人循序渐进
创建项目第一个小demo在Linux环境(虚拟机)下使用Docker配置NoSQL获取请求中的数据不遵守robots协议
scrapy
整合Playwright线程池规则化爬虫数据存储分布式爬虫爬虫管理和部署之使用
最 上 川
·
2023-10-14 11:53
scrapy
知道这几点,python爬虫技术简简单单轻松上手!
目录一、知识体系1、核心技术2、掌握工具3、Python模块二、学习阶段第一阶段:Python基础与爬虫第二阶段:
Scrapy
框架与实战三、正确爬虫1.个人信息2.商业信息3.国家信息 我之前有写过些爬虫的文章
程序猿-小菜
·
2023-10-14 01:33
python
爬虫
scrapy
爬虫框架之middlewares(中间件)与settings配置文件
DownloaderMiddleware下载中间件是一个钩子到
Scrapy
的请求/响应处理的框架。这是一个轻量级的、低级的系统,用于全局改变
Scrapy
的请求和响应。
阿无,
·
2023-10-13 20:07
爬虫
中间件
scrapy
爬虫
Python
scrapy
爬虫框架 常用setting配置
Python
scrapy
爬虫框架常用setting配置十分想念顺店杂可。。。降低log级别当进行通用爬取时,一般您所注意的仅仅是爬取的速率以及遇到的错误。
weixin_34334744
·
2023-10-13 20:06
浅谈
scrapy
去重机制
前言最近出现了两个问题url的参数或者post的数据中有随机值和签名,比如https://www.baidu.com?id=1&nonce=xxxxxxxx&sign=1232344https://www.baidu.com?id=1&nonce=sssssss&sign=2323124这两个链接其实是同一个,nonce只是个随机值,而sign也只是对id和nonce做了签名,但是这两个链接都会被
Qwertyuiop2016
·
2023-10-13 20:01
scrapy
scrapy
scrapy
针对302请求的处理与重试配置
不修改任何配置,
scrapy
针对302请求时如何处理的?
Jesse_Kyrie
·
2023-10-13 20:58
python爬虫综合
scrapy
爬虫
2019-01-14
Scrapy
爬虫之一:房产网站挂牌信息笔者有朋友计划把自己的一套房屋在中介门店挂牌出售。
DT数据说
·
2023-10-13 19:22
若依
框架学习
笔记
一、后端开发环境配置1.下载或拉取源码2.在idea中打开项目3.maveninstall相应包4.数据库配置二、目录结构与用途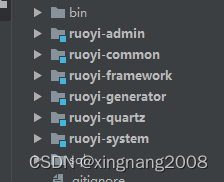三、开始配置1.配置数据库。ruoyi-admin-resources下application-druid.yml2
xingnang2008
·
2023-10-13 10:41
学习
笔记
Java
框架学习
:MyBatis之MyBatis入门、优化配置、Mapper映射文件
文章目录ORMMyBatis入门第一个MyBatis程序优化配置读取配置文件获取数据库连接的参数日志配置Mapper映射文件ORM对象关系映射(ObjectRelationalMapping,简称ORM)是通过使用描述对象和数据库之间映射的元数据,将面向对象语言程序中的对象自动持久化到关系数据库中。具体表现:O-Java对象R-数据库表M-映射文件一个Java类对应数据库中的一张表;一个Java对
weixin_45919908
·
2023-10-13 10:44
mybatis
java
打造高效的分布式爬虫系统:利用
Scrapy
框架实现
本文将介绍如何使用
Scrapy
框架来构建一个高效的分布式爬虫系统,以加速数据采集过程和提高系统的可扩展性。
qq^^614136809
·
2023-10-13 09:10
分布式
爬虫
scrapy
高级深入--day30
Scrapy
Shell
Scrapy
终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。
长袖格子衫
·
2023-10-13 03:51
python
开发语言
爬虫
scrapy
送书 |《Python网络爬虫框架
Scrapy
从入门到精通》
学爬虫,小编推荐《Python网络爬虫框架
Scrapy
从入门到精通》,文末查看送书规则~书籍简介本书从python主流框架
scrapy
的简介及网络爬虫知识讲起,逐步深入到
scrapy
进阶实战。
敲代码的灰太狼
·
2023-10-12 17:29
分布式
python
编程语言
大数据
人工智能
拼多多商品品牌数据接口,拼多多商品详情数据接口,拼多多优惠券数据接口,拼多多API接口
通过爬虫来自动获取,Python爬虫框架有很多,如
scrapy
,beautifulsoup等。您也可以通过第三方数据提供商来获取拼多多上的商品信
api_ok
·
2023-10-12 15:57
开发语言
php
大数据
前端
java
Python-
Scrapy
获取历史双色球开奖号码
Python-
Scrapy
获取历史双色球开奖号码文章目录1-创建项目2-settings文件设置3-Itrm设置4.创建Spider5-爬取规则的编写6-pipeline.py文件的编写7-爬取8-数据统计
羽丶千落
·
2023-10-12 14:12
Python学习
python
scrapy
外行学 Python 爬虫 第十篇 爬虫框架
Scrapy
在python中比较常用的爬虫框架有
Scrapy
和PySpider,今天针对S
keinYe
·
2023-10-12 09:00
