《算法图解》学习笔记(三):递归和栈(附代码)
python学习之路 - 从入门到精通到大师
文章目录
- [python学习之路 - 从入门到精通到大师](https://blog.csdn.net/TeFuirnever/article/details/90017382)
- 一、递归
- 二、基线条件和递归条件
- 三、栈
- 1)调用栈
- 2)递归调用栈
- 四、总结
- 参考文章
递归——一种优雅的问题解决方法,定义是 在运行过程中调用自己。它将人分成三个截然不同的阵营:恨它的、爱它的以及恨了几年后又爱上它的,一般都是第一个,哈哈,就是这么真实。
一、递归
看一个例子,假设你在祖母的阁楼中翻箱倒柜,发现了一个上锁的神秘手提箱。

祖母告诉你,钥匙很可能在下面这个盒子里。

这个盒子里有盒子,而盒子里的盒子又有盒子。但是已经确定的是钥匙就在某个盒子中。为找到钥匙,你将使用什么算法?
方法一:
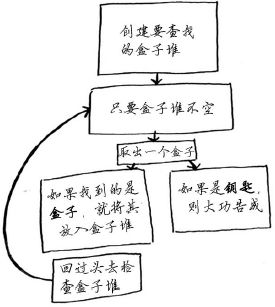
(1) 创建一个要查找的盒子堆。
(2) 从盒子堆取出一个盒子,在里面找。
(3) 如果找到的是盒子,就将其加入盒子堆中,以便以后再查找。
(4) 如果找到钥匙,则大功告成!
(5) 回到第二步。
方法二:

(1) 检查盒子中的每样东西。
(2) 如果是盒子,就回到第一步。
(3) 如果是钥匙,就大功告成!
这两种方法哪一个更容易呢?
- 第一种方法使用的是while循环:只要盒子堆不空,就从中取一个盒子,并在其中仔细查找。伪代码如下:
def look_for_key(main_box):
pile = main_box.make_a_pile_to_look_through()
while pile is not empty:
box = pile.grab_a_box()
for item in box:
if item.is_a_box():
pile.append(item)
elif item.is_a_key():
print("found the key!")
- 第二种方法使用递归——函数调用自己。伪代码如下:
def look_for_key(box):
for item in box:
if item.is_a_box():
look_for_key(item)
elif item.is_a_key():
print("found the key!")
这两种方法的作用相同,实现的功能也是相同的。但第二种方法,即递归,要更清晰一些。递归只是让解决方案更清晰,并没有性能上的优势。 实际上,在有些情况下,使用循环的性能更好。但是 Leigh Caldwell 在 Stack Overflow 上说的一句话:“如果使用循环,程序的性能可能更高;如果使用递归,程序可能更容易理解。如何选择要看什么对你来说更重要。”
很多算法都使用了递归,因此理解这种概念很重要。
二、基线条件和递归条件
由于递归函数调用自己,因此编写这样的函数时很容易出错,进而导致无限循环。例如,假设你要编写一个像下面这样倒计时的函数。
> 3...2...1
为此,你可以用递归的方式编写,如下所示。
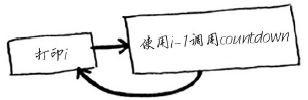
def countdown(i):
print(i)
countdown(i-1)
print(countdown(2))
如果你运行上述代码,将发现一个问题:这个函数运行起来没完没了!!!这谁顶得住啊,多跑一会,估计你的电脑直接死机。。。哈哈
不过pycharm上会自动停止的
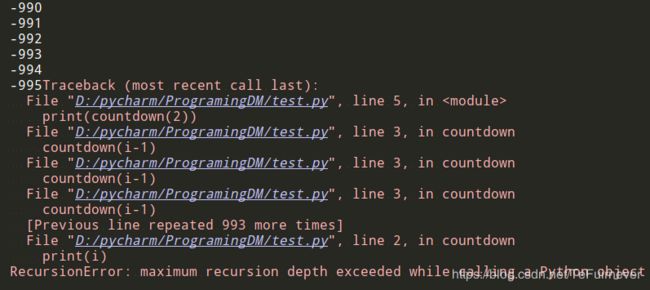
> 3...2...1...0...-1...-2...
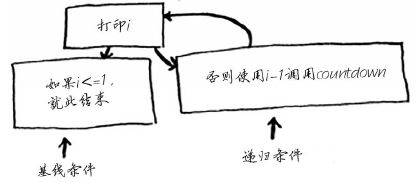
编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函数都有两部分:基线条件(base case) 和 递归条件(recursive case)。递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己,从而避免形成无限循环。基线条件很重要!基线条件很重要!!基线条件很重要!!!重要的事情说三遍。
我们来给函数countdown添加基线条件。
python版本代码如下:
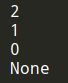
def countdown(i):
print(i)
# 基本的情况
if i <= 0:
return
# 递归的情况
else:
countdown(i-1)
print(countdown(2))
c++版本代码如下:
#include 现在,这个函数将像预期的那样运行,如下所示。
三、栈
下面将介绍一个重要的编程概念——调用栈(call stack)。调用栈最经常被用于 存放子程序的返回地址。在递归程序中,每一层次递归都必须在调用栈上增加一条地址,因此如果程序出现无限递归(或仅仅是过多的递归层次),调用栈就会产生栈溢出。调用栈不仅对编程来说很重要,使用递归时也必须理解这个概念。
还是举一个例子,假设你去野外烧烤,并为此创建了一个待办事项清单——一叠便条。

