Scrapy学习笔记(一)——使用Pycharm搭建编写Scrapy项目的环境
写在前面:
Python版本:3.6.1
Pycharm版本:2018.1.4
第一步:命令行构建Scrapy项目
Pycharm中没有直接构建Scrapy项目的模板和指令,所以需要自行在命令行中通过指令进行项目的创建。
格式: scrapy [指令] [项目名]
eg:
scrapy startproject [project]第二步:使用Pycharm打开项目并配置编译环境
项目创建完成后,便可以通过Pycharm打开,此时对于该项目Pycharm为查找到对应的编译运行环境,需要手动配置。
点击:File->Settings->Project->Project:interpreter,在此处可以通过点击右上角的齿轮标志,创建该项目新的虚拟环境。

在创建项目环境时,可以将全局环境中的包同时导入到项目环境,也可以重新导入对应的包。若不导入全局的包,则通过pip指令重新导入有关的包。
pip install Scrapy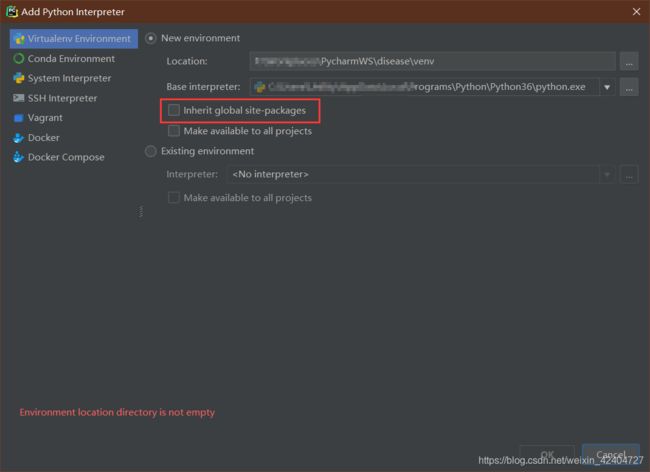
第三步:创建项目启动脚本
项目的编译环境配置完成后,接下来继续配置爬虫启动文件。在编写启动文件前,先通过指令建立一个爬虫文件,新建的爬虫文件会自动保存在spiders目录下。
scrapy genspider baidu www.baidu.com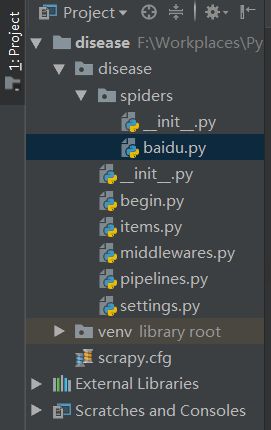
根据basic模板建立爬虫文件以后,就可以编写启动文件了,在根目录下创建一个begin.py文件
# -*- coding: utf-8 -*-
# @Time : 2019/1/18 17:10
# @File : begin.py
# @Software: PyCharm
# @Desc : 配置Pycharm的启动Scrapy项目的启动文件
from scrapy import cmdline
cmdline.execute("scrapy crawl baidu".split())begin.py文件即是一个项目的执行脚本文件,内容即每次在启动爬虫项目所需要在终端输入的指令,此处的execute()方法中需要传入的是一个List类型,而非一个完整命令的字符串。然后,即可在Pycharm中进行配置,点击:Run->Edit Configurations..,添加一个python的启动项,并找到刚刚编写的begin.py文件即可。
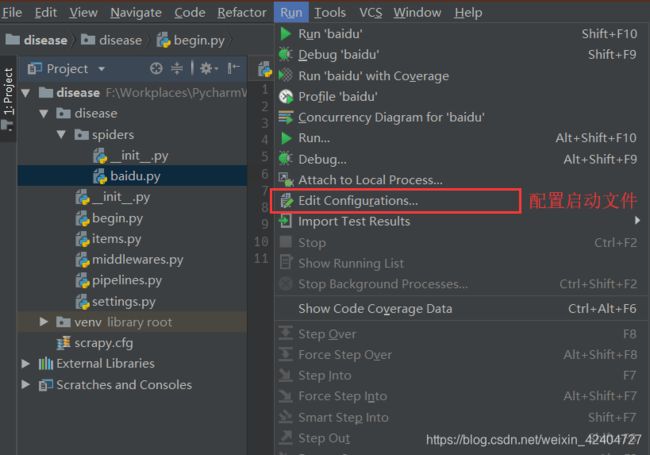
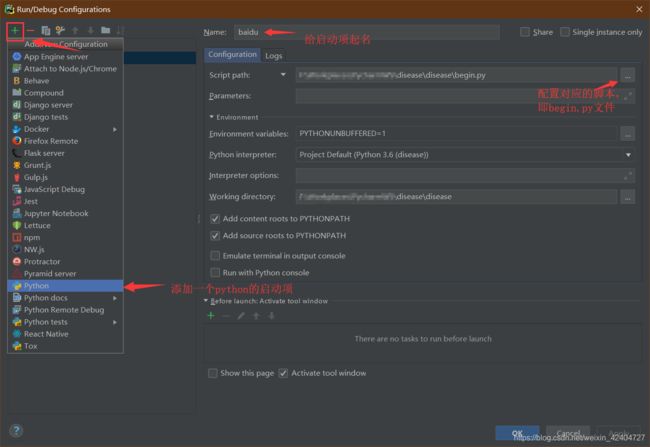
配置完成后,能够在Pycharm右上角看到对应的便捷启动项,这样就一个简单的配置就完成了。

第四步:启动脚本,分析结果
启动脚本能够看到对应的输出。(这里由于百度的robots.txt文件禁止了爬虫爬取,所以得到返回数据)

写在最后:
到此使用Pycharm编写Scrapy项目所需要进行的一些配置就都已经完成了,这个演示项目是极其简陋的,比如:最后启动爬虫直接就被爬虫服务器禁止了,这里也说明了Scrapy框架默认是遵从robots协议的,当然我们能够通过伪装技术,绕过robots协议的规定进行信息的爬取,不过还是在此呼吁爬虫编写的时候多考虑服务器的压力,不给往网站造成不必要的压力。