python数据挖掘实验报告_Python数据挖掘实践—决策树
这几期和大家聊聊使用Python进行机器学习题外话:之前一期“
scrapy
抓取当当网82万册图书数据”的Github链接Python拥有强大的第三方库,使用Python进行科学计算和机器学习同样需要先配置运行环境
weixin_39828715
·
2023-10-12 08:18
python数据挖掘实验报告
2018-07-25
1.被誉为全世界高效的编程语言python库多有TensorFlow,Theano,scikit-learn,CognitiveToolkit,Keras2.数据获取方便有
Scrapy
,beautifulsoup
LR0811
·
2023-10-12 03:06
Scrapy
下载图片(下,图片中文字识别)
这里增加应用场景,让图片下载结合自动识别,实现识别转换图片中的电话号码。背景在爬取广西人才网的过程当中,发现广西人才网企业联系电话那里不是str,而是将电话生成了一张图片,遇到这种情况,通常有三种不同的处理办法:将图片地址保存下来,只存url将图片下载到本地,存储url和本地路径path将图片下载到本地,存储url和本地路径,然后用图片识别的方式将电话识别出来,赋给tel字段存入数据库图片文字识别
中乘风
·
2023-10-11 21:04
MySQL查询分组后前10条数据
在做去哪儿网数据分析时候被一个问题难倒了,之前通过
scrapy
将数据导入了MySQL,然后想分组查询MySQL数据库每个省份每个分组300条数据,但结果。。。
明日孤风寒
·
2023-10-11 15:43
【Spring
框架学习
2】DI 依赖注入
一、DI(依赖注入)介绍依赖注入(DependencyInjection,DI)是一种实现控制反转(InversionofControl,IoC)的方式。它允许将一个或多个依赖(即服务)注入到对象中(即客户端)。降低了对象与具体实现之间的耦合度,提高了代码的可维护性和可用性。在Spring框架中,依赖注入被广泛应用,例如:在Bean的配置中,可以通过构造函数、setter方法或者使用@Autowi
时间_wys
·
2023-10-11 15:07
spring
学习
【Spring
框架学习
3】Spring Bean的作用域 及 生命周期
一、SpringBean的作用域有哪些?Spring框架支持以下五种Bean的作用域:Singleton:这是默认的作用域,在每个SpringIoC容器中只有一个Bean的实例(IoC初始化后)。Spring中的bean默认都是单例的,是对单例设计模式的应用。Prototype:每次getBean()都会创建一个新的Bean实例。Request:每次HTTP请求都会产生一个新的Bean(请求Bea
时间_wys
·
2023-10-11 14:22
spring
学习
2019-01-15
Scrapy
爬虫与机器学习之三:房屋挂牌价格预测
Scrapy
爬虫与机器学习之三:房屋挂牌价格预测本文在前期抓取房产中介二手房某区域所有2453套房屋基础上,使用机器学习的线性回归模型进行预测朋友拟挂牌房屋的价格
DT数据说
·
2023-10-11 04:00
python 常用库收集
Scrapy
.如果你从事爬虫相关的工作,那么这个库也是必不可少的。用过它之后你就不会再想用别的同类库了。wxPython.Python的一个GUI(图形用户界面)工具。我主要用它替代tkinte
weixin_30402085
·
2023-10-11 04:00
测试
json
操作系统
Python常用的标准库以及第三方库
Scrapy
.如果你从事爬虫相关的
fengfengchen95
·
2023-10-11 04:27
Python
Python的常用库
Scrapy
.如果你从事爬虫相关的工作,那么这个库也是必不可少的。用过它之后你就不会再想用别的同类库了。wxPython.Python的一个GUI(图形用户界面)工具。我主要用它替代tkinte
donghe1900
·
2023-10-11 04:26
测试
json
操作系统
python爬虫
scrapy
框架无法生成csv文件是怎么回事_Python使用
Scrapy
框架爬取数据存入CSV文件(Python爬虫实战4)...
1.
Scrapy
框架
Scrapy
是python下实现爬虫功能的框架,能够将数据解析、数据处理、数据存储合为一体功能的爬虫框架。
weixin_39551366
·
2023-10-11 03:28
[Python爬虫]使用
Scrapy
框架爬取微博
Scrapy
框架爬取微博简介包
Scrapy
框架main.py(启动文件)setting.py(配置文件)pq.py(项目文件)话题小组模块模板图片模块用户模块视频模块(未找到视频接口)文章模块(未做)pipelines.py
Black_God1
·
2023-10-11 03:19
爬虫
python
微博
爬虫
爬取微博热榜并将其存储为csv文件
热爱技术,技术无罪欢迎关注点赞收藏⭐️留言获取源码,添加WX目录前言1.热榜前50爬虫最后前言基于大数据技术的社交媒体文本情绪分析系统设计与实现,首先需要解决的就是数据的问题,我打算利用Python语言的
Scrapy
秋名山码民
·
2023-10-11 03:18
大数据毕业设计闲聊
python
beautifulsoup
scrapy
hadoop
hive
大数据
Laravel框架的运行环境配置(一)
Laravel
框架学习
参考:官网:https://www.laraval.com/(https://www.laraval.com/)地址:http://laravelacademy.org/(http
蜜糖gtt
·
2023-10-10 21:01
13.