本书之前讨论数组和链表时,也有一个待办事项清单。

你可将待办事项添加到该清单的任何地方,还可删除任何一个待办事项。一叠便条要简单得多:插入的待办事项放在清单的最前面;读取待办事项时,你只读取最上面的那个,并将其删除。因此这个待办事项清单只有两种操作:压入(插入) 和 弹出(删除并读取)。
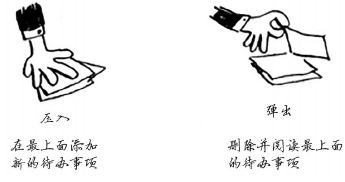
下面来看看如何使用这个待办事项清单。
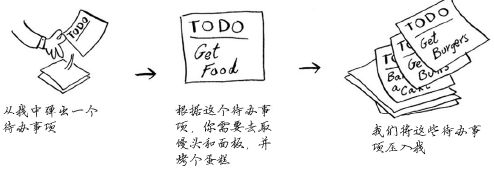
这种数据结构称为 栈。栈 是一种简单的数据结构,刚才我们一直在使用它,却没有意识到!
1)调用栈
计算机在内部使用被称为 调用栈的栈。来看看计算机是如何使用调用栈的。下面是一个简单的函数:
python版本代码如下:
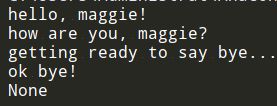
def greet(name):
print("hello, " + name + "!")
greet2(name)
print("getting ready to say bye...")
bye()
def greet2(name):
print("how are you, " + name + "?")
def bye():
print("ok bye!")
print(greet("maggie"))
c++版本代码如下:
#include 下面我们来分析一下程序:
假设你调用 greet("maggie") ,计算机将首先为该函数调用分配一块内存。

我们来使用这些内存。变量 name 被设置为 maggie,这需要存储到内存中。

每当你调用函数时,计算机都像这样将函数调用涉及的所有变量的值存储到内存中。接下来,你打印 hello, maggie!,再调用greet2("maggie")。同样,计算机也为这个函数调用分配一块内存。
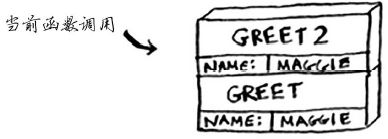
计算机使用一个栈来表示这些内存块,其中第二个内存块位于第一个内存块上面。你打印 how are you, maggie?,然后从函数调用返回。此时,栈顶的内存块被弹出。
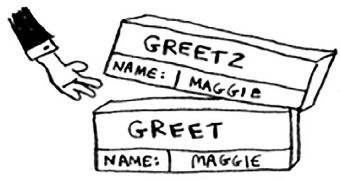
现在,栈顶的内存块是函数 greet 的,这意味着你返回到了函数 greet。当你调用函数 greet2 时,函数 greet 只执行了一部分。这是本节的一个重要概念:调用另一个函数时,当前函数暂停并处于未完成状态。 该函数的所有变量的值都还在内存中。执行完函数 greet2 后,你回到函数 greet ,并从离开的地方开始接着往下执行:首先打印 getting ready to say bye…,再调用函数 bye。

在栈顶添加了函数 bye 的内存块。然后,你打印 ok bye!,并从这个函数返回。

现在你又回到了函数 greet。由于没有别的事情要做,你就从函数 greet返回。这个栈用于存储多个函数的变量,被称为 调用栈。
2)递归调用栈
递归函数也使用 调用栈!来看看递归函数 factorial 的调用栈。factorial(5) 写作 5!,其定义如下:5! = 5 * 4 * 3 * 2 * 1。同理,factorial(3)为3 * 2 * 1。下面是计算阶乘的递归函数:
python版本代码如下:
def fact(x):
if x == 1:
return 1
else:
return x * fact(x-1)
print(fact(3))
![]()
c++版本代码如下:
#include 下面来详细分析调用 fact(3) 时调用栈是如何变化的。别忘了,栈顶的方框指出了当前执行到了什么地方。



注意,每个 fact 调用都有自己的 x 变量。在一个函数调用中不能访问另一个的 x 变量。栈 在 递归 中扮演着重要角色。不知道你还记不记得在开头的例子中,有两种寻找钥匙的方法。下面我们再次回头去列出了第一种方法。
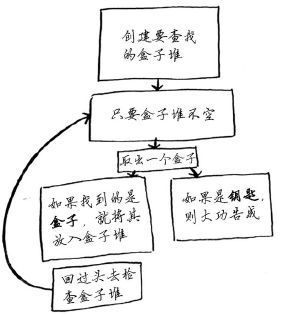
使用这种方法时,你创建一个待查找的盒子堆,因此你始终知道还有哪些盒子需要查找。

但使用递归方法时,没有盒子堆。
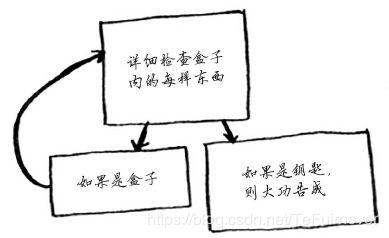
既然没有盒子堆,那算法怎么知道还有哪些盒子需要查找呢?下面是一个例子。

此时,调用栈类似于下面这样。
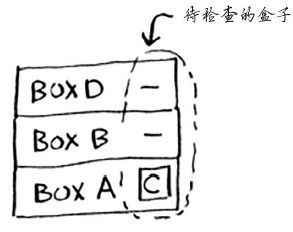
原来“盒子堆”存储在了栈中!这个栈包含未完成的函数调用,每个函数调用都包含还未检查完的盒子。使用栈很方便,因为你无需自己跟踪盒子堆——栈替你这样做了。
使用栈虽然很方便,但是也要付出代价:存储详尽的信息可能占用大量的内存。每个函数调用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。在这种情况下,你有两种选择:
- 重新编写代码,转而使用循环。
- 使用尾递归。这是一个高级递归主题,而且并非所有的语言都支持尾递归。
PS:
调用栈的主要功能是 存放返回地址。除此之外,调用栈还用于存放:
- 本地变量:子程序的变量可以存入调用栈,这样可以达到不同子程序间变量分离开的作用。
- 参数传递:如果寄存器不足以容纳子程序的参数,可以在调用栈上存入参数。
四、总结
- 递归指的是调用自己的函数。
- 每个递归函数都有两个条件:基线条件和递归条件。
- 栈有两种操作:压入和弹出。
- 所有函数调用都进入调用栈。
- 调用栈可能很长,这将占用大量的内存。
参考文章
- 《算法图解》
- 百度百科——调用栈