scrapy
入门
1、
scrapy
简介1、1网络爬虫网络爬虫是指在互联网上自动爬取网站内容信息的程序,也被称作网络蜘蛛或网络机器人。
天天501
·
2023-10-10 17:03
python爬虫实战教程
scrapy
Unity3d toLua#
框架学习
-- Function
toLua的第三个案例是关于如何在c#中调用Lua函数的一、LuaTable.GetLuaFunction()与LuaState.GetFunction()具体地调用方法如下:LuaTabletable=newLuaTable();LuaFunctionfunc=table.GetLuaFunction("Function_Name");LuaStatelua=newLuaState();LuaF
aos_2018
·
2023-10-10 16:12
unity
tolua
unity
c#
tolua
Unity热更新ToLua
框架学习
一、Lua语言学习二、ToLua框架三、使用ToLua框架对Lua&C#进行交互四、使用Lua对GameObj进行操作五、将游戏对象打包&解包六、将Lua脚本文件进行打包&解包七、热更新实践八、使用服务器进行热更新一、Lua语言学习Lua是很轻量级的脚本语言,Table也是个很神奇的东西,前面刚开始看的时候以为是Python(╯▔皿▔)╯废话不多说,是菜鸟就点进去吧Lua菜鸟教程二、ToLua框架
MadProMonkey
·
2023-10-10 16:03
ToLua
python asyncio 高并发_python链家网高并发异步爬虫asyncio+aiohttp+aiomysql异步存入数据...
IO爬虫,使用asyncio、aiohttp和aiomysql很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests、urllib这些同步的库进行单线程爬虫,速度是比较慢的,后学会用
scrapy
weixin_36416921
·
2023-10-10 12:27
python
asyncio
高并发
scrapy
学习03--异步aiohttp练习
#学习aiohttp#第一步安装#pipinstallaiohttp-ihttps://pypi.douban.com/simple#pipinstallcchardet-ihttps://pypi.douban.com/simple#客户端importaiohttpimportasyncioasyncdeffetch(session,url):asyncwithsession.get(url)a
我永远喜欢希露菲叶特
·
2023-10-10 12:56
学习记录
python
网络爬虫(九)
Day08回顾
scrapy
框架五大组件引擎(Engine)爬虫程序(Spider)调度器(Scheduler)下载器(Downloader)管道文件(Pipeline)#两个中间件下载器中间件(DownloaderMiddlewares
南坡三舅
·
2023-10-10 12:17
Scrapy
学习笔记(一)——使用Pycharm搭建编写
Scrapy
项目的环境
写在前面:Python版本:3.6.1Pycharm版本:2018.1.4第一步:命令行构建
Scrapy
项目Pycharm中没有直接构建
Scrapy
项目的模板和指令,所以需要自行在命令行中通过指令进行项目的创建
DivingKitten
·
2023-10-10 11:32
Env
Python
pycharm中
scrapy
框架安装
首先确保pycharm能正常使用(安装环境为win10pycharm2019.3.3、python3.6.8)用pycharm安装
scrapy
框架很便捷只要你的pycharm配置好就能直接一键安装
scrapy
D.....
·
2023-10-10 11:32
pycharm
python
windows 搭建python 虚拟环境 写程序_python之搭建
scrapy
虚拟环境(Windows版)
这篇文章主要介绍了python之搭建
scrapy
虚拟环境(Windows版),小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧。
weixin_39942488
·
2023-10-10 11:01
windows
搭建python
虚拟环境
写程序
在pycharm中调试运行
scrapy
在各种试,试各种后,只有这种方法,我做到了遭pycharm下运行调试
scrapy
:过程有点复杂边看视频边写:一、首先:搭建虚拟环境1、安装:在需要安装虚拟环境的目录下的cmd中输入:pipinstallvirtualenv
bobbykey
·
2023-10-10 11:31
scrapy
pycharm
在pycharm中搭建
scrapy
的框架
文章目录前言使用步骤1.引入库2.读入数据前言
scrapy
框架的构建使用步骤1.引入库首先下载
scrapy
库如果下载显示pip等级过低,需要升级一下pippipinstall
scrapy
2.搭建
scrapy
贝贝啊啊啊啊啊啊啊啊
·
2023-10-10 11:31
pycharm
python
上一页
18
19
20
21
22
23
24
25
下一页
按字母分类:
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
P
Q
R
S
T
U
V
W
X
Y
Z
其他